@jihiggs Hello there, just wanted to chip in with something that hasn’t been brought up yet here.
Then use raid6 for data and raid1c4 for metadata, btrfs can have one raid level for data, and another for metadata. Data takes up the vast majority of actual disk use, metadata is relatively speaking tiny, but costly, ergo mixed raid, as per our slight outdated doc section here:
https://rockstor.com/docs/howtos/stable_kernel_backport.html#btrfs-raid1c3-raid1c4
As from 4.5.9-1 (RC6 in last testing phase) onwards:
We do support mixed raid levels. There is a picture in the GitHub Pull Reqeust here:
And a quick screen shot from the ReRaid
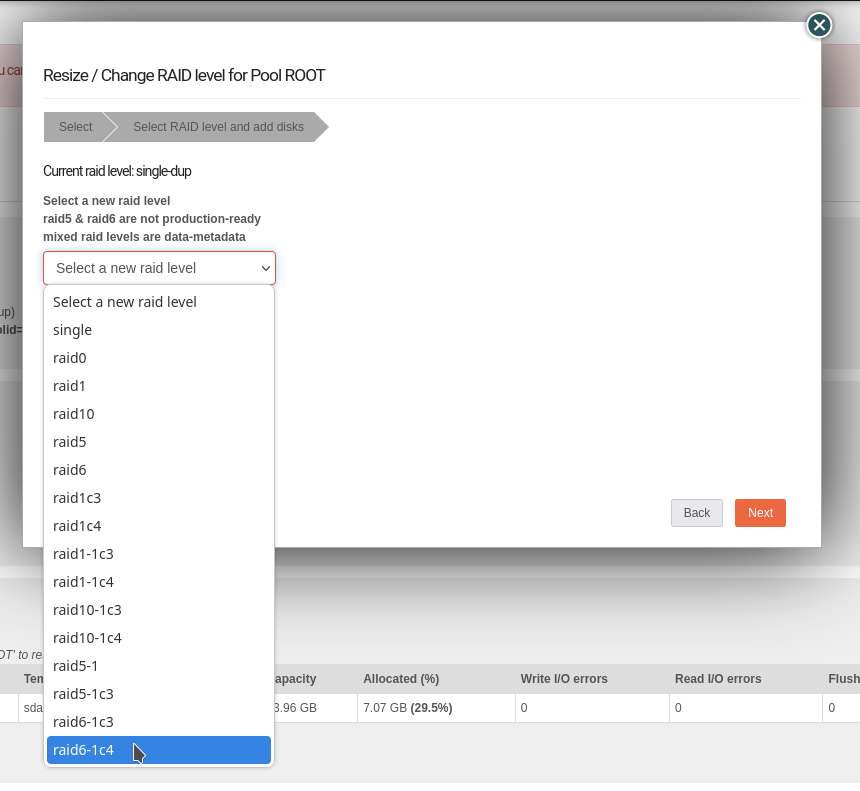
As with many things btrfs we pair down the options to those that make most sense. And support all sane combinations of parity data with raid1c* metadata. But for raid6 data one would go with raid1c4 given the only marginal extra space. I.e. raid6 data handles max 2 drive failure, where-as raid1c4 metadata could handle a 3 drive failure, i.e. 4 copies on 4 different disks. But this does increase your minimum drive count (for raid1 data) up from 3 to 4. So if this was an issue you would go for raid6-1c3 in Rockstor notation i.e. (data raid6)-(metadata raid1c3).
I entirely share your frustration, by the way - however btrfs’s flexibility with such things does negate some of the criticisms levelled at it from a perspective of software raid options that cannot handle differing raid options for data and metadata, and do not have block pointer re-write enabling such things as what we referenced as ReRaid. With the latter enabling you to switch in-play pools live from one raid level to another: again for either or both of data & metadata.
Hope that helps, you and/or others following along with this common discussion in this area.