RazNAS:/opt/rockstor # psql -U rocky -d storageadmin -c “SELECT * FROM storageadmin_rockon”
Password for user rocky:
id | name | description | version | state | status | link | website | https | icon | ui | volume_add_support | more_info | taskid
----±-----±------------±--------±------±-------±-----±--------±------±-----±—±-------------------±----------±-------
(0 rows)
1 Like
I don’t see anything obvious here.
This part is your “page refresh” action
This portion is the “Update” event after you pressed the button.
I tried the commands with my working system yesterday and saw the above messages as well during those actions, but in your case there also doesn’t seem be resulting in an obvious error.
The deadlock message on top of your post I did not see, but I suspect it’s not related to your issue since the context seems to be around the storageadmin_pool table (though it’s also something on the database, so I could be wrong):
@Flox you agree?
2 Likes
I’m curious about that database deadlock… If it’s a continuous deadlock, that could explain it… Although it would most likely have a lot more repercussions throughout the UI.
Would this deadlock message still show up if you try the tail command again now?
It does seem that the error appears before any Rock-On info is fetched so that helps.
My guess is on that deadlock so far.
1 Like
No, I don’t see this message now. And this is coming on random boot as I have attached USB driver, I think.
@Flox would one possibly find more info on the deadlock (and its duration) in the database logs here:
/var/lib/pgsql/data/log/?
1 Like
With help from google, I did one experiment where I have added “nameserver 8.8.8.8” in “/etc/resolv.conf” and then enabled “Rock-Ons”. Here I could use “docker run hello-world” and other docker based commands with out any error. Once I restart the system then “docker” commands are not working and getting Timeout error.
In above both cases I am unable to update “Rock-Ons” via web-ui.
I am not sure does this helps but just want to share my experience.
mhm, when in that situation you run
systemctl status docker
does it show as active/running?
In both cases, I could see following same message.
RazNAS:~ # systemctl status dockerlv.conf
● docker.service - Docker Application Container Engine
Loaded: loaded (/etc/systemd/system/docker.service; enabled; vendor preset: disabled)
Active: active (running) since Thu 2023-08-03 21:46:51 IST; 8s ago
Docs: http://docs.docker.com
Main PID: 14002 (dockerd)
Tasks: 20
CGroup: /system.slice/docker.service
├─ 14002 /usr/bin/dockerd --add-runtime oci=/usr/sbin/docker-runc --config-file /opt/rockstor/conf/docker-daemon.json
└─ 14010 containerd --config /var/run/docker/containerd/containerd.toml --log-level warn
Aug 03 21:46:47 RazNAS systemd[1]: Starting Docker Application Container Engine…
Aug 03 21:46:48 RazNAS dockerd[14002]: time=“2023-08-03T21:46:48+05:30” level=info msg=“SUSE:secrets :: enabled”
Aug 03 21:46:49 RazNAS dockerd[14010]: time=“2023-08-03T21:46:49.275228271+05:30” level=warning msg=“failed to load plugin io.containerd.snapshotter.v1.devmapper” error=“devmapper not configured”
Aug 03 21:46:49 RazNAS dockerd[14010]: time=“2023-08-03T21:46:49.275644190+05:30” level=warning msg=“could not use snapshotter devmapper in metadata plugin” error=“devmapper not configured”
Aug 03 21:46:49 RazNAS dockerd[14010]: time=“2023-08-03T21:46:49.740790051+05:30” level=error msg=“failed to initialize a tracing processor "otlp"” error=“no OpenTelemetry endpoint: skip plugin”
Aug 03 21:46:51 RazNAS systemd[1]: Started Docker Application Container Engine.
Curious. I checked on 2 Rockstor instance (running on 4.6.1-0 and Leap 15.4) and via
journalctl -xe | grep dockerd
I can see those plugin error messages recorded as well, but don’t have an issue to get the Rockon list updated.
However, I don’t understand how after a reboot docker commands didn’t work anymore and you received a timeout … even though the curl command further up gave you back the rockon list.
So, maybe the database deadlock is the more likely culprit… I assume you didn’t find anything in the database logs under /var/lib/pgsql/data/log/?
1 Like
Thanks for the additional information here, @raju_ga153 . You may have already read this in this forum, but the use of USB drives is really risky and prone to lead to issues; this is due to the nature of the USB bus and therefore generally not a safe idea when it comes to storing and reliably tracking data. If I understand correctly, you see such a deadlock message rather randomly on boots, and that may very well may be an illustration of such known issues with the USB bus. This may participate to explain how Rockstor is having an issue interacting with its database. I would thus lean towards @Hooverdan’s recommendation of checking postgresql’s logs in search of more information.
With regards to the issue with Docker you are seeing, this could also be a problem related to above if you rockons-root share is on that problematic USB drive.
2 Likes
I have removed USB drive and installed RockStor freshly to avoid confusion with USB drive. And created “rockons-root” share on ROOT pool itself as I have one disk only.
Even then I am seeing same issue with Rock-Ons update.
