I run a monthly scheduled scrub job on the first of each month at 02:36 am
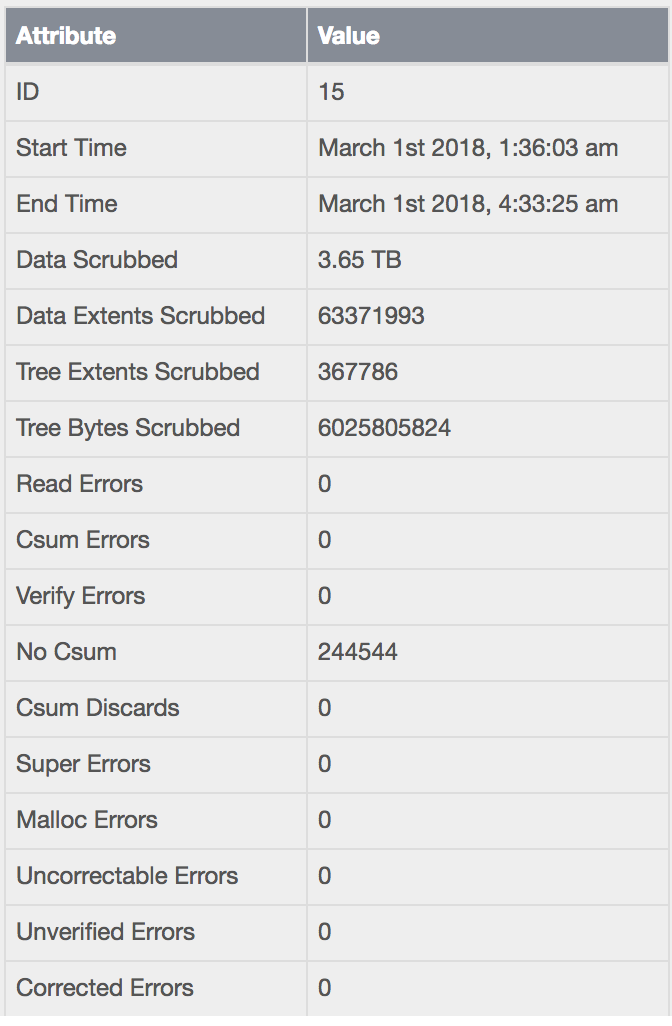
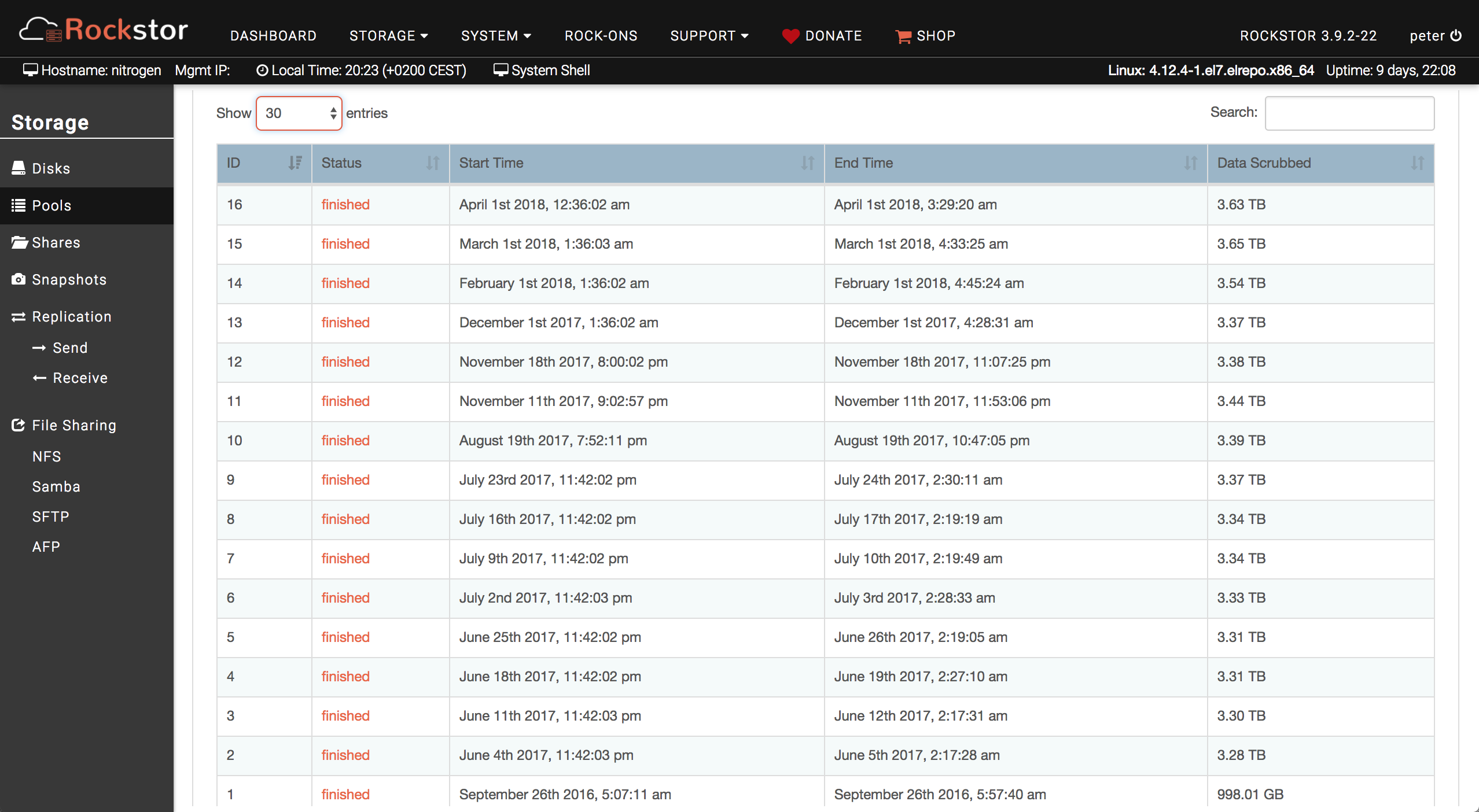
If I navigate to Storage>Pools>Pool-1 and then go to the scrubs folder, I can see there has been 16 scrub jobs run (either manually or with my scheduled task). All 16 terminated with exit status finished. They all