My first terabyte drive (/dev/sde) is biting the dust and shall be euthanized soon. I’ll retire the rest of Pool2’s drives at that time and add a new 3.6T drive to Pool1.
The plan is:
Drop the Samba share associated with Pool2
Delete Pool2
Shut down, remove drives sdg, sde, sda, and install the new drive.
Power up (and hope that sdb is still sdb, since that is my OS)
In Rockstor, import Pool1 if necessary.
Verify that shares, Samba shares, and Rockons are still there.
6a. Whine, cry, and crack open a bottle of Aberlour 12yo double barrel if they aren’t there.
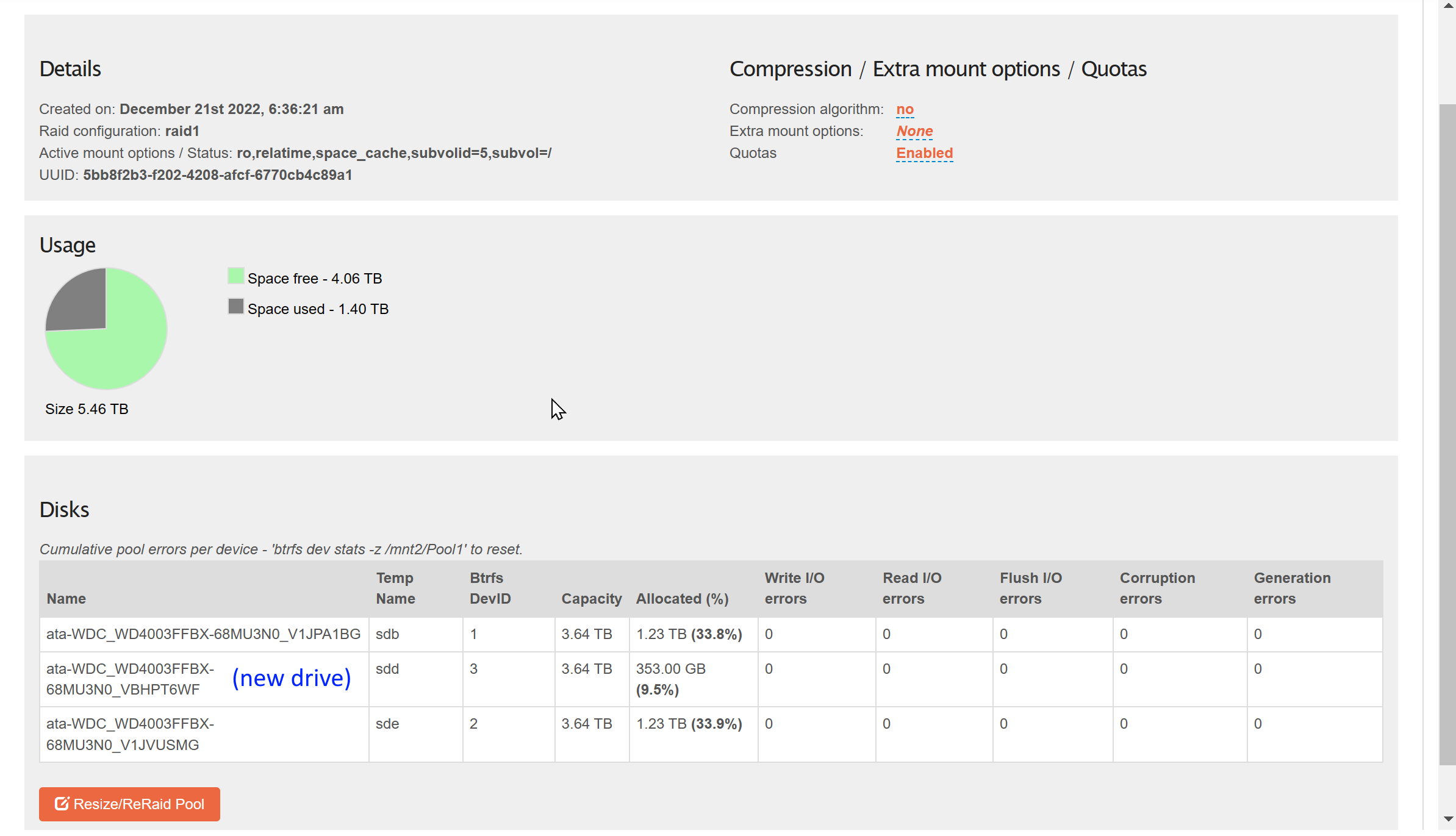
Add the new drive to Pool1.