Postgresql Log is as follows:
2023-08-04 14:22:10.206 IST [666]LOG: starting PostgreSQL 13.11 on x86_64-suse-linux-gnu, compiled by gcc (SUSE Linux) 7.5.0, 64-bit
2023-08-04 14:22:10.289 IST [666]LOG: listening on IPv6 address “::1”, port 5432
2023-08-04 14:22:10.289 IST [666]LOG: listening on IPv4 address “127.0.0.1”, port 5432
2023-08-04 14:22:10.309 IST [666]LOG: listening on Unix socket “/var/run/postgresql/.s.PGSQL.5432”
2023-08-04 14:22:10.359 IST [666]LOG: listening on Unix socket “/tmp/.s.PGSQL.5432”
2023-08-04 14:22:10.659 IST [707]LOG: database system was shut down at 2023-08-04 14:21:41 IST
2023-08-04 14:22:10.770 IST [666]LOG: database system is ready to accept connections
2023-08-04 14:22:19.981 IST [666]LOG: received SIGHUP, reloading configuration files
2023-08-04 14:22:20.672 IST [666]LOG: received SIGHUP, reloading configuration files
Thanks,
Raju
@raju_ga153, sorry for the silence. I finally got some time to create a VM with a single disk to see whether that might have anything to do it with it.
I used the (presumably) the same setup, i.e. did not run any updates, but on the freshly installed 4.5.8-0 version (saw that in your screenshots.
I created the Rockon Root on the Root pool and configured it for the Rockon Service:
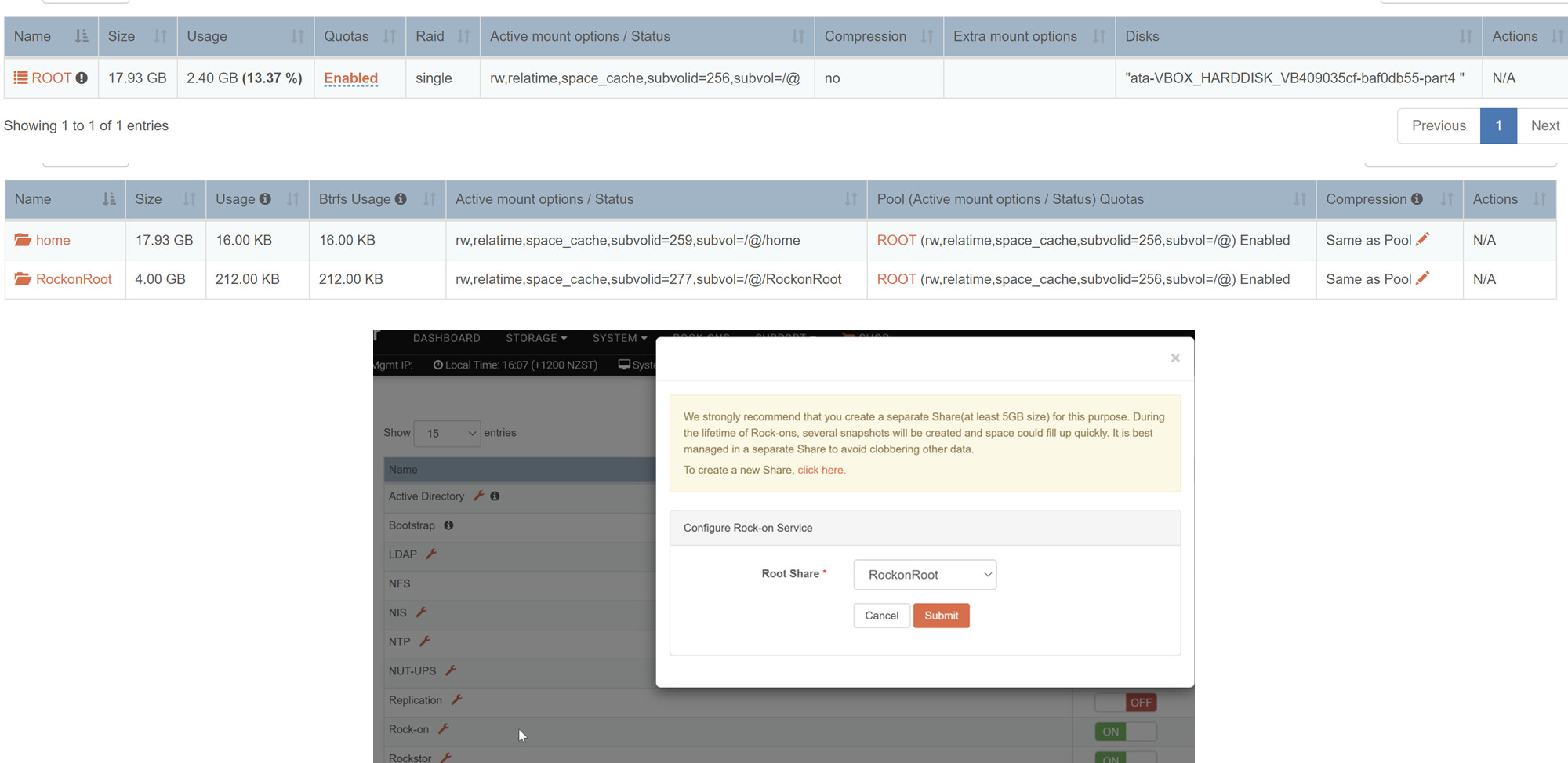
And then proceeded to run the Rockon List update:
In my case it populated the list correctly. I also ran this with the debugger on. I could not see any SQL related messages like you were (the deadlock).
Assuming that because you can use cURL to reach an external website, your network configuration is fine. So, now the question is why you would see a possible deadlock on the database in the storageadmin_pool? I don’t know the answer to that…
I’ll keep thinking about it, but I am afraid that I might not be able to figure out what the issue on your system is.
2 Likes