Now that I’ve finally got this thing running I now have another issue. I cannot create a single pool. I’ve tried with just a single drive, two drives, different raid levels, all 9 drives. It will not create a single pool. the drives are known good. This is the error i get whenever I try to create a pool. if it’s say a raid 10 it’ll list every drive in the pool. if I try to eliminate by process of elimination one drive at a time it’ll just switch to the next one saying its busy. Am I missing something? Tried to find an existing thread but the only one I found there was no resolution to.
Error running a command. cmd = /usr/sbin/mkfs.btrfs -f -d single -m dup -L Main_Pool /dev/disk/by-id/ata-ST1000NM0011_Z1N13K95. rc = 1. stdout = ['btrfs-progs v4.19.1 ', ‘See http://btrfs.wiki.kernel.org for more information.’, ‘’, ‘’]. stderr = [‘ERROR: unable to open /dev/disk/by-id/ata-ST1000NM0011_Z1N13K95: Device or resource busy’, ‘’]
If I try multiple drives I get this
Error running a command. cmd = /usr/sbin/mkfs.btrfs -f -d raid10 -m raid10 -L Main_Pool /dev/disk/by-id/ata-ST1000NM0011_Z1N13K95 /dev/disk/by-id/ata-ST1000NM0011_Z1N13KJA /dev/disk/by-id/ata-ST750LM022_HN-M750MBB_S31PJ9DF406803 /dev/disk/by-id/ata-ST9500325AS_6VESAPLW /dev/disk/by-id/ata-TOSHIBA_MK5065GSXF_12BKC357T /dev/disk/by-id/ata-TOSHIBA_MK5065GSXF_X1N6P5VFT /dev/disk/by-id/ata-WDC_WD10EARX-00N0YB0_WD-WCC0T0144635 /dev/disk/by-id/ata-WDC_WD10EARX-00N0YB0_WD-WMC0T0327099 /dev/disk/by-id/ata-WDC_WD10EARX-00N0YB0_WD-WMC0T0332359. rc = 1. stdout = ['btrfs-progs v4.19.1 ', ‘See http://btrfs.wiki.kernel.org for more information.’, ‘’, ‘’]. stderr = [‘ERROR: unable to open /dev/disk/by-id/ata-ST1000NM0011_Z1N13K95: Device or resource busy’, ‘’]
@jjairpants Well done on getting it v4 installed and booting at last, presumably on the problematic system in the following thread (hopefully):
Care to update that thread on how you eventually got around what-ever the problem turned out to be. Always nice to hear how a problem was sorted as then future folks, or future ‘us’, can find such things here and make the forum a better reference as we go.
Have these drives been used previously in an mdraid, or as a zfs pool? That can block them from being used as they are ‘otherwise engaged’ might be worth a try. We have yet to document these corner cases but there is a note on the mdraid prior use here:
If so that issue documents how one releases such prior use mdraid devices from their prior lives (and wipes them without return mind).
Hope that helps. And as always let us know how you get along. Always useful to have feedback on such things as our docs for example, and they are intended to get folks of any knowledge up and running as easily as possible. So problems are opportunities in such case.
I did update the other thread. Thanks for the help on that one. That was an Interesting one. It was the TPM chip.
As to your question about the drives, yes, a few if them did come out if another server that was had a PERC raid controller. Should have proba ly for matted them first. Tried to do that through the cli but it wouldn’t let me do it there either. I may have to pull them and manually do it. But…at least 4 of the 9 drives were formatted ext4 prior to me installing them. Those won’t add to the pool either. None of them will. Not even in a single drive pool.
It’s odd, as I was digging around in the terminal, I saw a few said they were part of “main_pool” which is what I named it. But they never really did get added in the GUI. And no pools show up but the root pool.
I’ve tried the build in tool to wipe them, it doesn’t seem to do anything at all.
@phillxnet is the expert here but while timezones are in your way, let’s see if I can get more details… Do you see that when running btrfs fi show ? Could you paste the output of it?
btrfs fi show
A screenshot of your disks page might also prove useful to rule out some issues.
