Hello,
I am using Rockstor for more than a year now, but still feel I am a Nebie to the system.
I recently received the message Pool device errors or something like it. I managed to find out that one of two 3GB disks in my Raid 1 configuration had read errors. I bought a new 4GB disk, added it, resized the pool to include the new disk, which in its turn initiated the balance of the pool initiated. That was 5 days ago. Progress was awfully slow. Until yesterday I saw progress when asking for the balance status on the command line. Last 24 hours no progress. Just an hour ago I lost contact with the networkdrives in my NAS. I could use the webui. First looked at samba and decided to switch it off an on again to see whether that would restore the connection.
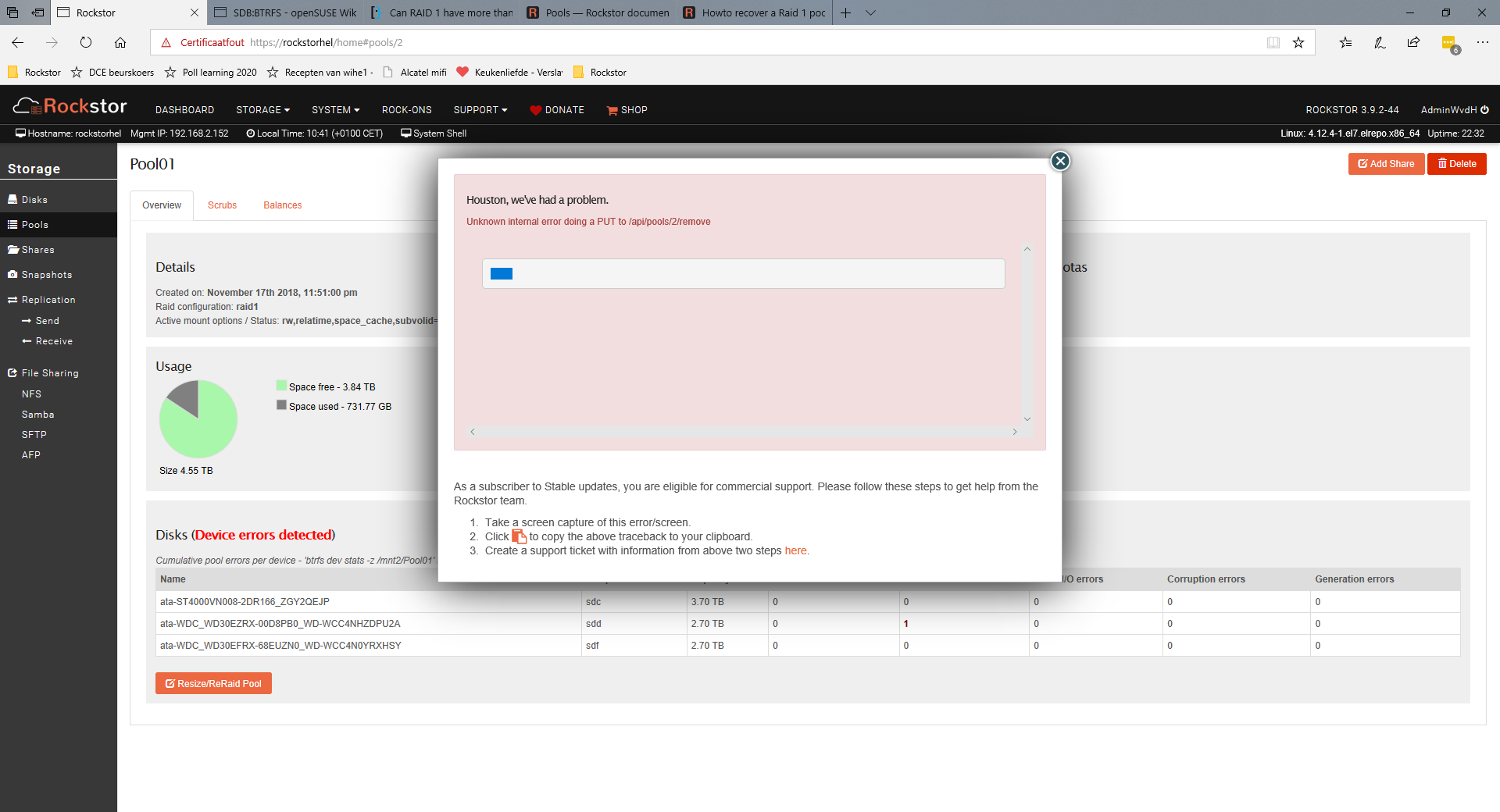
Then I got a Houston message. Sorry Iwas unable to copy it . I decided to do a reboot from the webui.
