@GambitZA Welcome to the Rockstor community forum.
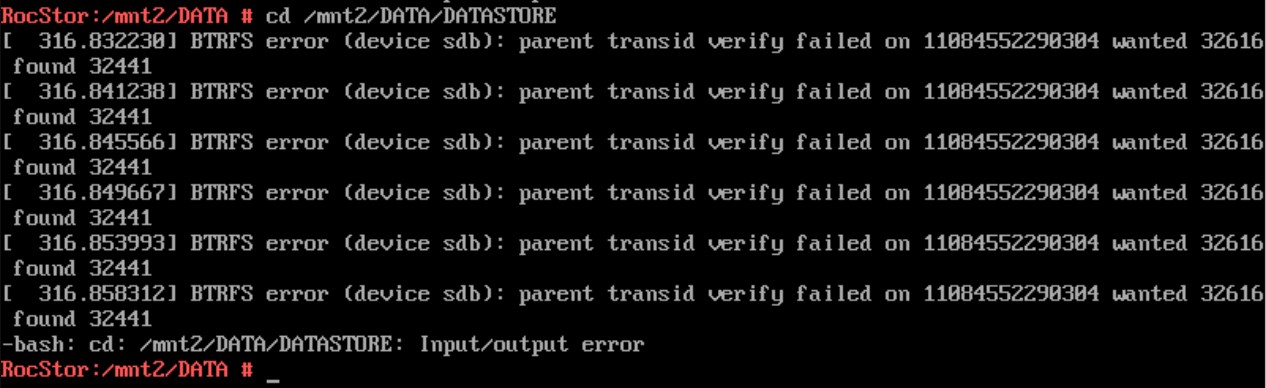
Oh dear, this is usually an indication that some writes were lost in transit or the like. I.e. it wants (expects) a newer copy of something but was pointed at what looks like an older copy.
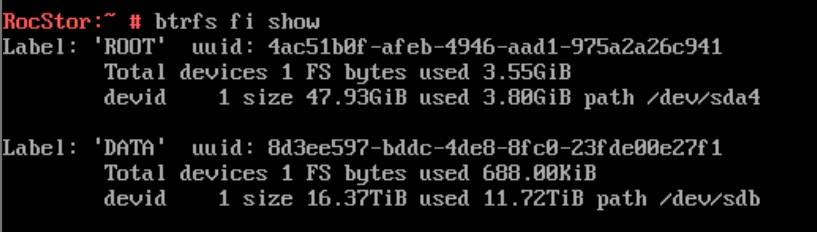
So in short the pool is poorly.
If you have a read-only mount you can refresh your back-ups (or create them) as it may be there is little to nothing of consequence missing. The auto read-only ‘move’ on btrfs’s part is to protect the filesystem (Pool) from further damage. So copy off what you can before you do anything else. As it may be any attempt to repair this pool will end up worse of than it is now. For example if the RAM in the system has caused this corruption, things will only get worse. But they are safer now it’s read-only. Or if there was a kernel hang that prevented a write, or a write was lost some how (drive buffers not flushed etc - say via drive firware issue) or via a failing drive. Whatever the case, you at least now have read-only access, so do all you can with this before proceeding to to anything else.
You may find all is well with the important data. The you options are far more open, i.e. you can wipe the pool, recreate a fresh one, re-load the data; knowing that it is now not the only copy (if that was the case initially). So if the same thing occurs or the same root cause causes some other failure you are still good, or at least better than now.
So the above is mainly advise on what to do to minimise the loss. But we are not btrfs experts here, we are more users / sysadmins. The actual experts are the developers, and for this I can point you to the following doc entry we have on contacting them:
“Asking for help”: Data loss - prevention and recovery in Rockstor — Rockstor documentation
If you are already knowledgeable in btrfs and system administration, see the upstream community Libera Chat - #btrfs channel. Finally, if your needs are extreme, consider seeking help on the btrfs mailing list.
With the following proviso there also:
> The btrfs mailing lists is primarily for btrfs developer use. Time taken-up on trivial interactions there may not be fair to the world of btrfs development. Also take careful note of what you are expected to include: i.e. the “What information to provide when asking a support question” section on the above linked mailing list page.
A further note, once you have all data that you can backed up, is to use a newer kernel. You are likely still using Leap 15.3. However our downloads page:
https://rockstor.com/dls.html
now has Release Candidate 4.5.5-0 Rockstor installers based on Leap 15.4, which in turn has a newer btrfs software stack (kernel and userspace). But note we have an ongoing/outstanding issue regarding import of config saves. But an install of this, to another system disk (disconnect the original 4.1.0-0 Leap 15.3 based one) to preserve your existing system, gives easy access to a newer system under which you can do any repairs if you end up taking that route (after refreshing backups).
We also have the following how-to that enables kernel backports to the base Leap 15.3 OS:
Installing the Stable Kernel Backport: Installing the Stable Kernel Backport — Rockstor documentation
which will also update both the kernel and filesystem subsystems to get any newer code that may help with the repair that you may end up undertaking.
But the first step must be to save what you have given you at least have read-only access, so should be able to pull off likely the vast majority of the data that concerns you: via a back-up copy-off.
Let us know how it goes, but don’t change anything before establishing a backup. Super important as there is no guarantee any repair, irrespective of the OS or kernel version will not make things worse; especially if the underlying hardware is failing/faulty.
Re info to help others help you, the output of the following (run as the root user) could help; hopefully.
uname -a
btrfs fi show
And note these will change if you end up updating, re-installing with RC2, or doing the stable kernel backports. In some cases thought, an older kernel will mount a pool that a newer kernel will not: due to the greater number of sanity checks added as btrfs is developed. But a newer kernel is favoured in repair scenarios. But every mount attempt could, especially by differing kernel versions, runs the risk of modifying the filesystem so that it doesn’t even mount read-only. Hence advising that you first get off what you can as you still have read-only access.
Hope that helps. And let us know how you get on.