I’ve been trying to get replication going for days. Mostly routing and vpn issues in addition to KVM networking issues. I digress.
Brief description of the problem
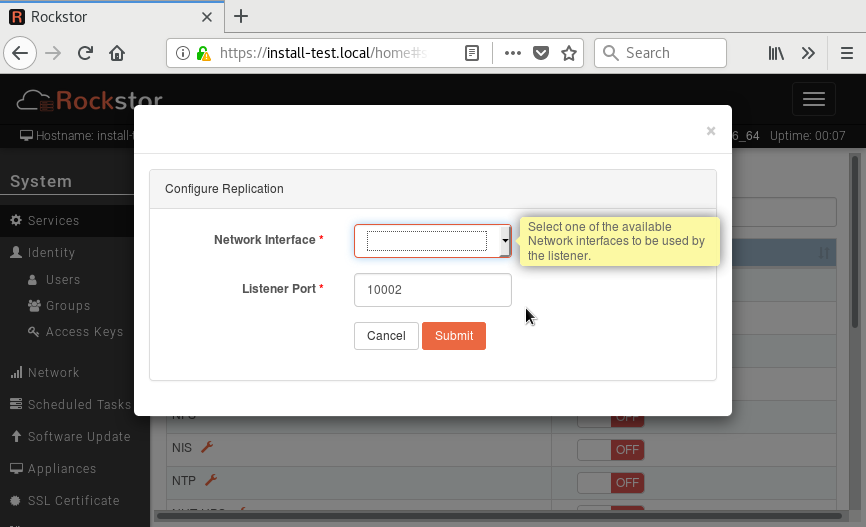
Attempting to enable replication service in the gui. The gui error is, "Configuration undefined. Configure the service first before starting. " This is the replication service. There is nothing to configure in the GUI, it’s either on or off.
Detailed step by step instructions to reproduce the problem
change the position of the switch in the gui
Web-UI screenshot
Well this form doesn’t really do images too well. drag and drop didn’t work at all. all that was in the screenshot was the traceback pasted below
Error Traceback provided on the Web-UI
[
Traceback (most recent call last):
File “/opt/rockstor/src/rockstor/smart_manager/views/replication_service.py”, line 64, in post
config = self._get_config(service)
File “/opt/rockstor/src/rockstor/smart_manager/views/base_service.py”, line 40, in _get_config
return json.loads(service.config)
File “/usr/lib64/python2.7/json/init.py”, line 338, in loads
return _default_decoder.decode(s)
File “/usr/lib64/python2.7/json/decoder.py”, line 366, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
TypeError: expected string or buffer
Most of the Rockstor services are configured this way.
We definitely need to improve our “Configure the service first before starting.” message to indicate this spanner location and I have opened the following issue to address this:
I did notice these usability issues when I last did a stint on the replication code and made some notes to address them but unfortunately didn’t get as far as making the required issues.
Thanks for the prompt on these outstanding issues.
Please note that you will currently require at least Rockstor release 3.9.2-13 (stable updates channel) for replication to work as we had a rather disruptive but necessary change to our api url’s prior to that version that effectively disabled replication for a while.
Yep, that got it. A little Schizophrenic having to enable the service in 2 places. Major feature request coming about replication and data retention. You folks are on to something, but it could be a lot better.
Still having trouble at the receiving end. I’m getting:
[07/May/2018 15:15:05] ERROR [smart_manager.replication.sender:74] Id: a8c01e64-0d7ca8c8-9a90-473a-b1a6-0a06de5df661-4. unexpected reply(receiver-error) for a8c01e64-0d7ca8c8-9a90-473a-b1a6-0a06de5df661-4. extended reply: Failed to validate the source share(Scans) on sender(uuid: a8c01e64-0d7ca8c8-9a90-473a-b1a6-0a06de5df661 ) Did the ip of the sender change?. Exception: [u’Invalid api end point: https://192.168.192.10:443/api/shares/Scans’]. Aborting. Exception: unexpected reply(receiver-error) for a8c01e64-0d7ca8c8-9a90-473a-b1a6-0a06de5df661-4. extended reply: Failed to validate the source share(Scans) on sender(uuid: a8c01e64-0d7ca8c8-9a90-473a-b1a6-0a06de5df661 ) Did the ip of the sender change?. Exception: [u’Invalid api end point: https://192.168.192.10:443/api/shares/Scans’]. Aborting
This message may be due to one of the machines being pre version 3.9.2-13. Both machines are required to be at least 3.9.2-13 as that is when the api url chnage fix for replication was added. If you could first confirm that both machines are in fact this version or later just in case that is the cause (very much looks like it as we use database id rather than share names now).
