For a while now my rock-ons where broken, but I didn’t have time to investigate. Additionally, updates seemed to have failed, and I was stuck on 4.0.7 for a while.
I finally found some time and thought the first thing is to do the update as it maybe magically fixes all other problems. No game.
I managed to get it to update to 4.0.9 using SSH and the zypper refresh && zypper up command. That worked.
But here are the issues:
-
The web ui is generally very slow, with usually at least 10 seconds for any page, but often more than 50 seconds (this problem existed before the update as well)
-
The rock-ons services can’t be started anymore, the https call times out after 2 minutes and I get an empty error message, the browser debug says the server returned a 504.
-
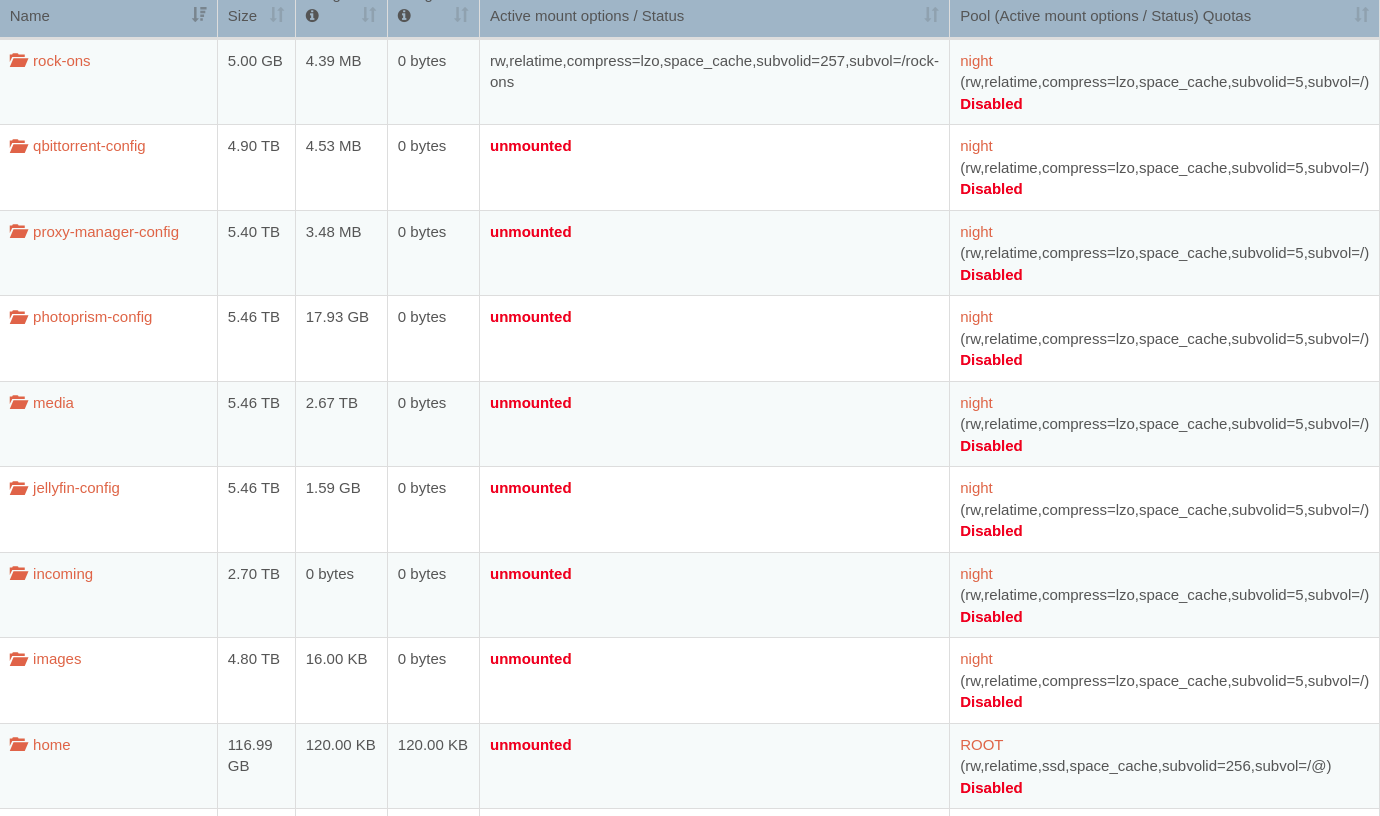
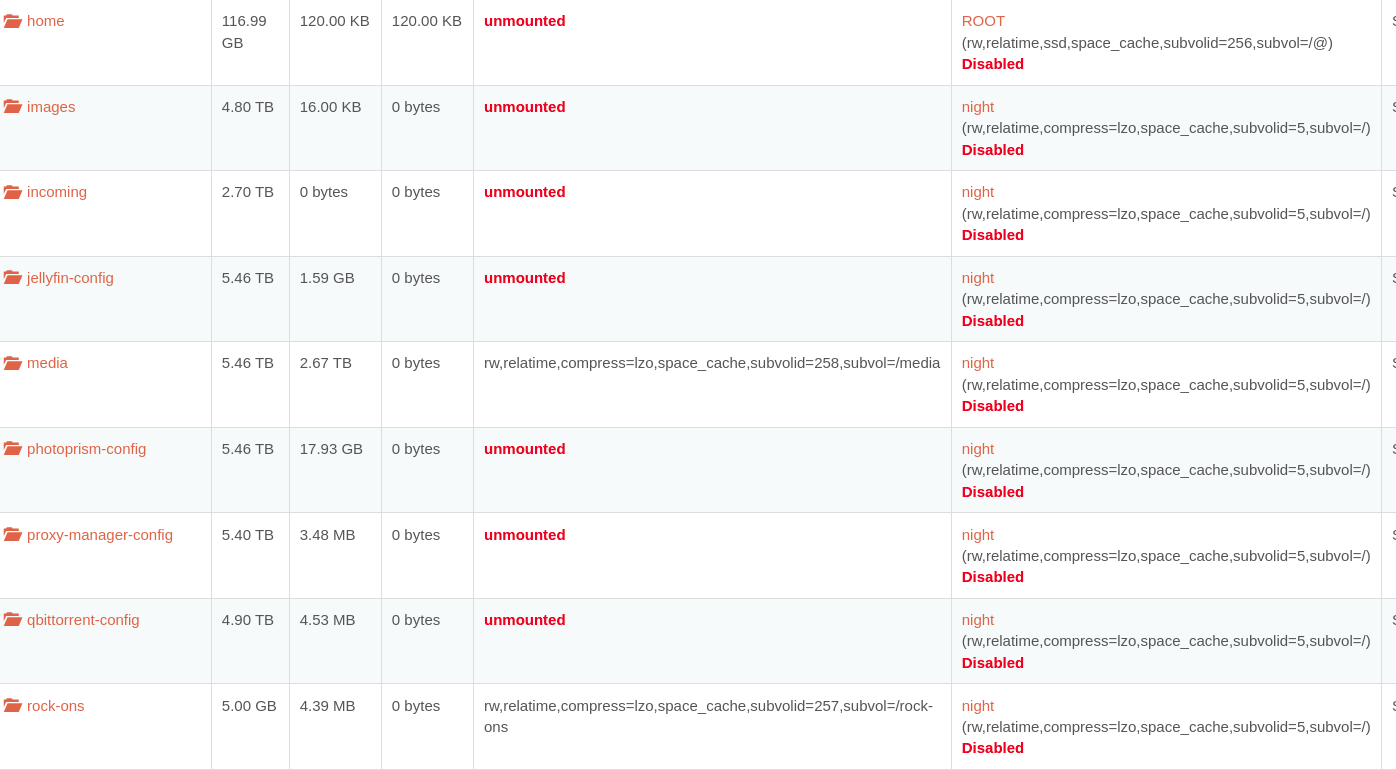
All my shares are listed as unmounted, though they still work, even using SMB and NFS
-
The logs show a lot of this, possible related to the rock-on service start failure?:
[2021-12-16 00:56:15 +0000] [1920] [CRITICAL] WORKER TIMEOUT (pid:7237)
[2021-12-16 00:56:15 +0000] [7237] [INFO] Worker exiting (pid: 7237)
[2021-12-16 00:56:16 +0000] [10312] [INFO] Booting worker with pid: 10312 -
gunicorn starts this process roughly every 20 seconds:
/usr/sbin/btrfs qgroup show -pc /mnt2/dawn
The command runs for about 17 to 18 seconds and utilizes 100% of one core during the whole time. -
