I have an old disk in my NAS (via USB) that is old and looked like it was on its way out. As such, I decided to remove it from my pool before it became a problem, but unfortunately, this seemed to cause me more problems.
I have removed the drive from the pool, which seemed to go OK, eventually.
After a reboot to take the disk out physically, my pool now complains of a missing drive.
Shut down again, insert the drive, boot back up, but the pool is still stuck in this same position. After the drive changes I was going to change the RAID setup, as I am currently using single, which makes me think I know what the answer is going to be regarding this.
However, bit of a long shot I think, but hopefully someone can shed some light as to what I have done here.
I have run “sudo btrfs fi show” with the following results:
warning, device 1 is missing
bad tree block 4325392384, bytenr mismatch, want=4325392384, have=0
ERROR: cannot read chunk root
Label: ‘Plex’ uuid: 4da94760-8e39-4c6b-8893-8140102df1a3
Total devices 4 FS bytes used 2.38TiB
devid 2 size 1.82TiB used 1.40TiB path /dev/sde
devid 3 size 931.51GiB used 507.00GiB path /dev/sdd1
devid 4 size 931.51GiB used 507.03GiB path /dev/sdc1
*** Some devices missing
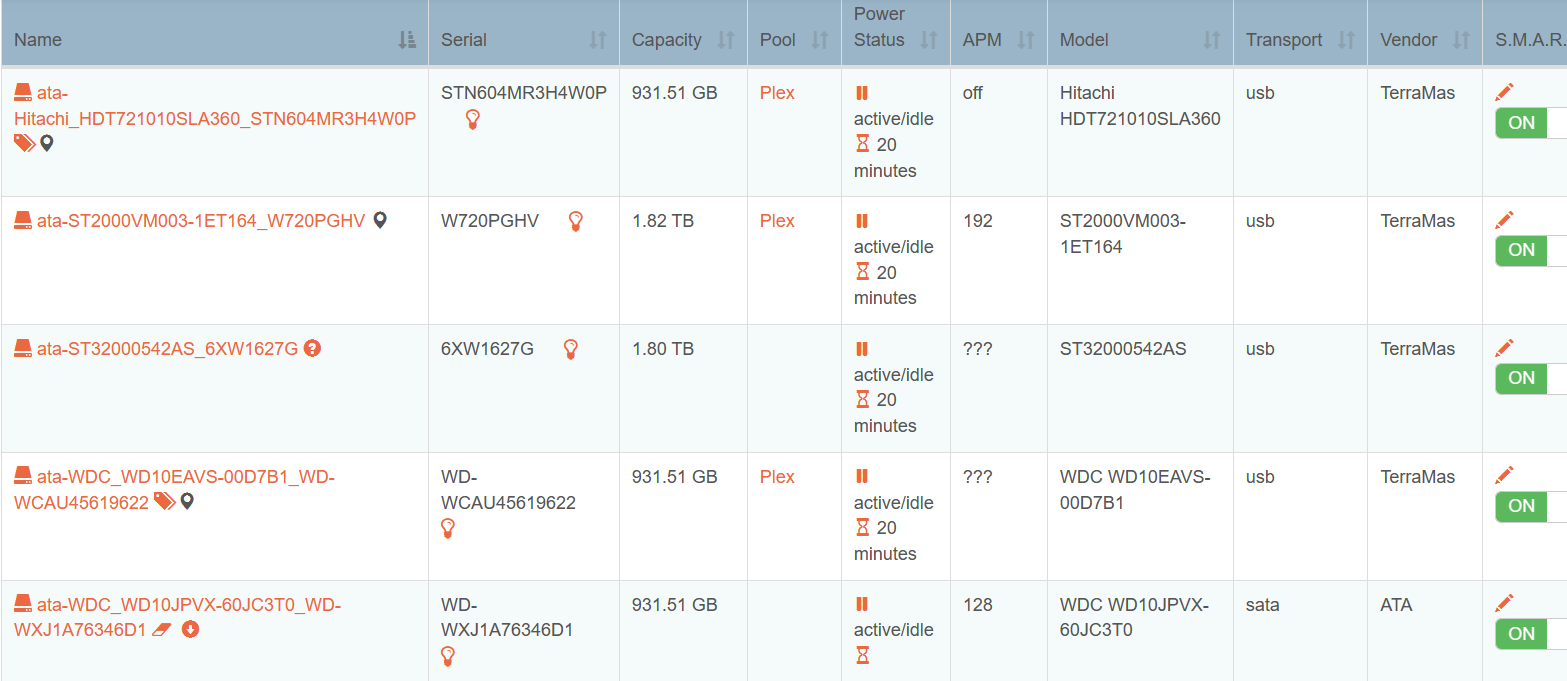
This image shows the disks screen, the one ending 27G is the one that was removed.
