mhm, again reaching the end of my knowledge here. I know based on some of your reporting on resizing something was done on the quotas, but I suspect no fundamental changes recently … I’ll think some more on it
@Hooverdan Thanks for detailed exposition here. Nice.
Re:
This has definitely helped to narrow down what’s going on. The strangly named early shares are a know artefact of the first 3 replication events however. There-after it is suplanted (promoted).
But I do see a difference here re the failure report:
Quotas enabled:
Receiving machine: which is where the failure appears:
I.e. a quote problem, hence you further investigation and disabling quotes.
Quotas disabled
Receiving machine again:
which looks different, and likely the difference is informative for us.
As an initial guess the former may be down to a quota change we made, can’t think of anything else currently, and the later could be a btrfs change: especially given you are running Tumbleweed on the receiver. I.e. not the -f advice. And given we no longer use the as the send/receive difference target, the reason we use a cascade of snapshots, should mean we can safely use this -f option, which we have never required before. Take a peek and see if you can jury-rig a -f in there for the proof of function with target (destination) Supplanting process. That at least leaves only the initial quotas blocker.
@Stevek Thanks for your continued endeavour on this one, as always much appreciated. This would be a great find if we can get to the bottom on it. We are still in testing, if late, so it would be great to see this functional, as earlier in the testing phase. We do juggle several moving targets here so always a challenge. But this type of contirbution is super usefull to highlight these issues. The Quota strangeness you saw looks tallies with @Hooverdan finding regarding a new quota sensitivity. Try disabling quotas via Web-UI then re-enabling them: they can take a few minutes to re-calculate the share usage after re-enabling. If Web-UI disable/reenable failes, try via the command line: it’s a Pool level thing.
Thanks folks, we do have some concrete info here now, so all good. Not observed after last replication maintenance but definitely exists now !!!
Hope that helps.
@Hooverdan my apologies if I’ve mis-quoted your logs there. But it does looks different after quota disabled on target (receive) end: it just fails a little later on. The two could be related however. I.e. quota change blocked by way of protection against the sort of thing we want to do later as well: that the snapshot is know be associated with a replication: but we no longer use the older/oldest snapshots, only the most recent: then cascade the orphaned oldest snapshot to being a real Share (cosmetic actually as all snapshots, shares, clones, and subvols). That cascade mechanism was intended to divorce that receiving snapshot from the replication process. But it looks like we may need a little tweak re newer btrfs.
2 Likes
Thanks for providing your thoughts on this. I did notice that difference, but assumed that, while a symptom of something not working, it wasn’t at the core of failure after the third replication (or at least I think so).
I added the force flag in btrfs.py on the receiver side here:
def set_property(mnt_pt, name, val, mount=True):
if mount is not True or is_mounted(mnt_pt):
cmd = [BTRFS, "property", "set", mnt_pt, name, val]
return run_command(cmd)
like this:
def set_property(mnt_pt, name, val, mount=True):
if mount is not True or is_mounted(mnt_pt):
cmd = [BTRFS, "property", "set -f", mnt_pt, name, val]
return run_command(cmd)
but that provided an error unfortunately. Interestingly, when I copied the command string printed in the error log exactly how it was captured, it worked, so not sure what happened. I will try again differently
Hah, my lack of python development experience shows. I made a slight change in the coding to:
def set_property(mnt_pt, name, val, mount=True):
if mount is not True or is_mounted(mnt_pt):
cmd = [BTRFS, "property", "set", "-f", mnt_pt, name, val]
return run_command(cmd)
and I now have 5 successful replications and counting!