7a. Celebrate by cracking open the aforementioned bottle of Aberlour.
I suspect that when I remove sdg, sde, and sda and insert a new sd that my dear friend Linux will reassign the drive designations. With luck, sdb will still be sdb since that is my OS.
So there’s the rub… I imagine that Linux will reassign drives: sdc and sdf may no longer be sdc and sdf once I remove and add drives. I think btrfs will figure that out and Pool1 will still exist. Am I right? Are there any other “gotchas” that I may need to look out for?
Note 1: Pool2 currently contains backups of certain things on Pool1. I’ve got that functionality covered elsewhere so I am not worried about data loss from Pool2.
Note 2: I’m on Rockstor 4.1.0 and OpenSUSE 5.3.18-150300.59.101-default (patched up as of a few days ago).
@wdc, I would tend to think that by deleting/destroying pool1 before removing the disks, you should be in good shape. Since Pool2 and its disks are not affected by it, and you have removed the Pool1 mapping from btrfs, you should be just fine.
I would also not expect you to require to re-import Pool2 after restarting the system once you’ve physically removed the old disks that comprised Pool1. At that point they are only “devices” but not associated with anything anymore.
I would also think you can add the new physical drive device at the same time you remove the other disks (not sure whether that was your plan anyway). It should then show up as an available device that can be added to your existing pool.
Good luck with getting to the “crack open a bottle of Aberlour”
@wdc Hello again. Just wanted to chip-in on this:
Re:
You can always setup a ‘toy’ vm with a similar drive arrangement. Not the same I know as it has idealised behaviour in many cases. And often far more stable canonical drive names. Also I wouldn’t worry about changing canonical (sda, sdb etc) drive names. That has been a think for many years now. It used to be defined by connection order but for a few years they can change from one boot to another. Around the time of the early NUC’s this came to light more and upset some setups. Internally rockstor uses predominantly by-id names which are intended to serve the purpose of reliable naming. But if a drive is moved from one bus to another these also can change. The boot drive changing canonical (sda etc) names over power cycle is a matter for the bios. Once booted you are in kernel land obviously and form rockstor’s perspective the by-id names should be stable enough. It’s why we use them. Way back in the early days of rockstor development we did use the canonical names, but that was a long time ago now.
And yes, the btrfs subsystem recognises drives by a uuid stam unique to the filesystem, and an increasing drive id associated with the pool, so is independent of drive names. We likely still have some bugs here and there but I don’t think there are many show stoppers left in that department. Especially given the source of truth there is the btrfs show etc commands that we parse read the system state. We have some irritating bugs left in the department of ghost pool entries but we should get to those soon, once we’re done with the rather large build system replacement we are currently engaged with. We also have to improve our system drive partition management to be more in line with how we do it on the data drives.
Hope it goes well and as always keep us informed of how it goes. Always a good test of the system when major changes have to be undertaken.