have consistent run times and the details are also consistent.
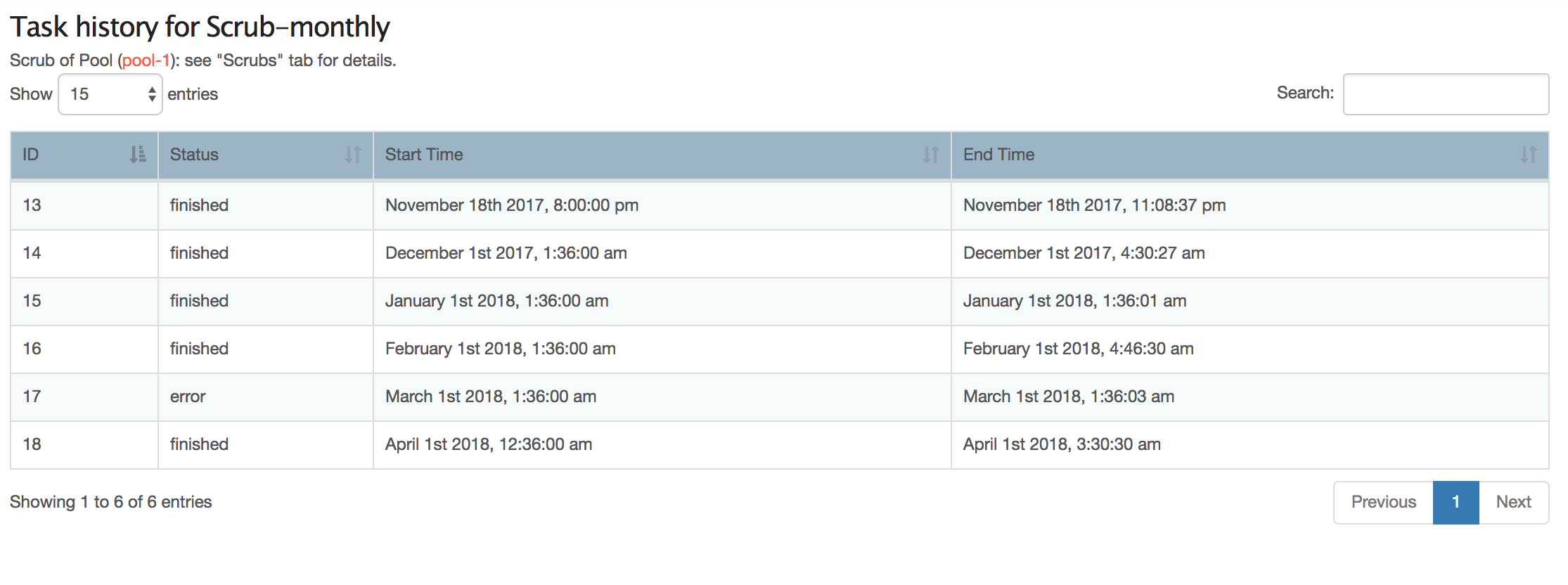
If I navigate to System>Scheduled tasks and open up task history I see a list of 6 entries (numbered 13-18(?)) that was started with the current scheduled task. However, one (March 1) finished - according to this list - with exit stats error and a run time of 3 seconds!