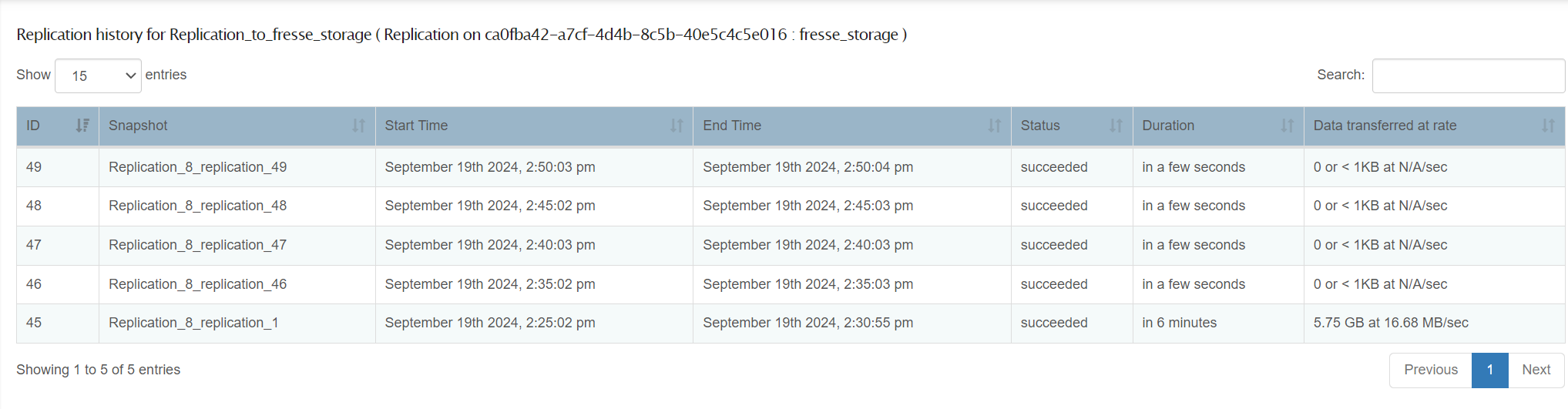
And as I found somewhere else in the replication coding, only the last three snapshots are kept:

This was all with quotas disabled on the receiving system:
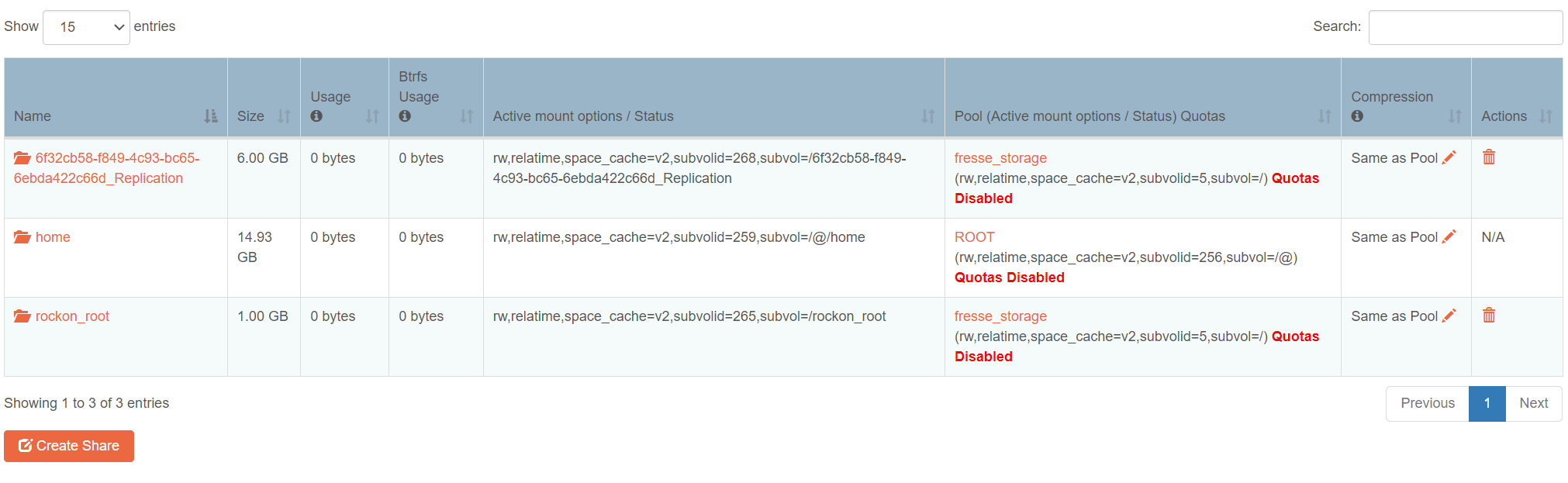
Turning them on after the fifth replication, led to a failure of promoting the oldest share to primary. This is in line (unfortunately) with the errors described earlier in this thread where the system struggles with deleting the quota groups (qgroups):
[19/Sep/2024 14:55:03] INFO [storageadmin.views.snapshot:61] Supplanting share ( 6f32cb58-f849-4c93-bc65-6ebda422c66d_Replication) with snapshot (Replication_8_r eplication_47).