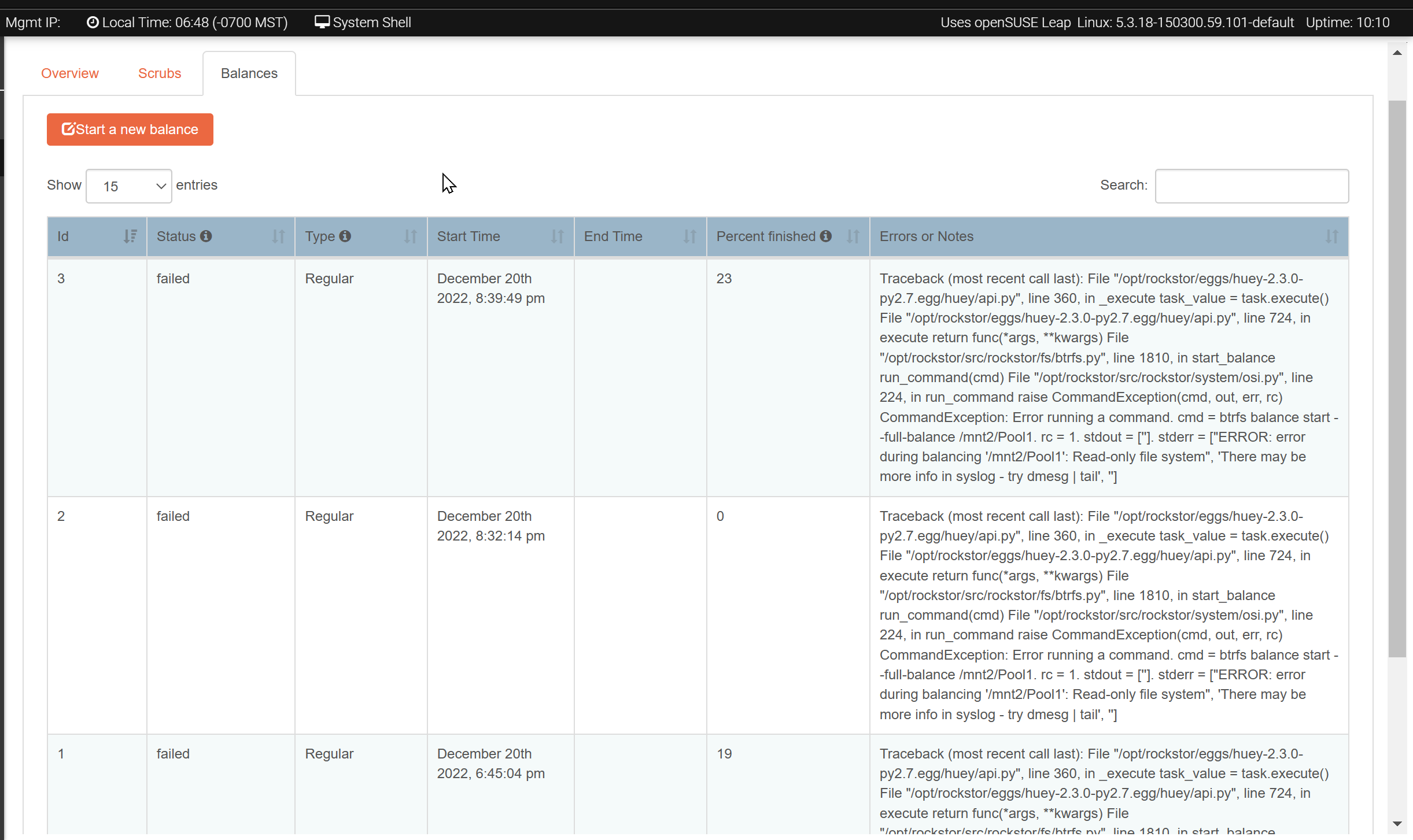
Perhaps the celebration was premature. I ran into an error when adding the new drive to the pool, no change in RAID level (RAID 1). The pool is now read only.
In this case (and given the failed balances), would you suggest running a scrub?