Trying to do anything with the pool errs, as expected with a removed drive. My issue is that the drive is there, and can be used by another pool, if I was to create one
Is there a command that I could run to check the expected disks in a pool to confirm that I have, in fact, inserted the correct drive? Or force the pool to check the drive serial numbers? etc
Yes, that is not a good sign on a non-redundant profile. Single stores only a ‘single’ copy: ergo no redundancy. Each Pool member (drive) will have a unique set of data chunks. Drive missing means filesystem incomplete.
As you say, it looks like that drive is no longer associated with a pool. But the pool via your btrfs fi show (no sudo required if you are the root user already) indicates that it has a missing dive: hence my first question on how you went about removing the drive.
You have run it already. the btrfs fi show indicates if it can find all drives. Serial numbers are how Rocktor tracks drive: independant of btrfs. Btrfs itself uses uuid identifiers on each disk format to know if it belongs to a pool or not. If your drive is not longer seen as part of the pool (from the command line ‘fi show’), it no longer has this info on it. Again back to how you removed the drive initially.
Thank you for the reply, very helpful!
To answer your first question:
I used the GUI, Resize, then remove drive.
From what I can see, I am out of luck and will need to rebuild the share from scratch. As I did the resize from the GUI, my assumption (perhaps incorrect?) is that the data would be theoretically in tact, but the pool is inaccessible via Rockstor. Would I be able to recover any of these files, even if via another computer?
Assuming nothing went wrong during the removal process. If this drive was poorly/failing, the resize would have been the last straw. Single has no redundancy: if it was asked for data that it could not any longer provide then the whole pool is toast. That is the nature of Single: no redundancy.
And that apparently completed OK you say. I’m thinking that it may have failed part-way-through. Hence the pool now being poorly.
That would be the Pool (Btrfs volume). We call btrfs sub-volumes Shares: as in a share of the pool. These shares can then be exported via say Samba.
Single profile with a missing drive is a poor outlook I’m afraid; as you suspect. There is not redundancy: and so if that drive failed, or had already lost info critical to the pool (any data on it was critical given single profile) then you may be out of luck.
How critical is this data: if you have proven back-ups then that is your best bet. But otherwise you may be able to reclaim some data from this pool via the command line if you have sufficient storage to dump it to. Look into how to use:
But it can take a long time and end up being unfruitful as your pool had no redundancy so basically has unknown size/number of holes in now.
Another long shot (but easy and worth trying) is to try a degraded and ro mount option: all depends on the state of your backups really. That is accept degraded state, and only mount read-only which is far more forgiving and enables you to potentially refresh your backups. There are a number of mount options also that are aimed at progressively easing checks to assist with data recovery: but again only one copy of each bit of data is only one copy. If it has been corrupted it will not be returned by the volume. You logs may help show what failed during the drive removal.
So try the degraded ro extra mount options to see if you can at least get a workable mount. But if not, the above btrtfs restore command can retrieve data without even a mount. But everything is a long shot with single as no redundancy, but you may have had a dup on metadata but that does not guarantee both dup’ed copies are on different drives as that is btrfs-raid1. Newer Rockstor versions show both the data, and metadata levels of a pool.
Apologies, I did mean Pool… I am fairly new to this, as you can probably tell.
Thank you for your suggestions, I will investigate these options now. The data isn’t horrendously critical, some is on disc, the only thing there is man hours taken cataloging. I will be ensuring that on my next pool I will use a better raid configuration!
I have been able to get the data into a new pool, this time with raid1 configuration. I will be looking at that a little closer further down the line.
However, now I am somewhat confused. I have a pool that have a few TB of data that I want in a share. I am unable to create a share that used the entirety of the pool, as the share creation ui claims this space is in use, but the only thing it is in use with is the data I want in the share (I hope that makes sense!)
I think I am missing something really simple here, but a bit of googling hasn’t helped…
@thefunkaygibbon, if you have data on your new pool, I would assume, the only way you got it there is by creating a share first? Or am I misunderstanding what you stated above? Maybe a screenshot or 2 could help clarify.
In general, since Rockstor does not enforce quota restrictions (yet), each share can theoretically consume the entirety of the pool it’s associated with.