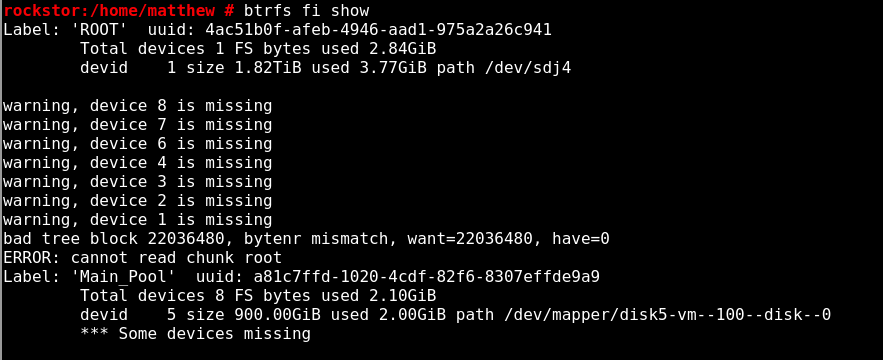
Oh that’s no problem. i’m not in a super time crunch with it. I’m just glad you guys have a community that’s so responsive. here is the output from the terminal.
That’s an interesting output there… One of your pool creation attempts indeed seems to have indeed created something as you do see a Main Pool pool.
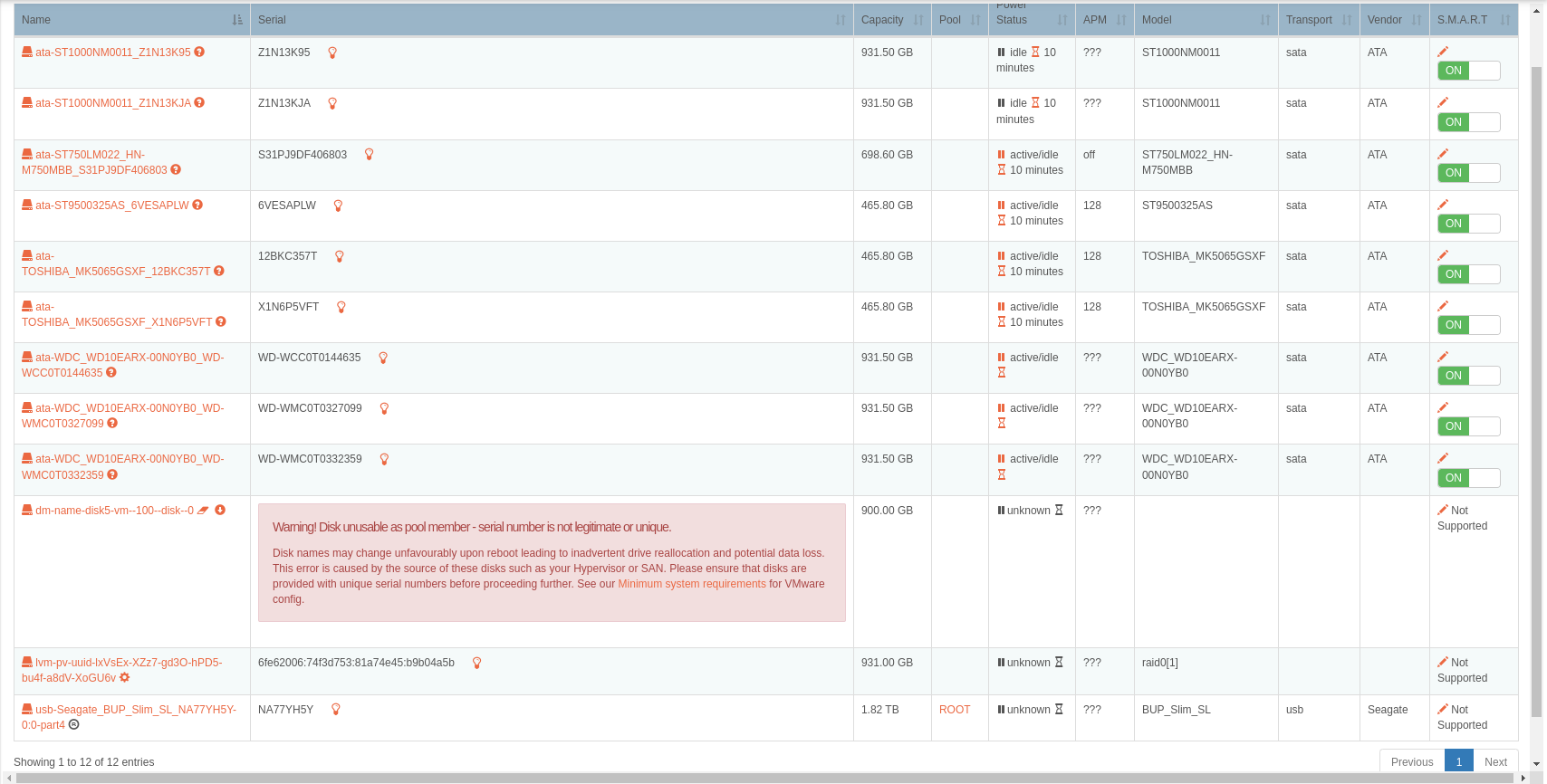
The disk page is also showing an issue with one of the disks; maybe it’s throwing the rest off. As you can see, one of them is violating the requirement of having a unique serial number (this is how Rockstor keeps track of each drive). In this context, it could be helpful to see how the system is seeing all these drives:
