I click on anything and it takes several minutes to show the page that should be shown. even clicking logout takes over a min to do anything. sometimes even bringing up the logon screen takes forever. this i a vm on a dell r730, its got 30 cores and 32gb ram. latest testing update, all zypper packages are up to date. ive passed through my hba730 controller, which is working great. please tell me which logs would be helpful, its a lot to go through and I dont have a lot of time.
@jihiggs
can you tell whether there is a (or multiple) CPU process(es) consuming all your CPU using the top command?
I would look for error entries in the rockstor log.
Finally, you could also check out via the web browser development console whether there’s a connection issue or other errors reported … also assuming the slowness is the same on a different browser?
1 Like
this is typical usage doing nothing

, I just got this message waiting for the dashboard to come up. I may have clicked shares, I dont recall. its doing this from 3 browsers and another browser on a vanilla windows 10 vm on the same hypervisor the rockstor is installed on. (proxmox)
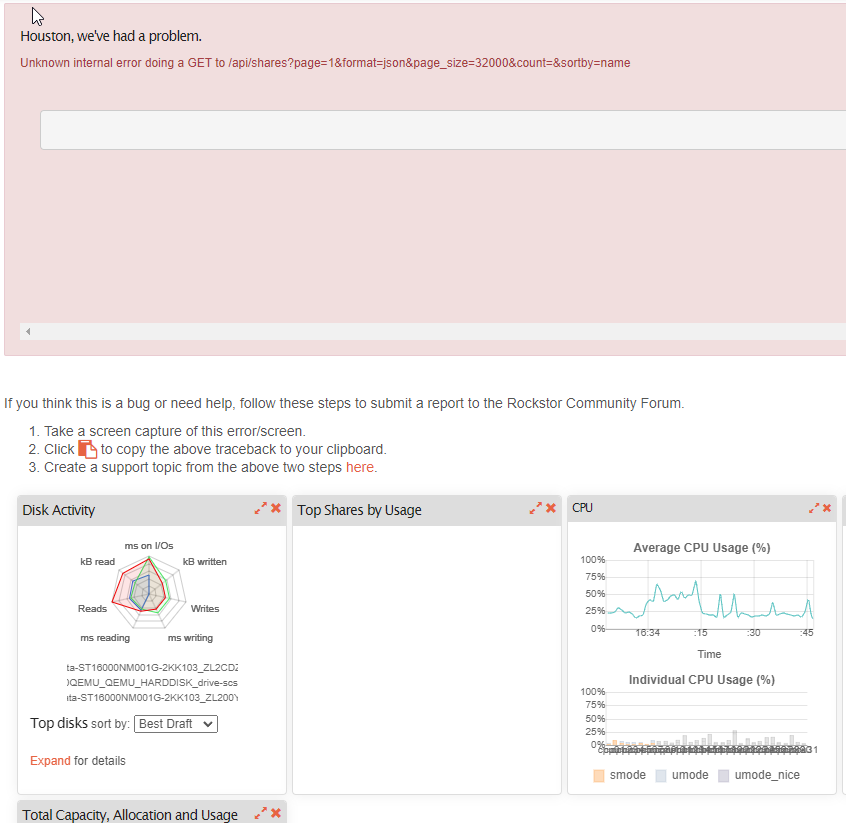
just got this pop up
log files for your enjoyment
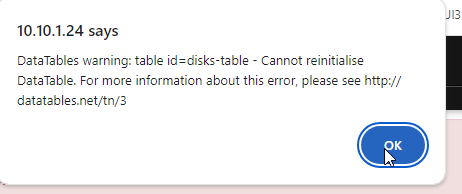
this one is unrelated - this has been an ongoing issue since 3.x, mostly related to the now stone-aged javascript libraries that we have. Usually, a browser refresh should fix that portion, but not affect performance.
Interesting that gunicorn is doing stuff while doing nothing. I think we’ve had seen some type of racing condition at some other point, but can’t remember when right now.
@Flox and @phillxnet any further recommendations?
I can see in the rockstor.log some references on 1/9/24 around postgres connection issues. There is one exception today related (in that log at least) to a connection being already closed. I assume, you’ve rebooted at least between yesterday and today.
On the nginx error log I see many error messages, without knowing what they indicate (sorry for my ignorance). Comparing it to my system on the stable version, the last time I had some similar errors of failed connections in mid-December and nothing at this scale.
On the gunicorn error log I can see some warnings around DateTimeField format related to Poolscrub.eta but not sure whether that would cause this CPU consumption level you’re seeing. I suspect those error messages are also a couple of months old (would be good if there was a date/time stamp on the gunicorn entries, too).
In the standard gunicorn log there is mentioning of the data-collector which we’ve had some issue with a long time ago (CentOS days):
but that does not seem to be the issue here, as it doesn’t show up as the top-consumer …
2 Likes
cant say what happened to this vm. all I ever did was install a jellyfin rock on, it was running fine for months. then started being a pig with resources and got slow as hell. now the web ui wont even load. time for a new vm.
1 Like