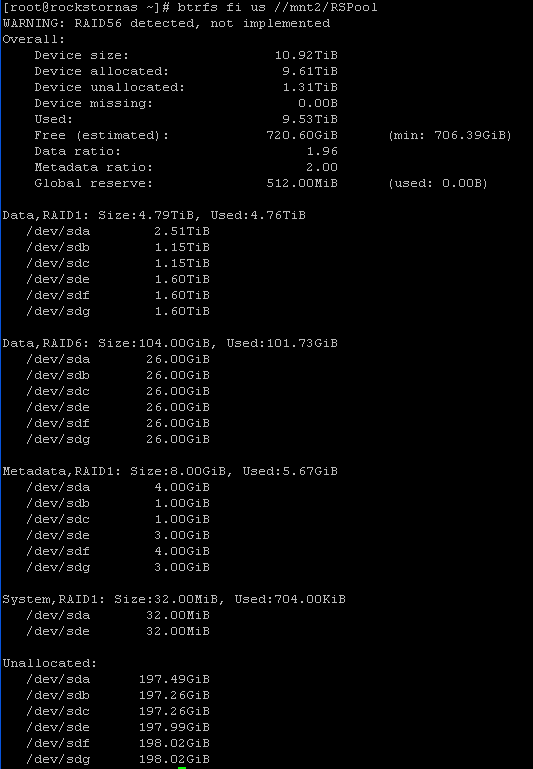
When you start balance from RAID_X -> RAID_Y system takes more of less a virtual snapshot (generation ID) and balances everything from there onwards. If any new data will get written to the system (file access time update is enough) this will be written in old RAID_X scheme.
Be wary that changing raid levels every where else requires you to go offline, so don’t bitch about this technical glitch
You don’t bitch but actually this “no bitchin for glitchin” goes to few “watchers” here that are on crusade with btrfs … because they love zfs but actually can’t live without btrfs
Normally I wouldnt be to concerned about these kind of things, as it would correct itself next time you run a balance. And that should be done “regularly” on btrfs.
But in this instance I wanted to get away from RAID6, so I wanted to be sure everything was converted.
Sad thing is that btrfs hase a VERY HAZY way of determining a data format to be written. So in your scenario you want to convert to raid1 and all data gets rebalanced (up to the specyfic point in time) but while you balance something writtes new stuff to FS - a file update, a metadate change, a access time update … anything - this as I’ve said before will cause stuff to be written in RAID6.
Now, trick with btrfs is that is kinda thinks in allocations chunks of 1GB (let’s stick to this number for ease of example). So lets say you’ve got a data (metadata, pick one you fancy) chunk populated up to 75% … while balancing an update comes in and FS driver looks at the chunk “say, that’s raid6 so incoming data should be raid6” and writtes it as raid6. No balance finally touches this chunk and it will convert a 75% of total data into raid1, because this data existed while balance started … new data will be left alone. So now you will end up with a chunk of 1GB and arbitrary amount of raid6 data inside of it. Next time FS want to write data into this specific chunk, it looks at it and goes “hey there is a raid6 only data here [f*** 4k only but hey] so let’s write new data here in raid6 format” so it will … no let’s say you are very unlucky and you write data of size more than 1GB, so you will extend a raid6 to next allocation chunk … from this point btrfa does not care of what your system actually is and it will care on with raid6 writes.
So, to put it mildly, to move from raidX to raidY be 105% sure that you eradicated raidX from FS !!!
(a side note raid6 has tendency to silently corrupt whole fs so I would copy data somewhere safe, do “dd if=/dev/zero of=/dev/sdX_of_your_choice” and start fresh … that is unfortunate sad reality of data storage, sometime there might be a lurking corruption happening that is not affecting anything until some random update starts accessing it and will cause a “ext4 zero bug” )
Thanks for this very detailed and informative explanation
When I first set up my RockStor, RAID6 was said to be workable, and relatively safe.
And it has worked fine for me, even recovered from a rather nasty crash early on.
But lately news about possible data corruption on the parity disks surfaced, and was proven to be correct. BTRFS can write the wrong parity while writing the correct data.
This will go unnoticed until something fails and the parity data is necessary for reconstruction. Then you are in trouble.
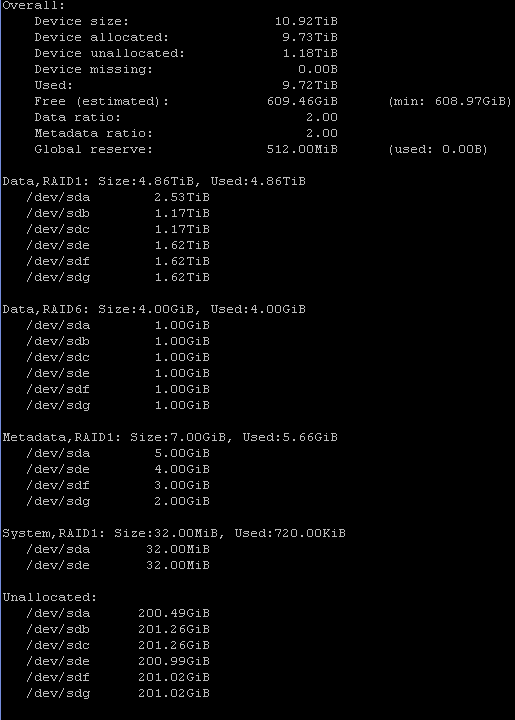
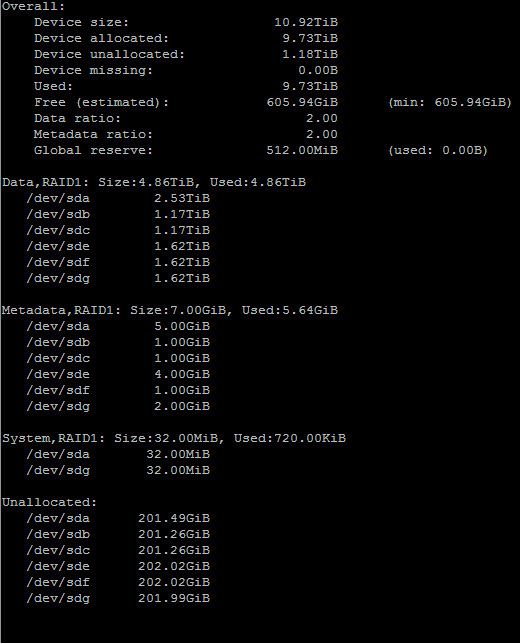
So I decided to move away from RAID6, to RAID1, until the day they deem RAID6 production ready (and seem certain this time). Then I’ll probably go back.
I know work is being done in this regard, but its slow complex work, and I think they want to get it right this time.
I was in luck, my data got converted without problems, and I now have a working RAID1 setup, where all data are converted now. And I havent found or noticed any corrupted files.
I think we can throw you into a very small bag of miracle raid5&6 success stories
( I can’t express how much I wish the raid 6 would work properly! In my setup with 8 drives in pool considering my work load - performance wise it would kick arses and take initials! [who has time for names] )