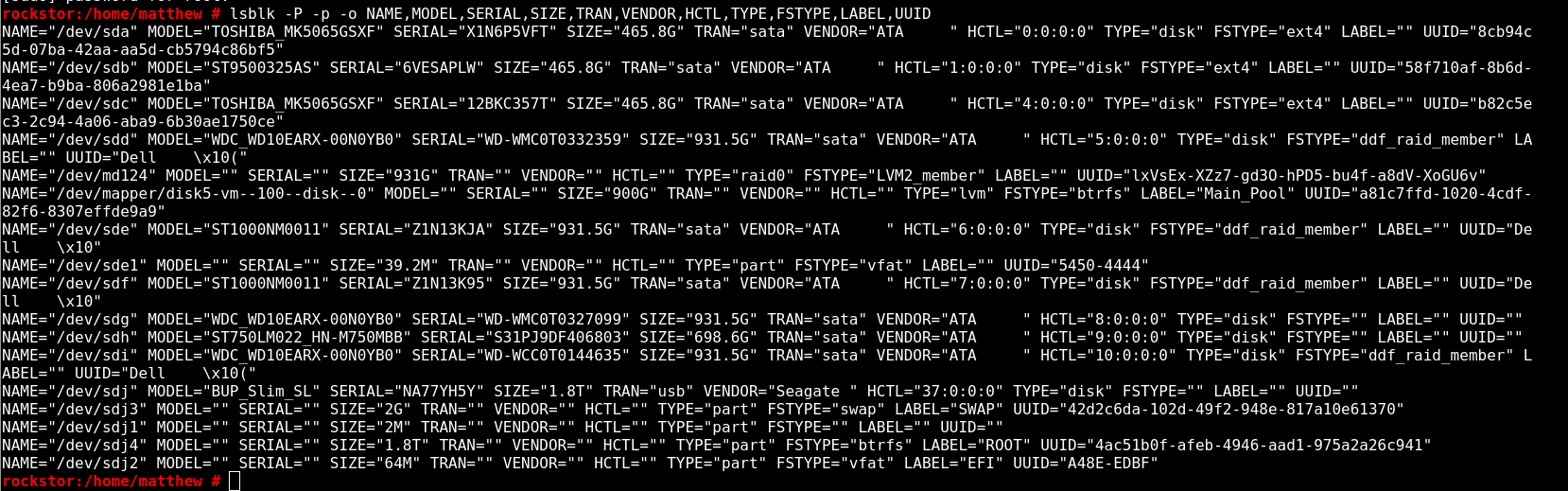
I’m not quite sure on that disk, I thought it was odd as well that it showed up like that. It’s possible it came out of my proxmox server at some point. (i have disks laying everywhere around here, so when one dies i can replace it) I tried to format that disk to no avail. I think that’s actually a partition on that disk itself. I can replace that one, not really an issue. Not too worried about that one particular disk. to rule that out I refrained from trying to add it to a pool, still no dice. anyway here is the output of that command. sorry for the screenshots, I cannot figure out how to copy the text from the browser shell session.