I find it somewhat amusing that a task can be both finished and not!
There are additional, cosmetic issues here; I believe you set up the scheduled tasks using UTC but both these forms seems to display local time which is somewhat confusing; and they have different default sort order if you really want to go into the nitty-picky stuff
I know weird numbering, anyway moving along
Of note here is that there have been, in total, 18 scheduled tasks.
Note: my addition in brackets.
So what we have here is a scheduled task that for whatever reason thought it failed to initiate it’s associated scrub.
I.e. the scheduled task history is for the tasks: hence the reference to the scrub record for the pool, also note the difference in begin / end times between task and it’s subsequent scrub.
Well you do have a point, as the indicated task failed yet it’s March 1st scrub succeeded.
All in it looks like we have a false fail recorded on the task, even when it’s subsequent scrub succeeded. Oh well at least we failed in the right direction.
Nice find and thanks for reporting. If you could dig up some logs by way of a pointer from that time / or the email you received upon the failed task, assuming you had email notifications enabled, it might help with defining an issue as otherwise it is as you say rather there and not at the same time.
Thanks for the thorough and entertaining report and we definitely also have some aesthetic improvements to be made, ie up-side-down task history table, to UTC or not to UTC and the like.
I have had such a one myself. I did notice that the task was marked as failed, but the scrub did complete without errors. But as everything worked as expected, an every single of the 107 other scheduled scrubs my system has made have not reported any errors, I just wrote it off as a freak occurrence.
@KarstenV Thanks, this is good to know. At least we know it’s ‘a thing’. All we need now are some logs / email notifications to give us a clue why the task fails yet it’s associated scrub succeeds.
Quite a strange one that would be good to sort.
Cheers for confirming @peter’s findings. We could open an issue once we get some kind of a clue as to why it’s happening.
@phillxnet I believe we can agree that we at the most have a whisker of a dead or alive cat!
Found this in the Rockstor log:
[01/Mar/2018 02:36:03] ERROR [storageadmin.util:44] exception: Error running a command. cmd = /sbin/btrfs scrub status -R /mnt2/pool-1. rc = 1. stdout = [’’]. stderr = [‘WARNING: failed to open status file: Resource temporarily unavailable’, ‘’]
Traceback (most recent call last):
File “/opt/rockstor/src/rockstor/rest_framework_custom/generic_view.py”, line 41, in _handle_exception
yield
File “/opt/rockstor/src/rockstor/storageadmin/views/pool_scrub.py”, line 74, in post
ps = self._scrub_status(pool)
File “/opt/rockstor/eggs/Django-1.8.16-py2.7.egg/django/utils/decorators.py”, line 145, in inner
return func(*args, **kwargs)
File “/opt/rockstor/src/rockstor/storageadmin/views/pool_scrub.py”, line 55, in _scrub_status
cur_status = scrub_status(pool)
File “/opt/rockstor/src/rockstor/fs/btrfs.py”, line 1158, in scrub_status
File “/opt/rockstor/src/rockstor/system/osi.py”, line 121, in run_command
raise CommandException(cmd, out, err, rc)
CommandException: Error running a command. cmd = /sbin/btrfs scrub status -R /mnt2/pool-1. rc = 1. stdout = [’’]. stderr = [‘WARNING: failed to open status file: Resource temporarily unavailable’, ‘’]
Also, one thing to keep in mind; my Rockstor system has been up and running for more than a year and a half, and it is very stable and reliable! Thanks a lot for that and keep up the excellent work!
