@eetheredge806
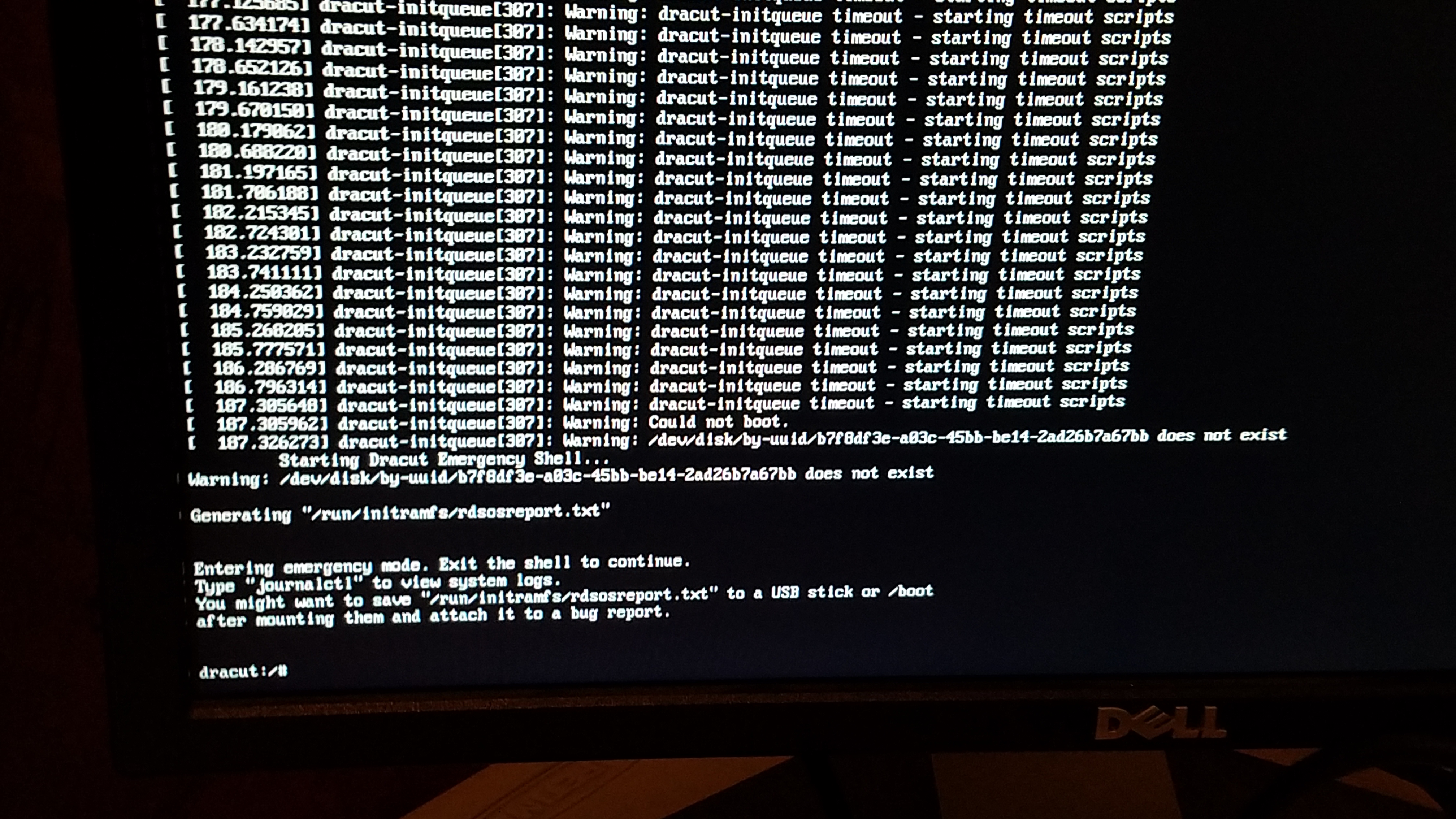
It means exactly what it is stating. There at least appears to be a whole disk btrfs file system as indicated by lsblk (Rockstor’s default pool arrangement is whole disk) and so this message it to indicate that state and block it’s use in other pools.
That is not necessarily the case. Btrfs will refuse to mount an unhealthy volume and there are several ways to mount that volume even if it is damaged. And then still other procedures to recover undamaged info even if a mount is not possible. But no one here, or anywhere else, can inform you unless you give us some information about this volume. And one place to start would be by answering the question I asked of you previously.
Please answer this question (the command must be run as root on a local Rockstor terminal or via a ssh session to your Rockstor) and you may then at least be helping others help you from a more informed stance.
I as referenced there is a know issue with regard to mounting via label and if may just be that. You could also manually mount the volume but you really need to answer the given question so that others can help. We don’t even know if this was a multi disk pool (volume) I’m just assuming this for the time being as that is usually the case.
Do not wipe this or any other disks (if there are any which has yet to be established in this thread: hence the command output request) and do not attempt any repair. Currently there is actually no indication of an actual corruption (see my FAQ reference again) and a manual mount is also entirely possible and I and many many others on the list can help with that but not until you answer the given question.
To to clear: my understanding of your current scenario given this threads info is that you had a lighting strike and lost a system / or system disk. This seems to have been indicated by your transferring that system disk to another system and it failing. Presumably you re-installed Rockstor successfully, although we don’t know your exact version:
yum info rockstor
will tell us that (ignore the Web-UI for this info for the time being) that command gives the canonical truth of the matter. Assuming you haven’t build from source code that is.
The current road block is not informing the list of anything about your data pool. Please try and help us help you as without any information some advise is best not given as it can cause more harm than good.
Let us know the full story and everything you have tried so far. For instance did you re-install and were you absolutely sure you didn’t re-install over one of your data disks. Incidentally, even if you did and there were at least 2 disks in a raid1 all your data may still be retrievable: even without a mount but we must have some initial info and a record of what happened.
Yes that would have be nice but but we can only go from here for the time being. Although the replication feature is one you may be interested in, in the future: ie auto replicating a share from one Rockstor machine to another on a interval basis.
Hope that helps and lets see if the forum and yourself can methodically work through this. It may just be that you need to mount degraded but again this is potentially dangerous info as if you attempt it, you may only get one shot at mending the pool. But again, to stress, this depends on the raid level (ie raid0, raid1 etc) and the number of disks remaining in the pool: which the first command above should tell us.
Please also let the forum know if my requests are inappropriately pitched. That is are you able to get a local terminal or a ssh session into this box for example.
So in short I wouldn’t loose hope just yet as by default btrfs avoids mounting damaged or degraded (missing devices) volumes but this may still be a simple known quirk which we can get around but only with the requested information.
Thanks.