Drives that begin with md in by-id name are mdraid and you look to have an lvm Pysical volume there also. We have very limited mdraid support (on our olden days of CentOS and then only for the system drive) it’s not a priority for us and that drive has a serial warning so looking dodgy on that front. It’s likely a virtual drive, but what-ever for now, for simplicity. Remove all drives that are mdraid or lvm. Or wipe them, via instruction in that issue for mdraid or via a wipefs.
And the rather odd “btrfs fi show” looks to suggest a drive have already been ‘tagged’ as a member of a prior pool named Main_Pool which at one time had 8 “Total devices 8” where only one drive is now connected. That’s not going to fly on the import side :).
Also can say if this install is from the installer, we don’t support multi-path.
So basically if you remove the unsupported devices (mdraid lvm) or wipe them by the appropriate method, you should be good. But a re-install will likely be required as once things get confused it can be far harder to unpick them. There is a build in nuke-and-pave capability (via the .initrock flag file removal followed by a reboot, or full rockstor services re-start) but a re-install on relatively modern hardware is fairly quick. Just be sure to wipe all disks. You may well be able to to this from within this install but the must be removed of the incompatible stuff like mdraid, lvm, partitions (mostly). Then it should be plain sailing. When there are the remains of an old btrfs pool, especially when it is unrecoverable, Rockstor tends to be less aware of this unrecoverable and offers few Web-UI options to avoid doing-the-wrong-thing. We have to be careful not to make a pool destroy too easy and pool recovery is a potentially tricky afair. But one drive our of a prior 8 set is not going to work out.
So in short, confusion all around, yours, ours, Rockstor’s is highly likely while there are incompatible prior formats at play. Most notably the mdraid (special procedure to wipe, as per referenced issue) lvm again this requires lvm tools to resolve. And the rest Rockstor can likely handle via it’s own internal use of the generic “wipfs -a dev-name-here”, see the following for how we use that:
Obviously take super care with such commands as they are terminal for data in almost all cases.
And a “ssh root@your-machine-ip” should work out-of-the-box. We have this enabled by default.
the lsblk output request by @Flox has the following incompatible items:
Note in the below, for speed, Im using the canonical names, but these can change from one boot to another, it’s why we use the by-id names; but you get the idea.
/dev/md124 (virtual mdraid created from it’s member devices, see the mdraid removal issue), this also has: FSTYPE=“LVM2_member”
/dev/mapper/disk5-vm–100–disk—0 (could be an md124 member) N.B. TYPE=“lvm” and FSTYPE=“btrfs” this is going to be a major source of confusion for Rockstor.
/dev/sdd has FSTYPE=“ddf_raid_member” not sure what that is! but we only do btrfs, at least within the Web-UI.
/dev/sdd another FSTYPE=“ddf_raid_member”
/dev/sde with a partition on /dev/sde1, Web-UI when not confused should be able to wipe this. Also note this is another ex raid thing or other: FSTYPE=“ddf_raid_member”
/dev/sdf another FSTYPE=“ddf_raid_member”
/dev/sdi another FSTYPE=“ddf_raid_member”
So it’s really just the legacy mdraid (see referenced issue for removal) and the lvm (see lvm tools). And in your particularly colourful arrangement you appear to have an lvm member made up from a potentially incomplete mdraid. So this kind of multi layer device management is why we like to keep things simple and use only whole disk and have one ‘entity’ manage them from the metal to the data. No partitions, no ‘other’ device management such as LVM MD/DM raid etc. Otherwise it gets very confusing all around. Although we did make an exception for supporting LUKS which works similarly by presenting ‘virtual’ devices. That was important and didn’t directly clash with our core btrfs interests.
My apologies for the repeats here, having to dash as I type unfortunately.
Just wanted to update on how I got this working. yes, it was a mess. no matter what i tried I could not, for the life of me get the mdraid partition tables wiped. wipefswoul would not get rid of it. I wound up just using dban to wipe every drive in the system. Just started it, let it run during the night and when it was done i did a fresh install as suggested. all is well. all drives were able to be added to pools and it’s humming away. Thanks to all for the help and pointing me in the right direction. seems to be pretty stable now. no more errors have cropped up.
Yes, that will generally learn them, as per our PBP.
Thanks for the update and glad your now sorted. We have some usability corner cases still and this is partly one of them, but we now have most of the more common ones issued and are working our way through them while simultaneously dealing with a bit of backlog regarding updating our libraries etc.