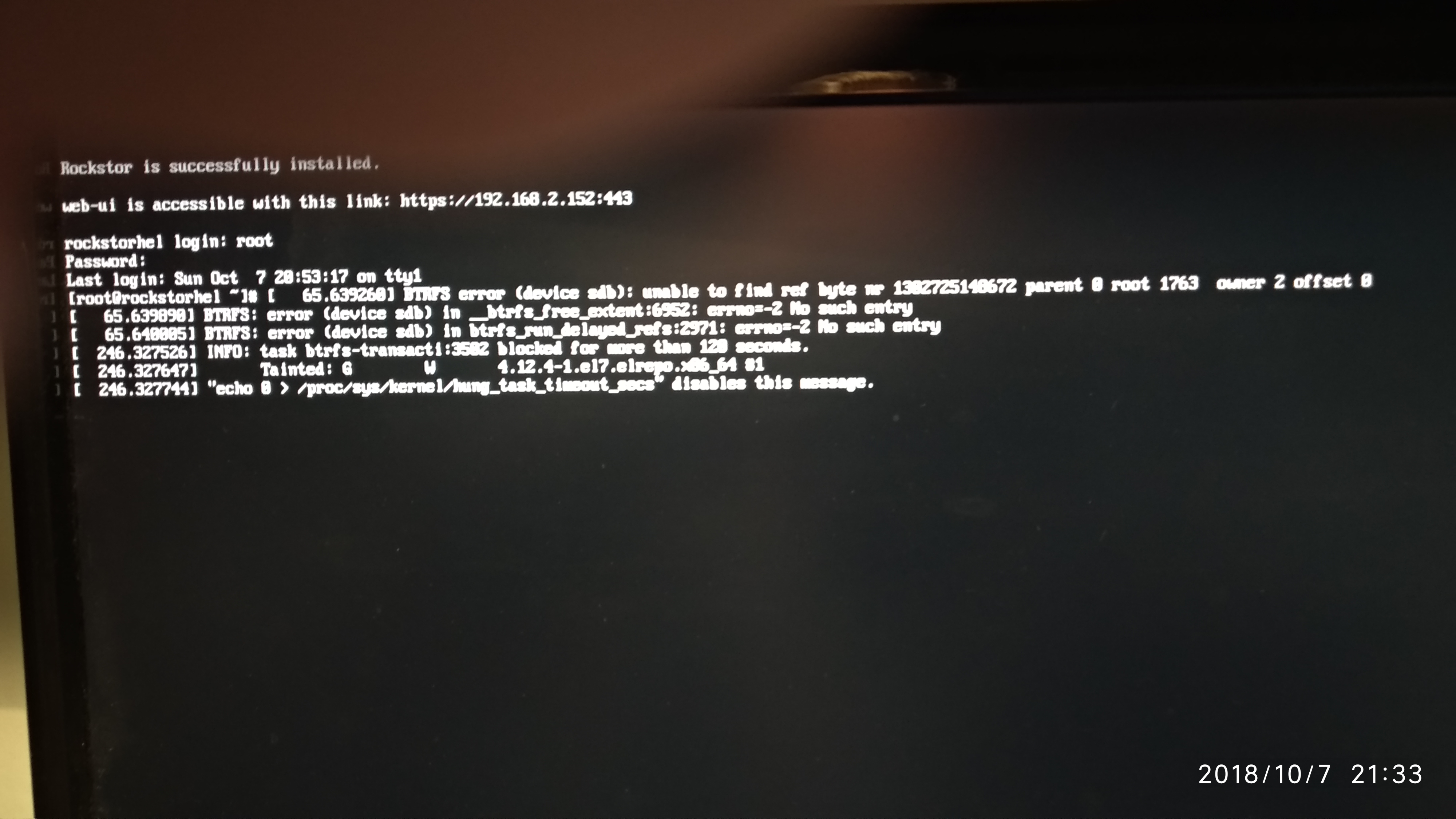
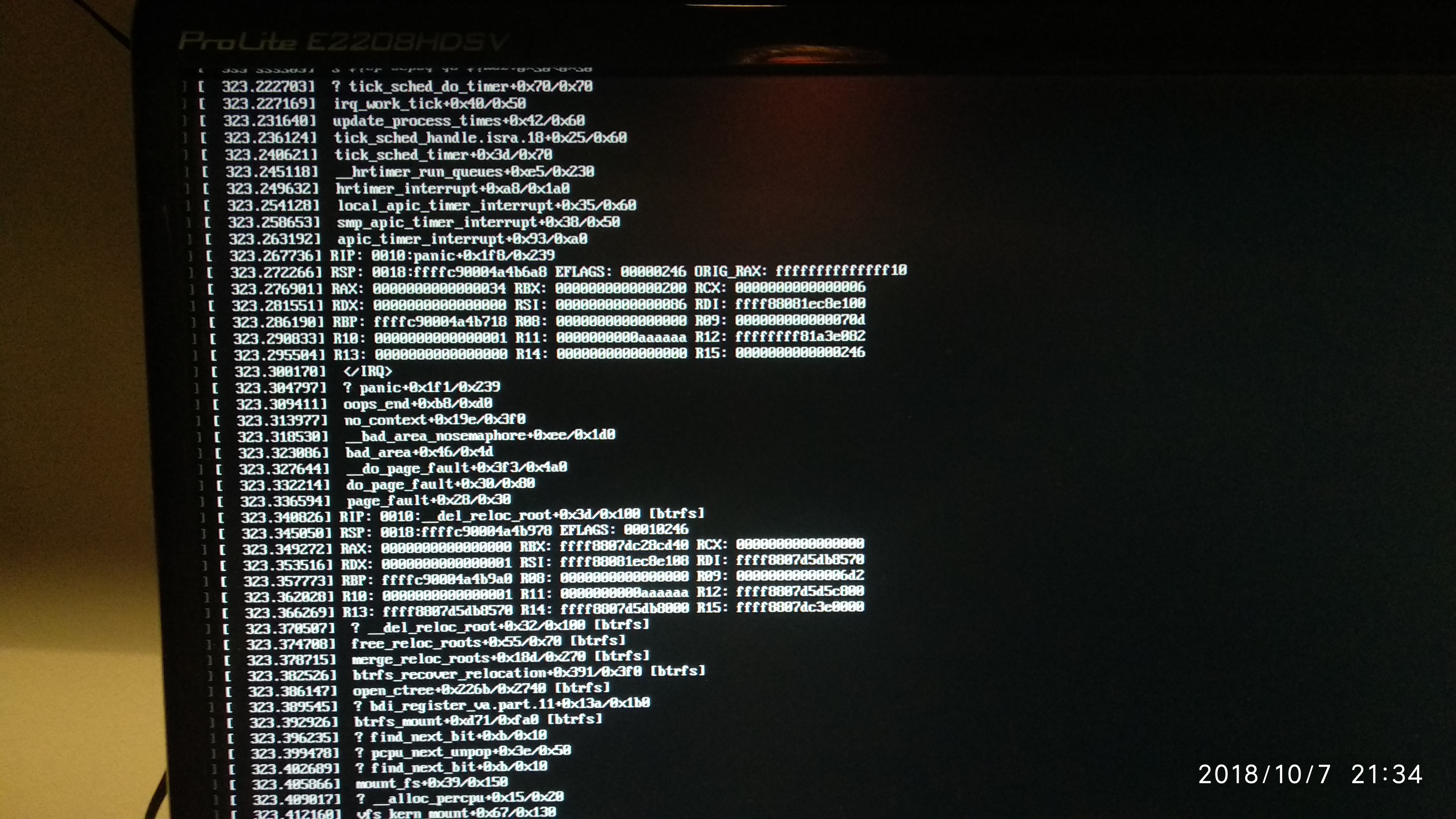
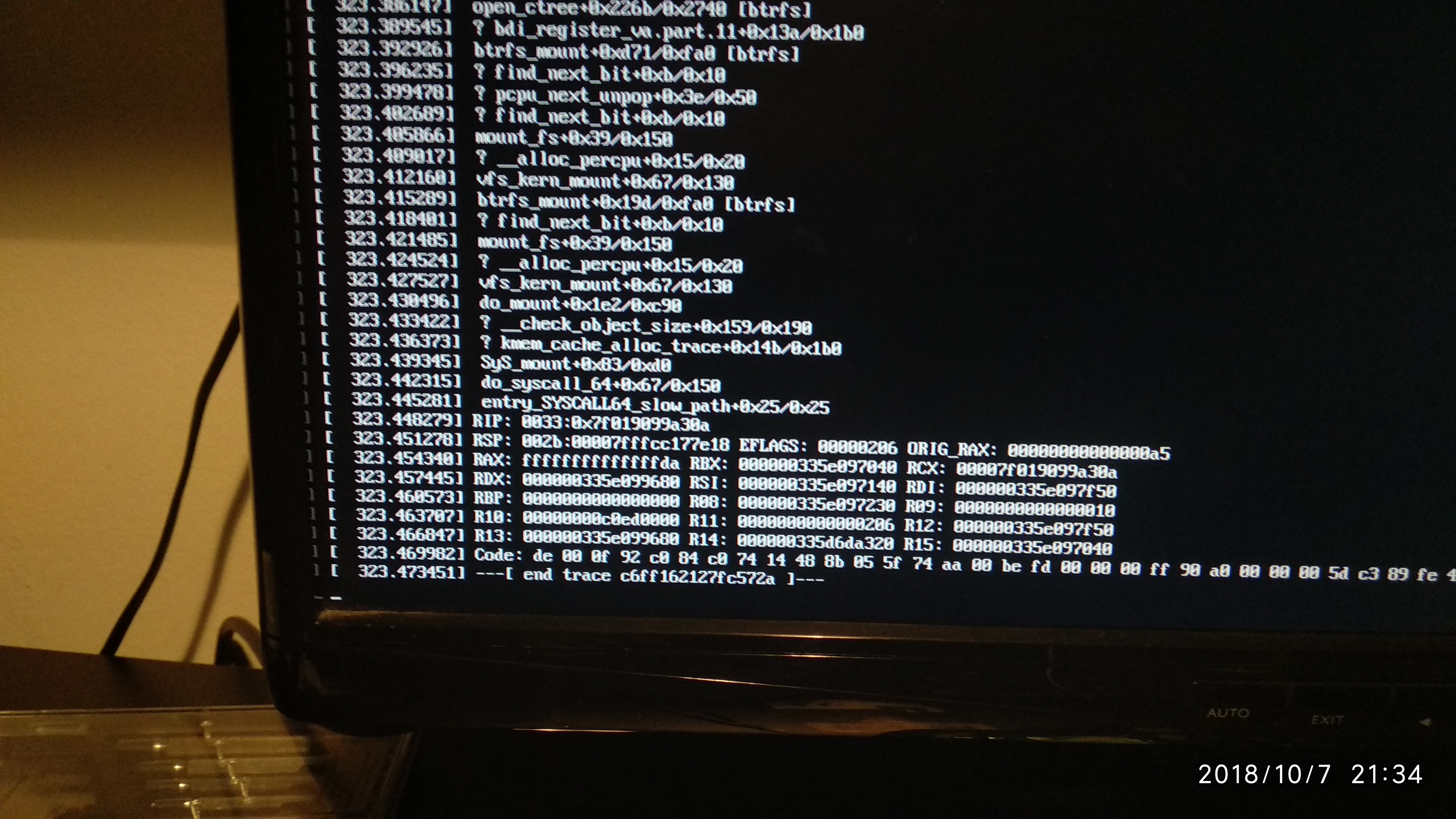
The reboot failed, so I connected a screen and keyboard to the server. I saw a long trace of messages ending in the message that the system was ready to reboot, but was not able to sent that message to a ???.
I decided to do a hard reboot. oops… first message was that the system failed to start btrfs. Fortunately the start continued and I was able to start the web ui.