@peter That great, thanks for digging through the logs. I think I know whats happened here and pretty sure we can work around it. Do you fancy creating a new GitHub issue in the rockstor-core repo indicating your findings and copying in this log entry. If not no worries as I can sort myself in a bit but would be good to have your report there. If you could link back to this forum thread that would also help.
@KarstenV It would be good if you could also dig up a similar log entry as then we will have at least 2 instances of the same thing to work from?
Pretty sure we can just catch this particular ‘non fatal’ warning, log it (just in case), and move along quietly. From what I can remember the scheduled scrub task periodically checks in via that command (having first started the scrub). From the log it looks like it can, on occasions, be overly quick of unlucky in it’s timing. That way we shouldn’t fail the task and can just pickup the status on the next successful periodic checking. Although we may have to build in some kind of a maximum count to avoid getting stuck in what may not be just a transient situation.
Thanks, it’s very much a team effort with this kind of collaboration key to weeding out the rough edges / whiskers. We do have quite a few missing parts as yet and as you point out a bit of polishing to do but things are not standing still. Also the core development team is keen to improve current test coverage which should help with maintaining what function we have while allowing us to moving forward without breaking things, which I at least have no always managed to do.
Thanks for your efforts and encouraging words: hopefully I or someone can sort out a fix when next time allows.
[26/Mar/2018 01:00:07] ERROR [storageadmin.util:44] exception: Error running a command. cmd = /sbin/btrfs scrub status -R /mnt2/RSPool. rc = 1. stdout = [’’]. stderr = [‘WARNING: failed to open status file: Resource temporarily unavailable’, ‘’]
Traceback (most recent call last):
File “/opt/rockstor/src/rockstor/rest_framework_custom/generic_view.py”, line 41, in _handle_exception
yield
File “/opt/rockstor/src/rockstor/storageadmin/views/pool_scrub.py”, line 74, in post
ps = self._scrub_status(pool)
File “/opt/rockstor/eggs/Django-1.8.16-py2.7.egg/django/utils/decorators.py”, line 145, in inner
return func(*args, **kwargs)
File “/opt/rockstor/src/rockstor/storageadmin/views/pool_scrub.py”, line 55, in _scrub_status
cur_status = scrub_status(pool)
File “/opt/rockstor/src/rockstor/fs/btrfs.py”, line 989, in scrub_status
out, err, rc = run_command([BTRFS, ‘scrub’, ‘status’, ‘-R’, mnt_pt])
File “/opt/rockstor/src/rockstor/system/osi.py”, line 121, in run_command
raise CommandException(cmd, out, err, rc)
CommandException: Error running a command. cmd = /sbin/btrfs scrub status -R /mnt2/RSPool. rc = 1. stdout = [’’]. stderr = [‘WARNING: failed to open status file: Resource temporarily unavailable’, ‘’]
[26/Mar/2018 01:00:07] ERROR [scripts.scheduled_tasks.pool_scrub:41] Failed to get scrub status at pools/2/scrub/status
[26/Mar/2018 01:00:07] ERROR [scripts.scheduled_tasks.pool_scrub:43] 500 Server Error: INTERNAL SERVER ERROR
Traceback (most recent call last):
File “/opt/rockstor/src/rockstor/scripts/scheduled_tasks/pool_scrub.py”, line 38, in update_state
status = aw.api_call(url, data=None, calltype=‘post’, save_error=False)
File “/opt/rockstor/src/rockstor/cli/api_wrapper.py”, line 119, in api_call
r.raise_for_status()
File “/opt/rockstor/eggs/requests-1.1.0-py2.7.egg/requests/models.py”, line 638, in raise_for_status
raise http_error
HTTPError: 500 Server Error: INTERNAL SERVER ERROR
Looks a lot like what Peter found, even though not identical.