Glad it’s up and going. but another issue has arose. maybe need to put in a separate thread? I can’t create shares on the main pool. I can on the root pool but not the main one. samba is running. though not sure that would be a deal breaker to just create a share. I’ve tried enabling quotas, disabling quotas. I can delete the pool and create a new one if you think that may be an issue. there is no data on it.
Traceback (most recent call last):
File “/opt/rockstor/src/rockstor/rest_framework_custom/generic_view.py”, line 41, in _handle_exception
yield
File “/opt/rockstor/src/rockstor/storageadmin/views/share.py”, line 206, in post
add_share(pool, sname, pqid)
File “/opt/rockstor/src/rockstor/fs/btrfs.py”, line 645, in add_share
toggle_path_rw(root_pool_mnt, rw=True)
File “/opt/rockstor/src/rockstor/system/osi.py”, line 654, in toggle_path_rw
return run_command([CHATTR, attr, path])
File “/opt/rockstor/src/rockstor/system/osi.py”, line 224, in run_command
raise CommandException(cmd, out, err, rc)
CommandException: Error running a command. cmd = /usr/bin/chattr -i /mnt2/Main_pool. rc = 1. stdout = [’’]. stderr = [’/usr/bin/chattr: Read-only file system while setting flags on /mnt2/Main_pool’, ‘’]
Probably best, but it may just be that your have created a raid5 or 6 pool. These are read-only by default due to our upstreams dicision on this. The parity raids of btrfs are far younger and have known issues so openSUSE has made them read-only by default.
As of Rocksor v4 “Built on openSUSE” Leap 15.3 base, the far younger parity raid levels of 5 & 6 are read-only by default. Write access can be enabled by Installing the Stable Kernel Backport: advanced users only. See also our Btrfs raid1c3 raid1c4 doc section on the same page.
You don’t mention your raid level so I can’t be sure but it seems likely this is the cause of your newly created Pool returning a:
In our development baes of Leap 15.0, 15.1, 15.2 this was not the case. But come 15.3 it was deemed time to force folks to be aware of this younger development nature of the parity raids. That is why we have chosen not to document simply enabling rw via a kernel/module option (but that is covered in other forum threads) but to instead suggest folks upgrade to newer kernel and filesystem stacks if they really must use the parity raids.
Hope that helps and let us know if that was it. And if so, and if you really must use a parity raid, do take a look at that HowTo regarding what we suggest as there is some good info in there: at least I like to think so.
yep that was it. it’s a raid 5 pool. i have backup power so i wasn’t as concerned about the corruption issues. that and it’s not used for crucial data. I’ll give the documentation a read on it. I was aware of the typical concerns with it but hadn’t realized you made it read only.
Just to be clear on that point. We tend to leave such large decisions to our up-streams. We are not the fs experts and openSUSE and their SuSE/SLES connections employ a few btrfs developers, is my understanding, and they are.
Yes it does. I just decided to wipe the pool and make it a raid 10. I figured it will make it a whole lot easier for you all to trouble shoot if I wasn’t I. There mucking around just to make it work with a raid 5 set up. Although, raid6 support would be nice to have if they can ever sort all that out. Especially with large arrays. I’m about to put a 48Tb array together and raid6 would be pretty nice. Just test driving rockstor at the moment. The only thing I’ve had against all the other raid configurations is the idea that if you lose more than one drive you are hosed. Usually it happens on a resilver. The last time I test drive rockstor was the very first version. I lost an entire data set due to a bug and you guys helped as best as you could to get it back but it was gone. I had a backup but it still kinda stunk. So I moved back to freenas/truenas and have been there since. I did welcome thier move to debian. But I really like the options with btrfs. We will see how it goes.
Yes, that is why we have introduced the above doc sections as I’m really hoping to extend Rockstor’s Web-UI to at least be aware of the above options. That is, specifically for large drive count Pools (that are often also plain-old large sized) folks very much need the 2 drive failure capability, which from our btrrfs-raid overview section:
2 drive failure only offered by btrfs-raid6 which is of the younger parity variant).
of our currently Web-UI incorporated btrfs-raid levels.
