I’m having a similar issue on the exact same hardware.
First, I added the following to the grub boot line when starting the install:
cciss.cciss_allow_hpsa=1 hpsa.hpsa_allow_any=1 hpsa.hpsa_simple_mode=1
Next, I added the same line to the GRUB_CMDLINE_LINUX variable in /etc/default/grub. This will ensure that on any future reboots (and I hope upgrades), I won’t have to tinker with GRUB just to load the server.
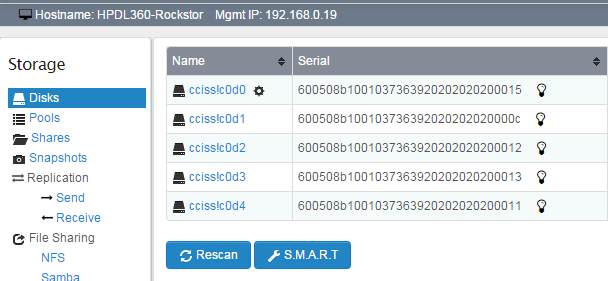
Now that I was in the system, I found that if I click the link for an individual drive on the “Storage” → “Disks” screen I got the following error:
Unknown client error doing a GET to /api/disks/cciss!c0d0
Also, I noticed that wiping a disk was failing with “ERROR: checking status of /dev/cciss!c0d2: No such file or directory” Hovering over the gear icon to the right of my Rockstor boot volume stated that:
Disk is unusable because it has some other file system on it.
In reading this thread, I noticed that @Bearbonez posted this gem:
Ran “wipefs -a /dev/cciss!c0d1” no joy but took a guess and ran wipefs -a /dev/cciss/c0d1 and rescanned the disks in the web-ui and it worked so did the same for the other three.
Notice that if there is an exclamation mark in the device name (e.g. /dev/cciss!c0d2) the wipefs operation failed. However if the exclamation mark is replaced with a slash (e.g. /dev/cciss/c0d2) the wipefs command worked perfectly. I was able to wipe all my disks using this methodology.
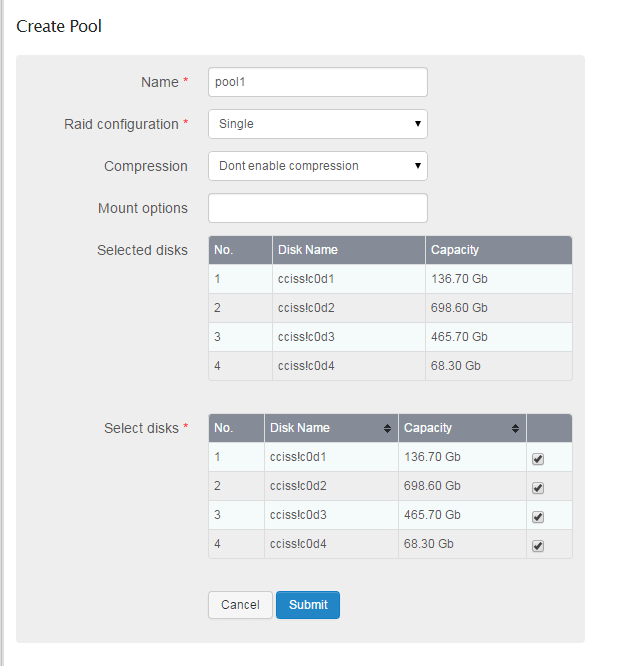
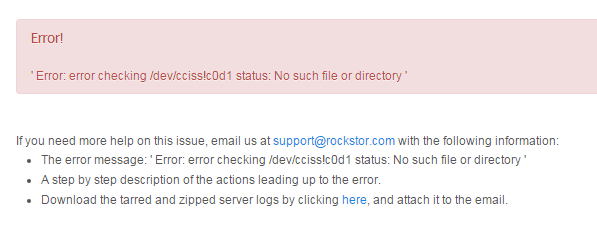
Once I wiped all of my data drives, I decided to create a Pool with them. I received the following error:
Error running a command. cmd = [‘/sbin/mkfs.btrfs’, ‘-f’, ‘-d’, u’raid5’, ‘-m’, u’raid5’, ‘-L’, u’data’, u’/dev/cciss!c0d2’, u’/dev/cciss!c0d3’, u’/dev/cciss!c0d4’, u’/dev/cciss!c0d5’]. rc = 1. stdout = [‘’]. stderr = [‘ERROR: checking status of /dev/cciss!c0d2: No such file or directory’, ‘’]
However, if I ran the command in the shell making a few changes everything appeared to work:
[root@nas ~]# /sbin/mkfs.btrfs -f -d raid5 -m raid5 -L data /dev/cciss/c0d2 /dev/cciss/c0d3 /dev/cciss/c0d4 /dev/cciss/c0d5
btrfs-progs v4.2.1
See http://btrfs.wiki.kernel.org for more information.
Label: data
UUID: f3d3f35b-8553-476b-8c5e-8ab87598e64e
Node size: 16384
Sector size: 4096
Filesystem size: 1.09TiB
Block group profiles:
Data: RAID5 3.01GiB
Metadata: RAID5 3.01GiB
System: RAID5 16.00MiB
SSD detected: no
Incompat features: extref, raid56, skinny-metadata
Number of devices: 4
Devices:
ID SIZE PATH
1 279.37GiB /dev/cciss/c0d2
2 279.37GiB /dev/cciss/c0d3
3 279.37GiB /dev/cciss/c0d4
4 279.37GiB /dev/cciss/c0d5
Unfortunately, while the command appeared to work - lsblk does not list my pool, nor does it appear in the Rockstor UI. But if I turn around and mount the file system - all appears well:
[root@nas ~]# ls /dev/disk/by-label/
data rockstor_nas00
[root@nas ~]# mkdir /mnt/data
[root@nas ~]# mount /dev/disk/by-label/data /mnt/data
[root@nas ~]# cd /mnt/data/
[root@nas data]# ls
[root@nas data]# ls -la
total 16
drwxr-xr-x. 1 root root 0 Nov 16 01:01 .
drwxr-xr-x. 1 root root 8 Nov 16 01:02 …
[root@nas data]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 7.9G 0 7.9G 0% /dev
tmpfs 7.9G 0 7.9G 0% /dev/shm
tmpfs 7.9G 8.5M 7.9G 1% /run
tmpfs 7.9G 0 7.9G 0% /sys/fs/cgroup
/dev/cciss/c0d0p3 129G 1.5G 126G 2% /
/dev/cciss/c0d0p1 477M 104M 344M 24% /boot
/dev/cciss/c0d0p3 129G 1.5G 126G 2% /home
/dev/cciss/c0d2 1.1T 18M 1.1T 1% /mnt/data
The Rockstor UI still doesn’t show me anything about created pools - though when attempting to add a new pool, I only have one disk listed (cciss!c0d1 - this is accurate as this is the only unallocated drive I have at this point in my testing).
I’m wondering if the general disk operation via the Rockstor front end needs to replace all exclamation points (!) with slashes (/) for both display and commands. It appears to have solved the problems with the command line tools - why not the UI?
As I’m running a development system and attached to the test builds, I’m more than willing to pull down a new version to test it on this system. Also if you want any output from the system (lspci, similar inventory or storage commands) just ask.
Thanks!