Similar, but not as often and long, this command runs:
/usr/sbin/btrfs qgroup assign 0/1641 2015/31480 /mnt2/dawn
Also utilizing 100% of one cpu core. -
Possible relevant:
ping6 heise.desays network not reachable, though I do have ipv6 addresses assigned and enabled (didn’t have that before the update I think)
I am running version rockstor 4.0.9-0 with kernel Linux: 5.3.18-lp152.106-default
rockstor:/opt/rockstor/var/log # ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether d0:50:99:d0:1a:8f brd ff:ff:ff:ff:ff:ff
inet 192.168.1.157/24 brd 192.168.1.255 scope global dynamic noprefixroute eth0
valid_lft 39132sec preferred_lft 39132sec
inet6 fd23:6d09:2216::428/128 scope global noprefixroute
valid_lft forever preferred_lft forever
inet6 fd23:6d09:2216:0:2cc8:180e:624b:2c92/64 scope global temporary dynamic
valid_lft 600734sec preferred_lft 81779sec
inet6 fd23:6d09:2216:0:d9f:2c59:ee7d:9f7d/64 scope global mngtmpaddr noprefixroute
valid_lft forever preferred_lft forever
inet6 fe80::ca9e:9681:1cc7:e375/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: eth1: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc pfifo_fast state DOWN group default qlen 1000
link/ether d0:50:99:d0:1a:90 brd ff:ff:ff:ff:ff:ff
4: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:47:91:d2:86 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:47ff:fe91:d286/64 scope link
valid_lft forever preferred_lft forever