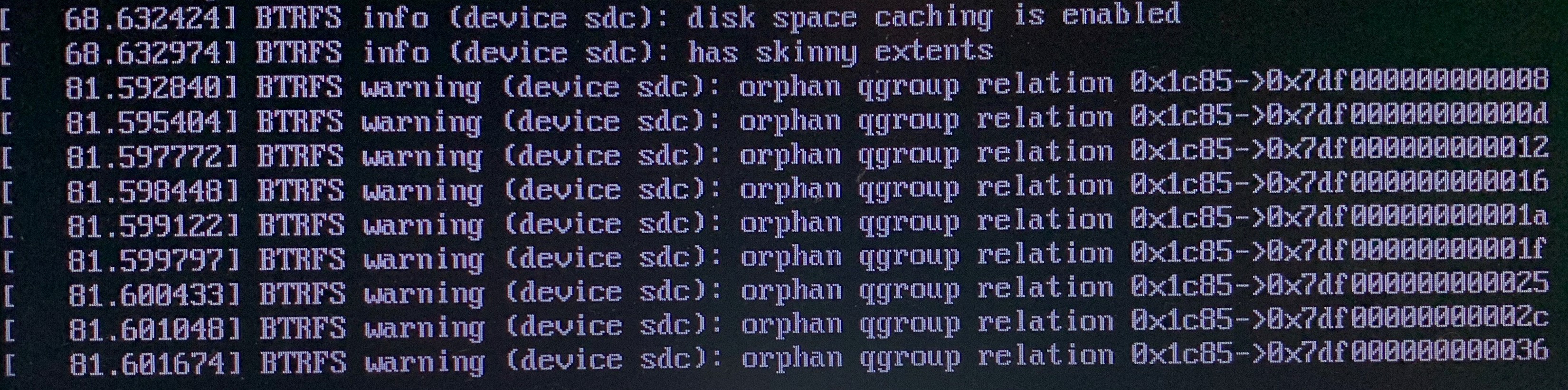
This is still on my Centos 3.9.2-57 version with a recent kernel update.
I was trying to perform some cleanup of Rockon shares.
I cloned an existing share using the WebUI. Once the cloning process was done, I removed the original share that I cloned from. So far so good. 24 hours later I tried to continue, by cloning another share into a new one, and then ran into the issue below. I also tried creating a new share directly on the same pool (not the OS drive by the way), but that failed as well.
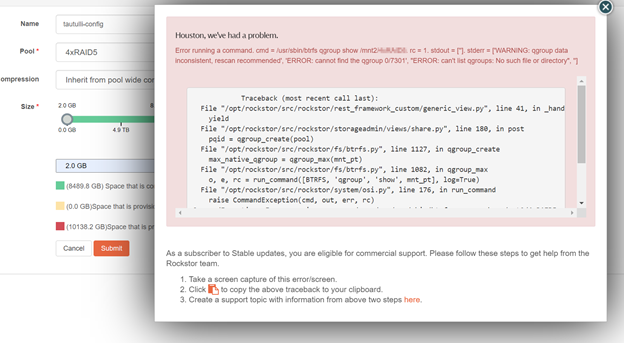
Traceback (most recent call last):
File "/opt/rockstor/src/rockstor/rest_framework_custom/generic_view.py", line 41, in _handle_exception
yield
File "/opt/rockstor/src/rockstor/storageadmin/views/share.py", line 180, in post
pqid = qgroup_create(pool)
File "/opt/rockstor/src/rockstor/fs/btrfs.py", line 1127, in qgroup_create
max_native_qgroup = qgroup_max(mnt_pt)
File "/opt/rockstor/src/rockstor/fs/btrfs.py", line 1082, in qgroup_max
o, e, rc = run_command([BTRFS, 'qgroup', 'show', mnt_pt], log=True)
File "/opt/rockstor/src/rockstor/system/osi.py", line 176, in run_command
raise CommandException(cmd, out, err, rc)
CommandException: Error running a command. cmd = /usr/sbin/btrfs qgroup show /mnt2/<pool name removed>. rc = 1. stdout = ['']. stderr = ['WARNING: qgroup data inconsistent, rescan recommended', 'ERROR: cannot find the qgroup 0/7301', "ERROR: can't list qgroups: No such file or directory", '']
note: I scrubbed my pool name from the error message
No quotas are enabled (and haven’t been for years).
I suspect that a clone/delete share operation the day before might have done something to the consistency of the quota definition (even if they are not active). I wasn’t entirely sure about how to perform a rescan (since the error message suggested that) from the UI, so I used the command line:
/usr/sbin/btrfs quota rescan -R /mnt2/<pool name>
to see whether any rescans were running, and when there weren’t any:
/usr/sbin/btrfs quota rescan /mnt2/<pool name>
After completion (a couple of minutes of checking with the above -s option) This didn’t seem to resolve the issue.
In the meantime, I started a scrubbing operation on the pool, as I realized that my scheduled scrub hasn’t been running for quite some time for some reason (separate topic, I think).
Any suggestions?