I have been using Rockstor stable for more than a year. My old Dell Poweredge 1800 (dual 2.8ghz xeon) 2Gb Ram Vertex 2 120gb SSD system with a mixture of sas and sata storage drives on an LSI 9201 16e HBA in JBOD mode). Suddenly starts running out of ram in 7 min from time of boot. It had been up solid for 110 days until this morning. After a lot of messing about with the original ssd boot drive, I started fresh with a different vertex 2 SSD and installed and updated to the latest rockstor 48. including running all yum updates.
On the fresh install, I left Rockons off and the only thing I customized is setting up my mellonox 10gbe adapter. So this installation is as simple and as fresh as I could make it. I can watch in htop the ram slowly filling up… It is very frustrating because I only have about 5 minutes to troubleshoot each time i boot. I can’t see any specific process in htop that is using all the ram, but the meter goes up and crashes at 1.86gb used. Swap is setup and I can see it minimally used.
I was just able to stop the system from crashing by disconnecting and unmounting my 8tb drive (all others already disconnected) I have found out atleast my 8tb seagate drive being present is initiating this. using free -m i found out all the ram (1700mb ) is tied up in buffers and caches. Now why is my system suddenly buffering like this? I haven’t done a single file transfer since reinstalling rockstor. at one point this seems to have coincided with me opening the samba share on my windows computer, but other times I never opened a windows file manager and it still happened.
So how do I figure what and why of caching / buffering until ram is full? and kernal panic.
I’ve looked through a lot of logs. dmesg, rockstor, and more, but not sure i saw anything conclusive maybe i just don’t know what i’m looking for.
i’ve also tried
# echo 3 > /proc/sys/vm/drop_caches
which did nearly nothing… so that means caches are dirty? i’m over my head in understanding this, but i’ll keep digging.
Update: I now can say that the old and new rockstor install work without my 8tb drive connected. All the other pools are connected and stable.
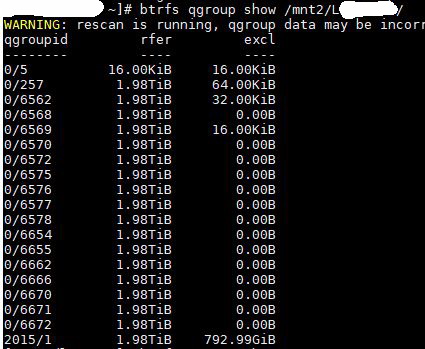
Update: Here is an excerpt from dmesg: maybe a quota rescan is causing memory usage. I use snapshots but only have 1 subvolume on this particular disk. i don’t remember messing with quotas one way or another. the following messages appear when i unplug drive (not ideal, but the server is going to crash anyways if i don’t unplug)
INFO: task kworker/u8:1:30610 blocked for more than 120 seconds.
[22611.072819] Not tainted 4.12.4-1.el7.elrepo.x86_64 #1
[22611.072921] “echo 0 > /proc/sys/kernel/hung_task_timeout_secs” disables this message.
[22611.073046] kworker/u8:1 D 0 30610 2 0x00000080
[22611.073125] Workqueue: btrfs-qgroup-rescan btrfs_qgroup_rescan_helper [btrfs]
[22611.073130] Call Trace:
[22611.073145] __schedule+0x28a/0x880
[22611.073152] schedule+0x36/0x80
[22611.073197] wait_current_trans+0xc7/0x100 [btrfs]
[22611.073204] ? remove_wait_queue+0x60/0x60
[22611.073249] start_transaction+0x28a/0x440 [btrfs]
[22611.073295] btrfs_start_transaction+0x1e/0x20 [btrfs]
[22611.073343] btrfs_qgroup_rescan_worker+0x83/0x5a0 [btrfs]
[22611.073394] normal_work_helper+0xc0/0x2f0 [btrfs]
[22611.073443] btrfs_qgroup_rescan_helper+0x12/0x20 [btrfs]
[22611.073450] process_one_work+0x149/0x360
[22611.073455] worker_thread+0x4d/0x3c0
[22611.073459] ? _raw_spin_unlock_irqrestore+0x15/0x20
[22611.073464] kthread+0x109/0x140
[22611.073468] ? rescuer_thread+0x380/0x380
[22611.073471] ? kthread_park+0x60/0x60
[22611.073477] ? do_syscall_64+0x67/0x150
[22611.073481] ret_from_fork+0x25/0x30
[22611.073536] INFO: task btrfs-transacti:2151 blocked for more than 120 seconds.
[22611.073659] Not tainted 4.12.4-1.el7.elrepo.x86_64 #1
[22611.073758] “echo 0 > /proc/sys/kernel/hung_task_timeout_secs” disables this message.
[22611.073881] btrfs-transacti D 0 2151 2 0x00000080
[22611.073887] Call Trace:
[22611.073894] __schedule+0x28a/0x880
[22611.073899] schedule+0x36/0x80
[22611.073945] btrfs_commit_transaction+0x7f3/0x900 [btrfs]
[22611.073949] ? remove_wait_queue+0x60/0x60
[22611.073994] transaction_kthread+0x18a/0x1c0 [btrfs]
[22611.073999] kthread+0x109/0x140
[22611.074044] ? btrfs_cleanup_transaction+0x520/0x520 [btrfs]
[22611.074048] ? kthread_park+0x60/0x60
[22611.074052] ? do_syscall_64+0x67/0x150
[22611.074055] ret_from_fork+0x25/0x30
If rescanning quotas is properly taking up ram, then how much ram does this process need? I have 8gb of ram ordered.
So I see rockstor says quotas are disabled on this particular drive. is this a problem with having snapshots?. i started taking regular snapshots several months ago. What would the implications of trying to turn quotas on?
thanks,
Darrell