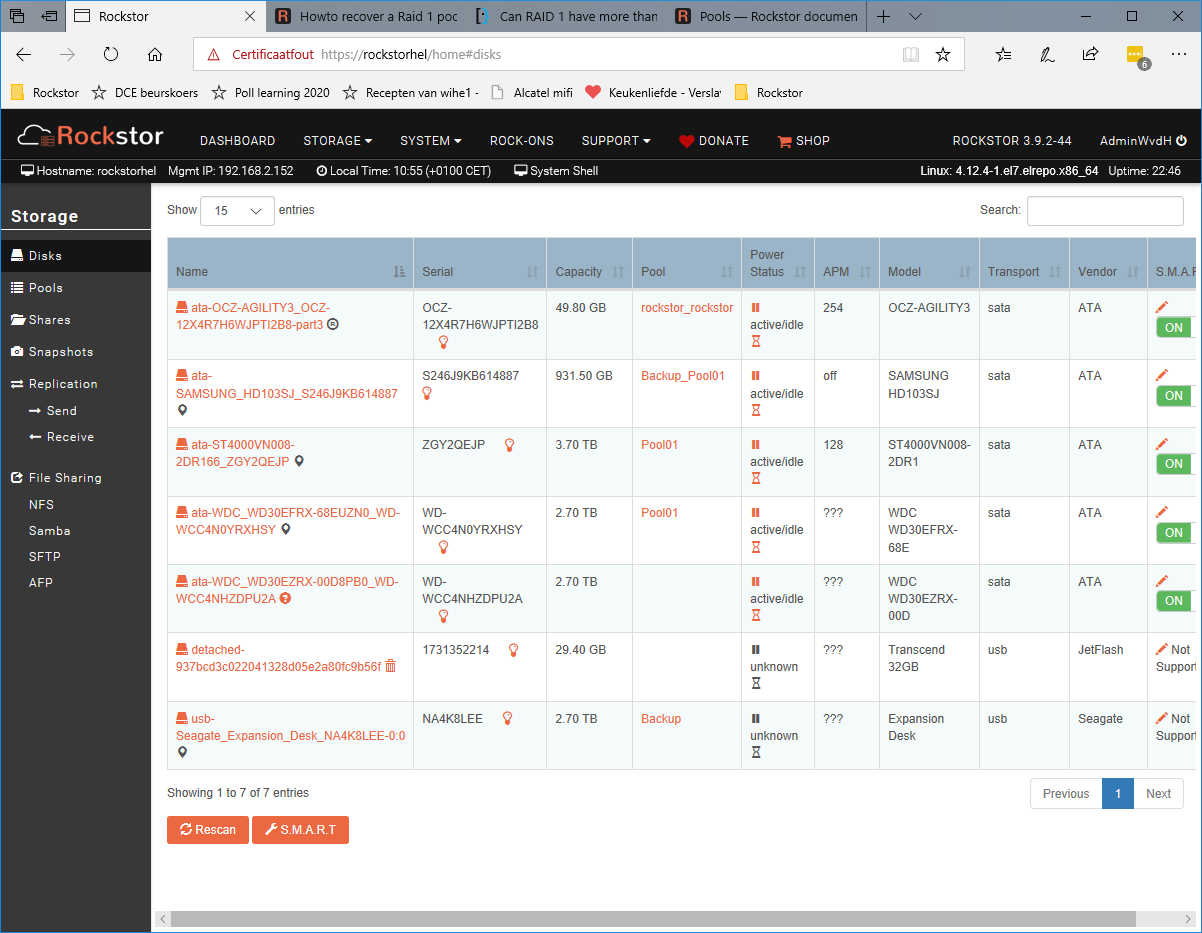
My pool however was unmounted and the automatic restart of the balance failed with the message Error running a command. cmd = btrfs balance start -mconvert=raid1 -dconvert=raid1 /mnt2/Pool01. rc = 1. stdout = [‘’]. stderr = [“ERROR: error during balancing ‘/mnt2/Pool01’: Invalid argument”, ‘There may be more info in syslog - try dmesg | tail’, ‘’] It took ages to get infomraton on the pool screen and also on the Disks screen.
In the mean time the web GUI is offline agein and the ip-address can not be found
SO… Now I am lost, could you please help me in solving this issues
regards,
Willem
I just found that after starting the balance on Wednesday 3 october a upgrade is done to .41 on Friday 5 October. Can this be the reason?
I add three screen foto’s illustrating what happens on the console after starting the system
@phillxnet: Philip can you help me with this issue. It seems you have expertise on how Rockstor handles this, and you worked on the .41 release. I can not reach my data anymore and hesitate how to proceed in this matter.