[19/Sep/2024 14:55:03] ERROR [system.osi:287] non-zero code(1) returned by comma nd: ['/usr/sbin/btrfs', 'qgroup', 'destroy', '0/268', '/mnt2/fresse_storage']. o utput: [''] error: ['ERROR: unable to destroy quota group: Device or resource bu sy', '']
[19/Sep/2024 14:55:03] ERROR [storageadmin.util:44] Exception: Error running a c ommand. cmd = /usr/sbin/btrfs qgroup destroy 0/268 /mnt2/fresse_storage. rc = 1. stdout = ['']. stderr = ['ERROR: unable to destroy quota group: Device or resou rce busy', '']
Traceback (most recent call last):
File "/opt/rockstor/src/rockstor/storageadmin/views/clone_helpers.py", line 92 , in create_repclone
remove_share(share.pool, share.name, PQGROUP_DEFAULT)
File "/opt/rockstor/src/rockstor/fs/btrfs.py", line 1196, in remove_share
qgroup_destroy(qgroup, root_pool_mnt)
File "/opt/rockstor/src/rockstor/fs/btrfs.py", line 1501, in qgroup_destroy
return run_command([BTRFS, "qgroup", "destroy", qid, mnt_pt], log=True)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/rockstor/src/rockstor/system/osi.py", line 289, in run_command
raise CommandException(cmd, out, err, rc)
system.exceptions.CommandException: Error running a command. cmd = /usr/sbin/btr fs qgroup destroy 0/268 /mnt2/fresse_storage. rc = 1. stdout = ['']. stderr = [' ERROR: unable to destroy quota group: Device or resource busy', '']
[19/Sep/2024 14:55:03] ERROR [smart_manager.replication.receiver:100] b'Failed t o promote the oldest Snapshot to Share.'. Exception: 500 Server Error: Internal Server Error for url: http://127.0.0.1:8000/api/shares/25/snapshots/Replication_ 8_replication_47/repclone
So, apparently two root causes that were masking each other.
3 Likes
@phillxnet @Hooverdan WWOOOOWWWW you guys are amazing…
Let me know when u have a fix and i’ll test it. I run from the testing channel.
A couple of questions
Again why the need to do the 3 reps before seeing data?
If I have an existing share on both machines because I manually made a copy from windows is there a way to start replicating those same shares? In other words I have a share named photos on both machines and I want the second machine to always be in sync with the first. Do I need to delete the share on receiving machine to use replicate? Is there a better way of doing this?
2 Likes
I am not aware of a way to leverage that existing copy as part of the btrfs send/receive. The btrfs manpage states here:
You must not specify clone sources unless you guarantee that these snapshots are exactly in the same state on both sides—both for the sender and the receiver. For implications of changed read-write status of a received snapshot please see section SUBVOLUME FLAGS in btrfs-subvolume(8).
This really means not only the files have to exactly match, but all the stuff in the “btrfs sense”, subvolume layout, checksums, etc.
If you wanted to leverage the copies then I think something like rsync or other file level sync/backup solutions might be the choice for that scenario. You won’t get the benefits (and challenges as seen above) of btrfs send/receive. With very large photo libraries rsync might take some time to analyze every time it needs to sync.
1 Like
For now I’ve created 2 separate Issues, differentiating between the quota destroy error and the property set error during send/receive. We can restructure/combine as needed:
2 Likes
@Stevek Re:
We now have at least one of the issues address as a result of this thread and your & @Hooverdan perseverance :).
See:
In that release we now have the official variant of @Hooverdan ‘force’ flag implementation, given we know we are cascading our snapshots in the replication setup.
So thus-far we may still have an issue with the newer kernels re changed behaviour on quotas. Notes on this in the above release notes.
Thanks again for your invaluable input here, the quota issue is still open as I’ve yet to get a reproducer. Likely it requires a certain quota payload that was not evident in my current test machines. And without a reproducer I could not approach a fix, and so moved onto the force flag issue. But bit by bit.
Hope that helps.
3 Likes