The problem is as follows:
Balance fails with this message:
Traceback (most recent call last): File “/opt/rockstor/eggs/huey-2.3.0-py2.7.egg/huey/api.py”, line 360, in _execute task_value = task.execute() File “/opt/rockstor/eggs/huey-2.3.0-py2.7.egg/huey/api.py”, line 724, in execute return func(*args, **kwargs) File “/opt/rockstor/src/rockstor/fs/btrfs.py”, line 1810, in start_balance run_command(cmd) File “/opt/rockstor/src/rockstor/system/osi.py”, line 224, in run_command raise CommandException(cmd, out, err, rc) CommandException: Error running a command. cmd = btrfs balance start -mconvert=raid1 -dconvert=raid1 /mnt2/Pool1. rc = 1. stdout = [‘’]. stderr = [“ERROR: error during balancing ‘/mnt2/Pool1’: Read-only file system”, ‘There may be more info in syslog - try dmesg | tail’, ‘’]
dmesg shows the error to be on one of the original drives, not the new one:
[ 6050.760307] BTRFS: error (device sdb) in __btrfs_free_extent:3111: errno=-2 No such entry
[ 6050.761324] BTRFS info (device sdb): forced readonly
[ 6050.762342] BTRFS: error (device sdb) in btrfs_run_delayed_refs:2147: errno=-2 No such entry
[ 6050.764512] BTRFS info (device sdb): balance: ended with status: -30
The first balance was triggered by the system when adding the drive. The second 2 were manual, with a reboot in between the second and third.
Yes, btrfs is fond of going that way whenever there is a problem, with the intention of not proceeding if there is doubt.
I think so, however the on-going balance is throwing the pool into read-only so you may have to add an extra mount option of “skip_balance” and then reboot to get the pool back into rw. Whenever a pool is mounted it will continue an incomplete balance and in your case may well then run the pool into a ro state again when it re-encounters the problem area. But as always ensure all back-ups are refreshed before doing anything at all if possible, given you currently have access, all-be-it to a pool that is half balanced. But the dive has now been added to the pool, it’s just mid-balance.
You need to return rw for scrub to be able to sort things out (after back-up refreshes if need be). Also note that sometimes a newer kernel can help (but it can also hinder) so just noting this if your options narrow. I.e. our:
“Installing the Stable Kernel Backport”: Installing the Stable Kernel Backport — Rockstor documentation
But that is for later down the line as a scrub after “skip_balance” mount option and reboot may well see the pool sorted again.
Yes, btrfs is fond of going that way whenever there is a problem, with the intention of not proceeding if there is doubt.
A feature that I really appreciate.
add an extra mount option of “skip_balance”
That I did not know so thank you. I’ll certainly need it.
I’ll give it a try tonight. Tomorrow will be -20 degrees Fahrenheit (-29C for my friends on the east side of the pond) so I may or may not have time, depending on the condition of my pipes - and the day job that gets in the way of fun stuff.
Two scrubs later - both with 0 errors - still can’t balance.
I recall having had problems with snapshots in the past so I deleted them all (doesn’t matter- I’m happy with my backups). But now I’ve discovered that some still exist even though they aren’t listed in the Rockstor UI.
