My box experienced an unexpected shutdown during the execution of a scrub, and I am now unable to schedule further scrubs or cancel the currently “running” one through the webui.
The box is running 3.8.16-8, but I believe the problem originated when it was running an older version. The problem has persisted across restarts and upgrades.
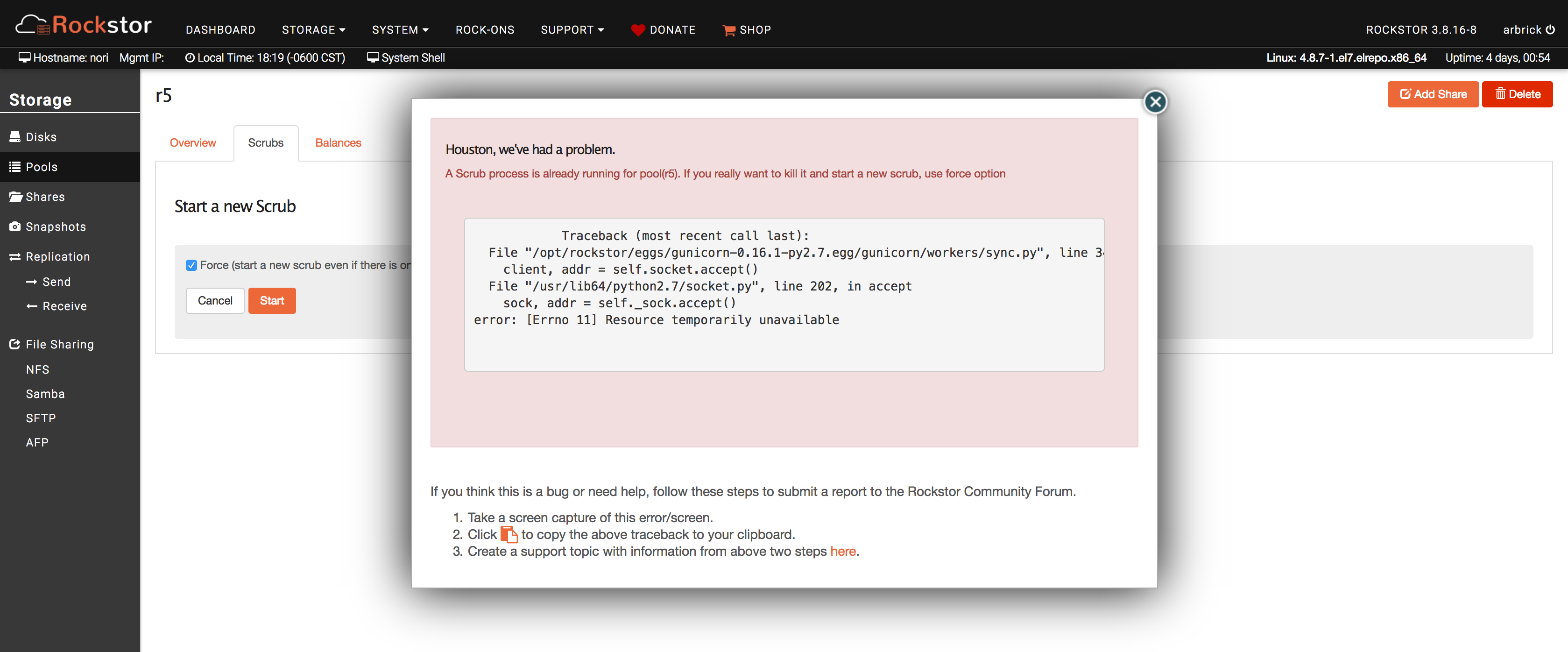
Traceback (most recent call last):
File "/opt/rockstor/eggs/gunicorn-0.16.1-py2.7.egg/gunicorn/workers/sync.py", line 34, in run
client, addr = self.socket.accept()
File "/usr/lib64/python2.7/socket.py", line 202, in accept
sock, addr = self._sock.accept()
error: [Errno 11] Resource temporarily unavailable
[root@nori ~]# btrfs fi show
Label: 'rockstor_rockstor' uuid: 8c05e66d-f6ec-4421-b7ab-515b7c25726b
Total devices 1 FS bytes used 1.75GiB
devid 1 size 107.68GiB used 8.02GiB path /dev/sda3
Label: 'r5' uuid: faf152cc-5d4a-48f5-895d-e68c5c7bf707
Total devices 3 FS bytes used 2.21TiB
devid 1 size 2.73TiB used 1.12TiB path /dev/sdb
devid 2 size 2.73TiB used 1.12TiB path /dev/sdd
devid 3 size 2.73TiB used 1.12TiB path /dev/sdc
[root@nori ~]# btrfs balance status /mnt2/r5
No balance found on '/mnt2/r5'