But as indicated in the highlighted sections within that kernel and filesystem backport, there are newer raid levels raid1c3 & raid1c4 that can also handle a 2 drive failure scenario. You just have to install the backports to get them, and via a mixed raid scenario between data and metadata can also give a some efficiency regarding usable space, i.e. as in the proposed setup in that howto of btrfs-raid6 data and btrfs-raid1c4 (might as well) for metadata.
Agreed. And things have moved on, on all fronts, since then. Plus we are now on an OS base (the “Build on openSUSE” bit) that officially supports btrfs, which CentOS never did.
So how about, for your:
you consider the manual creation (or manual conversion post Rockstor pool creation) of say a:
data - btrfs-raid6
metadata - btrfs-raid1c4
But only do any Pool creation after installing the kernel and filesystem backports as per that HowTo and then rebooting into them.
I mention this as it then hopefully serves your needs better and gives us a tester (that would be you) for additions/improvements that we need to make and can begin rolling out in our hopefully soon to be re-released testing channel rpms. It is, as your ‘adventure’ here has highlighted, a required need to have a two drive failure. And my writing/updating of that ‘backports’ HowTo more recently was influenced by this need and some inquires as to our moving in that direction. We definitely need to be offering, or at least surfacing after manual conversions, the likes of the mixed raid. I’t always been planned, but we are now getting to the stage where we can add such things, and btrfs also, now has these even newer (bad) but based on the oldest (better) raid1c3/4 raid levels but just with 3 and 4 copies instead of the prior default of 2 copies (all across the same number of independent devices).
Yes, me too. I myself ran several years worth of multiple FreeNAS (BSD base at the time) instances, some on a 24 hours availability.
So given that 'Backports HowTo" a good couple of reads and keep it seriously in mind for your 48 TB array which will presumably have many disks. We will definitely need tester and I’m full-on now with preparing our re-release of the testing rpms. And that would be the way to go there. As we can only roll out quickly to the testing branch/channel, but only once I get it ‘sorted’ again. So I’ll get back to that.
Good to have your feedback here and hope things work out better for you this time. And note also that the “Backports HowTo” only uses stable backports from openSUSE’s upstream, not cutting edge. So although it moves clearly into the advanced users only territory, it’s not untested bleeding edge, just released stuff. But we will need to catch-up on-the-fly, and we will need detailed reports of ‘findings’. This after all, is what our testing channel is partly about. In time, the default Leap (or whatever) kernel will also offer these newer (based on older) raid levels. And the mixed raid thing is a key btrfs capability re really should at least be indicating already within the Web-UI. Even just to remind those who have done such by-hand tweaks that our balances may inadvertently undo such settings. But as a heads-up, our very first testing release as part of our newly branch based approach to the update channels, will have a newly added command line balance aware capability. That is at least the beginnings of improving our stance on greater compatibility/flexibility all around. So then, if one is forced to do command line balances (on custom mixed raid pools) due to our not yet being mixed raid aware, at least the to-be-re-released testing variant will know it’s going on in the background.
That sounds very promising. Yes I was reading up on the new raid combinations with the raid 1c options. It seems as though those would be a little more stable from what it looks to me. I’m all for testing for you and doing whatever you may need me to do. I should have that rig in the next week or so. We are retiring a Netgear readynas rack mount with 12 bays and full of 4Tb drives. It’s perfect for this stuff as it has a regular motherboard and one SATA port for a boot drive. No hardware raid controller in it.
I will take a look at the documentation you posted. If the backports are more “official” that will be the way to go. My concern with making raid 5 or 6 work was that I was afraid there wasn’t gonna be a ton of willingness for people to help sort out a problem I created and was generally discouraged!
So that said if I can test out functionality you are actually wanting to implement that would be the way to go. I’m not a stranger to Linux at all. My main rigs, as well as my work rig has been Linux for many years. So the cli tends to be our friend when they are your main drivers.
That’s said testing for you would be a nice project to get into. What I can do is when I get the Nas I’ll set it up ideally how you’d want it for testing purposes. I’m not in want for space as of yet but it will eventually become my main storage as I’m trying to retire some of my big servers that are power hungry. So once we get it fairly stable after running for quite some time without a catastrophy I’ll begin to move some things.
Looking forward to it. If you need to move this thread you may want to as the original issue really has nothing to do with the ongoing conversation here.