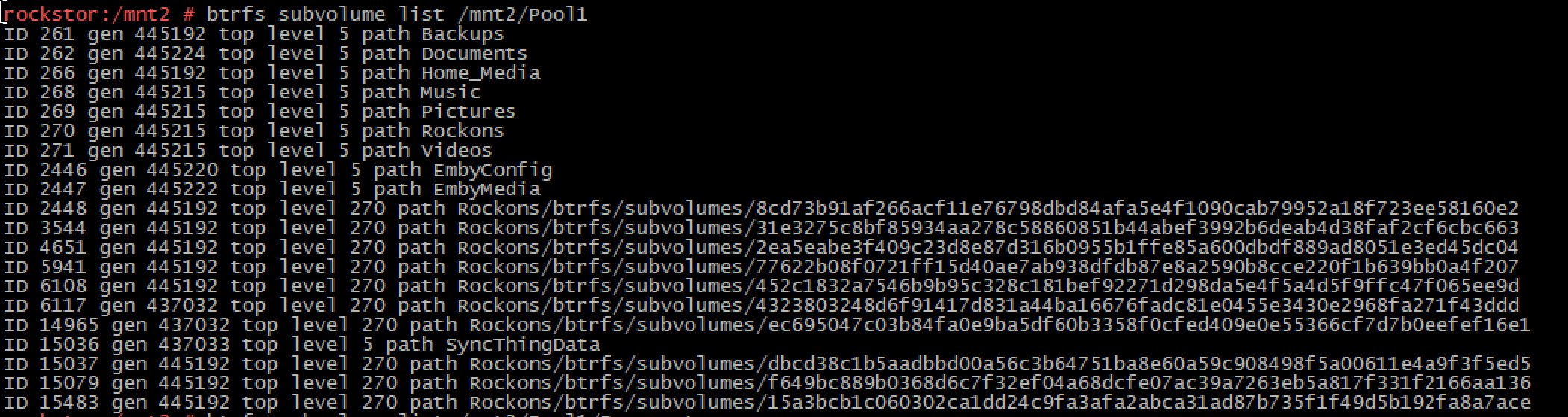
I’ve read some about deleting snapshots and that they are subvolumes in btrfs ("btrfs subvolumes list doesn’t list them).
P.S., I’m considering dropping / recreating the whole Pool1. Not a pleasant thought.
Is there a right/wrong way to delete these? (can I just rm -R them?)
P.P.S, sorry for the tone here - just getting a bit frustrated with it.
Rockstor takes a Rockstor-limited view on btrfs things, and basically mostly ignores things like snapshots that are not in the location it would have put them. So it’s entirely possible to have btrfs subvolumes that are entirely hidden by Rockstor. There also remains some corner cases where subvolumes of say a clone or a subvolume that has been reverted to a snapshot to leave now orphaned (from a Rockstor Web-UI perspective) subvolumes. We just don’t account for all of what btrfs can do yet. This is part of our make-it-easy when it isn’t approach. I.e. to limit our focus to the core facilities that most folks will use. But there is a tone of arrangements that are just not how we do things, and as mentioned, some cracks where subvols can disapear. Also some where we surface them in a confusing manner, i.e. snapshots created by docker for example. And the ones you see here appear to have been left over from Rockons (a docker wrapper), or docker images that in turn generate their own subvolumes that are outside the ‘vision’ of what our Web-UI can currently see.
Take a look at that upstream doc to see who you might do a clean. We source/run btrfs commands to read what we can understand from the pool, so you should be OK to clean up as needed via btrfs commands. Just take extra care when moving stuff.
Incidentally, in the above upstream doc you may need the following filter:
Type filtering:
-s only snapshot subvolumes in the filesystem will be listed.
It may just be that you don’t in fact have any snapshots just subvolumes created by the Rock-ons/docker. That my guess (but getting late here now), also take a look at this rockstor-doc issue we have pending:
And play with the subvolume filters to know more what is being listed.
Our own various uses of the subvolume command, and the options we use, are available in the following file:
My original goal was to remove a set of old drives and add a new one. One of them began logging read errors in SMART and the other two were just plain old (one was IDE - remember IDE?). Rockstor worked like a champ for this.
My second goal was to add the new drive to the existing RAID1. This flopped because of an error in the file system:
2022-12-22T18:01:35,556263-07:00 BTRFS: error (device sdb) in __btrfs_free_extent:3111: errno=-2 No such entry
2022-12-22T18:01:35,557266-07:00 BTRFS info (device sdb): forced readonly
2022-12-22T18:01:35,558287-07:00 BTRFS: error (device sdb) in btrfs_run_delayed_refs:2147: errno=-2 No such entry
That error prevented completion of a balance and prevented removal of any drive from the pool. The final solution was to delete the pool, format the drives (even that took 2 tries), build a new pool, restore files from backup, and re-setup Rockons.