Brief description of the problem
Inability to delete ‘unmounted’ shares
Detailed step by step instructions to reproduce the problem
Created replication, however it failed due to network interrupt. Deleted main share ok. Sub share (.snapshot/filename…) refuses to be deleted (force delete no good) and now shows ‘unmounted’ in the status column.
There is no record of this ‘snapshot’ in the snapshots table.
Web-UI screenshot
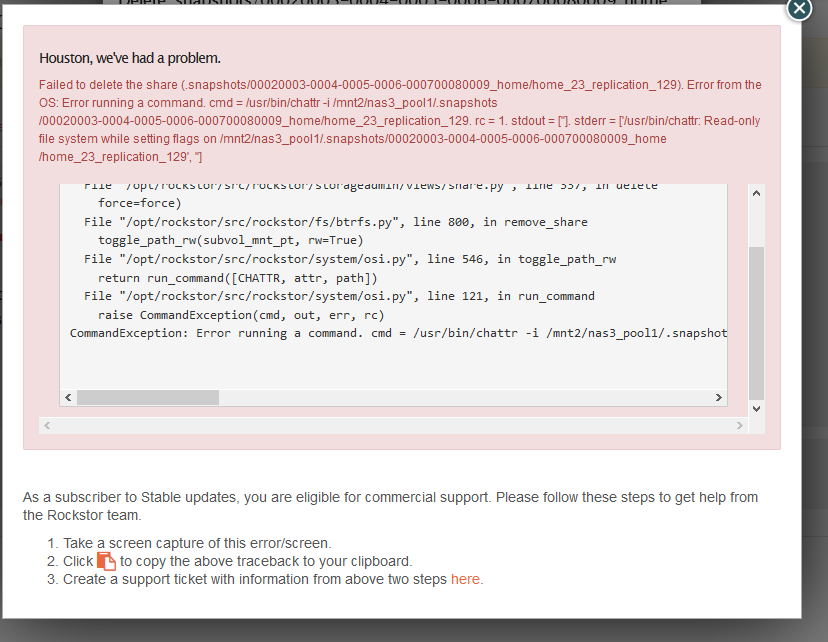
Error Traceback provided on the Web-UI
Traceback (most recent call last):
File “/opt/rockstor/src/rockstor/storageadmin/views/share.py”, line 337, in delete
force=force)
File “/opt/rockstor/src/rockstor/fs/btrfs.py”, line 800, in remove_share
toggle_path_rw(subvol_mnt_pt, rw=True)
File “/opt/rockstor/src/rockstor/system/osi.py”, line 546, in toggle_path_rw
return run_command([CHATTR, attr, path])
File “/opt/rockstor/src/rockstor/system/osi.py”, line 121, in run_command
raise CommandException(cmd, out, err, rc)
CommandException: Error running a command. cmd = /usr/bin/chattr -i /mnt2/nas3_pool1/.snapshots/00020003-0004-0005-0006-000700080009_home/home_23_replication_129. rc = 1. stdout = [‘’]. stderr = [‘/usr/bin/chattr: Read-only file system while setting flags on /mnt2/nas3_pool1/.snapshots/00020003-0004-0005-0006-000700080009_home/home_23_replication_129’, ‘’]
Have tried deletion via console as well but just says ‘read only’.
Hoping this isn’t a major problem as to get replication working has been a time consuming thing.
Many thanks
Paul