Also note we have another rather tricky (chicken and egg) bug still in testing channel, now fixed in stable, that mean when you first subscribe to the stable it will indicate you have the latest stable when in fact you are yet to upgrade to any stable version. It ended up showing the latest available stable as the installed version.
If you do a:
yum info rockstor
it should indicate if you have this, in which case you will have to do a:
yum update rockstor
and from there on the installed and available are corrected, ie see the following issue:
Still working this out. the versions now match (3.9.2-23 Stable updates), I plunked down the extra 20 to hook up my test vm. going to have to make sure I get snapshots of that.
However, I’ve rebooted both the virtual machine since the update and the physical server. We are communicating over a VPN. Currently trying to send from the virtual to the physical. Now we are getting an api error. I’m sure it’s not supposed to be this difficult. Could this have happened because we were on unstable updates and then reverted to stable? Remember, this is a test machine. Should I just blow it away and start over with an new UUID?
[07/May/2018 22:17:01] ERROR [smart_manager.replication.sender:73] Id: 11A97B08-37C0-4E74-98F7-E5A509BE5AD1-2. Failed to create snapshot: Scan_2_replication_1. Aborting… Exception: [u’Invalid api end point: http://127.0.0.1:8000/api/shares/Scan/snapshots/Scan_2_replication_1’]
[07/May/2018 22:29:02] ERROR [smart_manager.replication.sender:73] Id: 11A97B08-37C0-4E74-98F7-E5A509BE5AD1-2. Failed to create snapshot: Scan_2_replication_1. Aborting… Exception: [u’Invalid api end point: http://127.0.0.1:8000/api/shares/Scan/snapshots/Scan_2_replication_1’]
Great, but do take a close look at my last post re confirming the actual, rather than just displayed (within Web-UI), Rockstor versions. Pretty sure you are still running old code on at least one machine due to the Invalid api end point message.
Once you have confirmed, via command line, the actual installed Rockstor version on both machines we can take it from there as this still looks exactly like old code affected by the api change replication bug.
Thanks for helping to support Rockstor’s development and apologies for the inconvenience re versions and the ‘false’ stable update version report but there are many moving parts and this one, unfortunately, was rather harsh on us. Prior to submitting my last replication related pull request / fix I did test the whole thing over several hundred iterations (5 needed for it to settle to it’s final / ongoing state) so it can work but there are still known fragile elements that will be addressed in time. But your logs don’t seem to relate to newer code.
You can transfer a subscription from one machine to another but it currently takes an email request so not ideal just yet. But there are plans to make this ‘self service’ in the future.
Thanks for persevering but I think it’s worth it as there are very many fixes / additions from last released testing to current stable, one of which is the ability to disable/re-enable quotas so that’s another Web-UI visual indicator that you are running new code:
Hope that helps and thanks for persevering. I’m afraid I didn’t pick up on this old code issue earlier as I had assumed your:
comment meant you were already up and running.
I think we should probably do a sticky forum post with this update version bug: I’ll get to it soon.
Bit overkill and inconvenient re the stable subscription. Unless the machines are stable underneath which is less likely the case with a VM. But a clean start re replication is worth a try, once both machines are confirmed on new code. That is remove the existing replication task at both ends and all associated snapshots (names should give them away) and then create a fresh rep task. Essentially a nuke and pave but just for replication as each new task sets everything up for itself fresh, with differently named snapshots etc based on the database id of that task.
Let us know how you get on. I’ll get to improve the docs on this hopefully soon but everything takes time and there never seems to be enough to go around. Oh well.
OK, got this solved. The GUI was reporting the incorrect version. yum update rockstor and a restart. Then deleted all replication snapshots and snapshot jobs and started over on the replication. ran two successfull jobs and have set up automoated replication on a relatively accelerated schedule tost.
Note that it will take 5 (from memory) successive replication tasks for thing to settle down into their final state. I’m due to do a technical wiki entry on the underlying mechanisms that dictate this behaviour. Also I have an as yet unpublished / yet to be submitted code improvement to the mount and clone code that re-uses newer / more robust code used by the replication task and in turn improves / simplifies that code a tad also. So all on the move but again, down to time available as I need a little more to do final testing before submitting that pull request.
Glad you are up and running. But there are still known fragile elements to the replication but if you enable email notifications you should at least receive notification of any failure. Usually the first task to fail has the most informative entry (via rep task table tooltip / log entries) and usually just requires the deletion of the most recent snapshot: see the following forum thread/post where this was mentioned earlier: