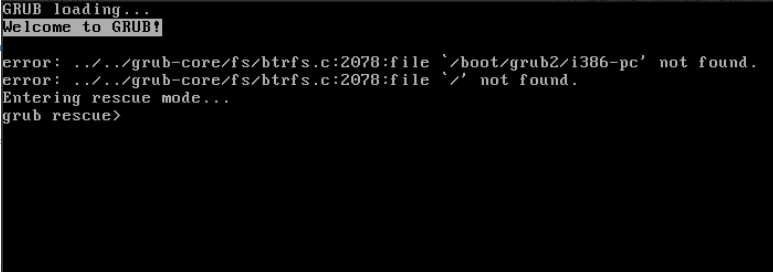
Something went wrong with my boot disk and the system crashed. Not sure if it was due to a faulty cable, or perhaps running out of space. Regardless, I’m getting a grub error when trying my usual boot method.
Setup:
Rockstor stable on Leap 15.5
HP Microserver gen 8 (not UEFI), booting from Super Grub Disk USB due to server limitations
This then loads the rockstor grub on an SSD.
Error:
I’m thinking of a few options.
- Fresh install, restore config from my 6 month old but hopefully pretty accurate backup
- Fresh install on new drive, restore config from existing drive somehow?
- Live boot Leap, chroot, grub install? I haven’t done things like this terribly much before
Any thoughts on the best approach and how to go about it?
@mattyvau sorry to hear that this happened. It seems that grub itself is possibly fine, but an issue with the file system (because of the things you mentioned above). You could attempt to live boot with a liveCD, and then use fsck.btrfs for the device Rockstor is installed on (e.g. /dev/sda).
However, it might be faster to reinstall and use your (hopefully fairly current) backup, since that will only take a few minutes compared to how long it might take you tinker with the repair.
Since you’re not sure whether the drive is failing, you ran out of space, an update went wrong, or you have some faulty cables, it might be safer to use a new drive to do the installation, then evaluate the old drive separately (in another machine or something like that) and use it for something else if it turns out ok.
How big is your current OS drive, and did you store other stuff on it (e.g. many snapshots or other files)?
Restoration from the existing drive would be fairly complex, if possible at all, I would imagine. I also assume you have not stored a more recent config on that drive that you know of? Otherwise one could maybe check whether you can get that file off by mounting that drive and looking for the config file…
1 Like
Thanks for sharing some thoughts, Dan.
You’re right, a fresh install on a new drive will probably be the quickest way to get up and running again. The old drive is 120gb. I don’t recall much else being on there beyond some extra CLI programs above the base install. There shouldn’t be much in the way of snapshots, but I didn’t really keep an eye on the space.
I just couldn’t figure out if the config file was stored somewhere easily accessible so that I could grab it via another machine as you say. Hopefully that slightly older config is close enough to up to date, and given I will use another drive there’s not much to lose.
I was running Rockstor stable, hence the slightly older Leap base. Looks like using the 5.0.15 RC will be the path forward, and we’ll see how a config load goes. Not much to lose using another drive…
120Gib is plenty under usual circumstances (same size I’m typically using). If you did create a configuration backup more recently (but didn’t download) than the one you know you have, you could try to mount the disk on another machine (obviously it has to be mounted as a ‘btrfs’ filesystem). Then you could check whether you have any config backups sitting in this directory path:
/opt/rockstor/static/config-backups
The directory might not exist, meaning no config backups are stored on the machine. There is no simple way to create and import a database dump, so all things the same, using the config backup you have is probably the simplest way.
2 Likes
Interestingly, when I popped that drive into another PC via a USB adaptor the /opt directory was empty. I will try to take more of a look at a later time, as the re-install went pretty well so I’m mostly back up and running.
Strangely, the Pools page shows one of my pools in single mode, yet it shows both drives when you click on it. The other pool of two drives imported properly. Hesitant to touch the faulty pool just yet.
Interesting that the /opt/ is empty (you’re saying the entire opt directory is empty, right?). It would imply that the entire rockstor installation was wiped out for some reason. Other directories and content therein are still there?
Single mode only describes that there’s no redundancy across drives, so it implies that while both disks are in a pool, the data written to them (metadata included) is not spread across disks…
though if you know that you had set it up in a different mode, it is again curious why it now shows up as single. Can you see whether you’re missing data, or (at least on the face of it) it all looks intact?
May be back the data up (which of course is always a recommendation) and switch to the mode you intended to have for that pool.
In any case, before doing anything rash, don’t forget to save a current version of your configuration to somewhere else and backup your system (if you can).
1 Like
It might have been down to something strange in how it mounted on my desktop, which also uses btrfs. I might take another look from a live distro. Turns out I was coming down with my first ever covid infection a few days ago, so troubleshooting was getting increasingly difficult.
For now, I’ve done the data backup for everything important on that pool, in addition to my automated Backblaze backup via the Duplicati rock-on. It certainly seems all intact. Will now try switching the raid level. Maybe it had been running incorrectly for a while and I didn’t notice, though it did also have regular scrubs and they were fine.
Let’s see…
1 Like
hope your recovery is going well, both physically and NAS related.
Let us know how you get on with both (checking out the investigation on the old disk and the raid level switch).
The raid level switch can take some time, a lot of depending on how big and populated that pool is. Depending on how full the disks are you might have to remove some stuff first, though I did not have that experience, but in the past I moved from a RAID5 to a RAID10c3 and that did not pose a problem, aside from it taking a couple of days due to the amount of data being re-arranged.
2 Likes