Hi, I’m new to RockStor and have been experimenting with it over the last few days. The hardware is a 2U Supermicro server using an X8DT6 board with the onboard LSI controller flashed to IT mode, and a SAS2 expander with 12 drive bays. I’m using RockStor 3.8-14 and it reports using 4.6.0-1.el7.elrepo.x86_64 kernel version.
I started with 8 x 2TB SATA drives and created a single pool (pool1) in RAID 10 mode and several shares. I’ve been transferring some large datasets from another NAS to the shares using NFS, and as the pool started to get filled I decided to try an online expansion to make sure I had enough room to finish the transfer.
So, I plugged in 4 more 2TB drives (note these are not NAS drives in case it matters) and went to add them to the pool, which failed because there were existing RAID-type partitions. I used FDISK to clear out the drives and tried adding again, which reported success and said it started a rebalance.
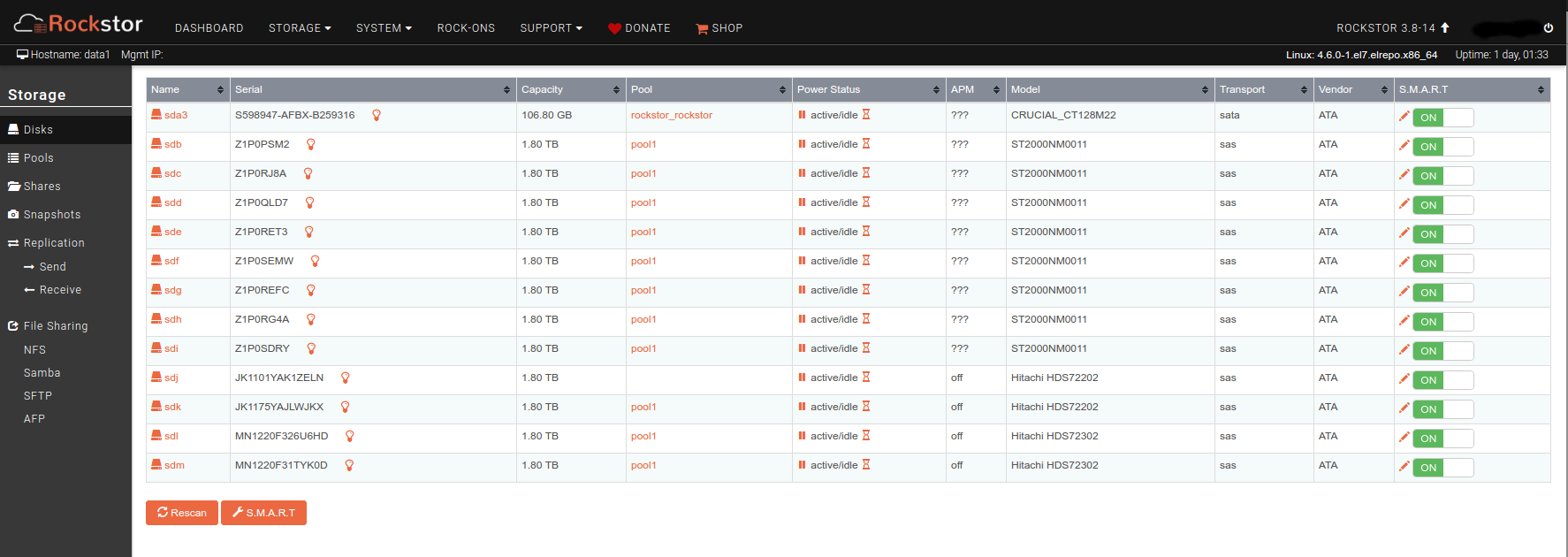
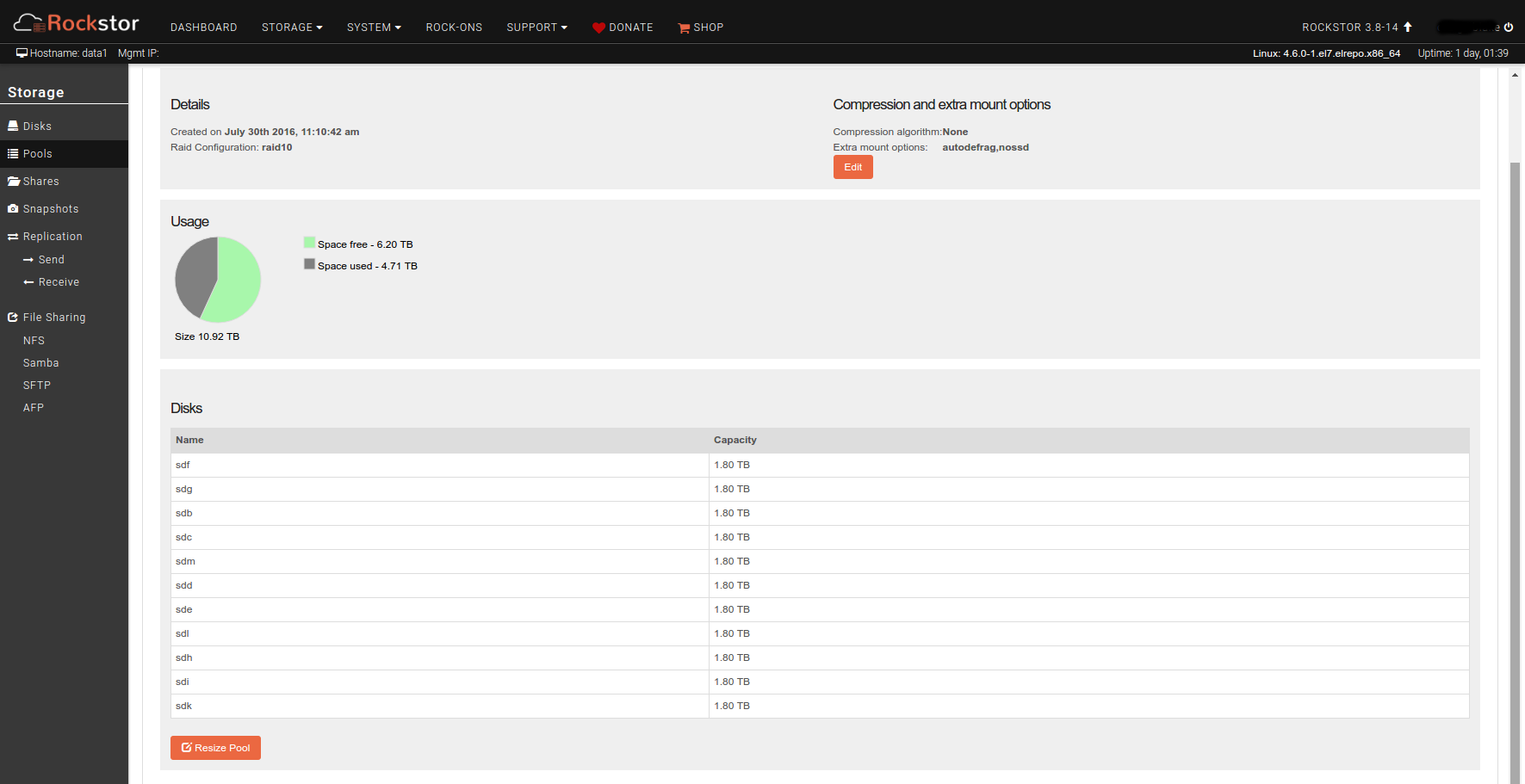
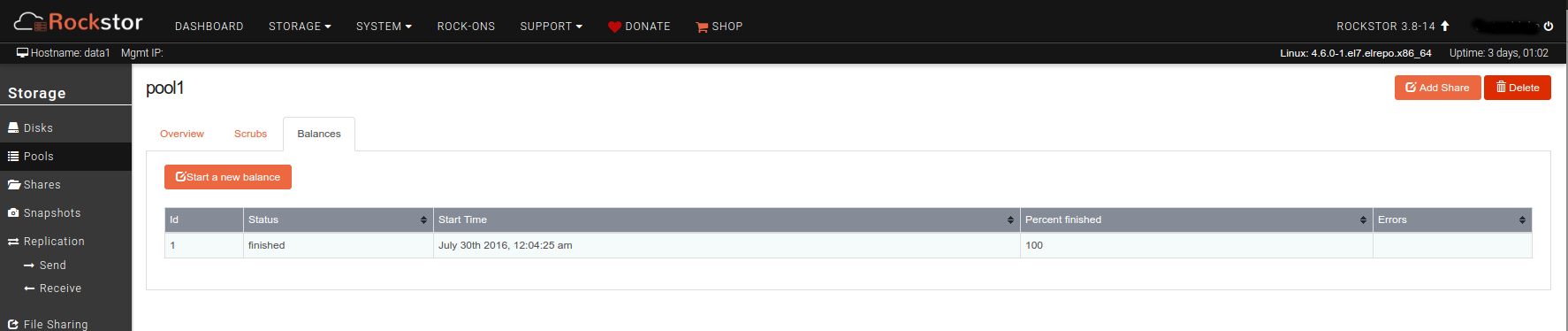
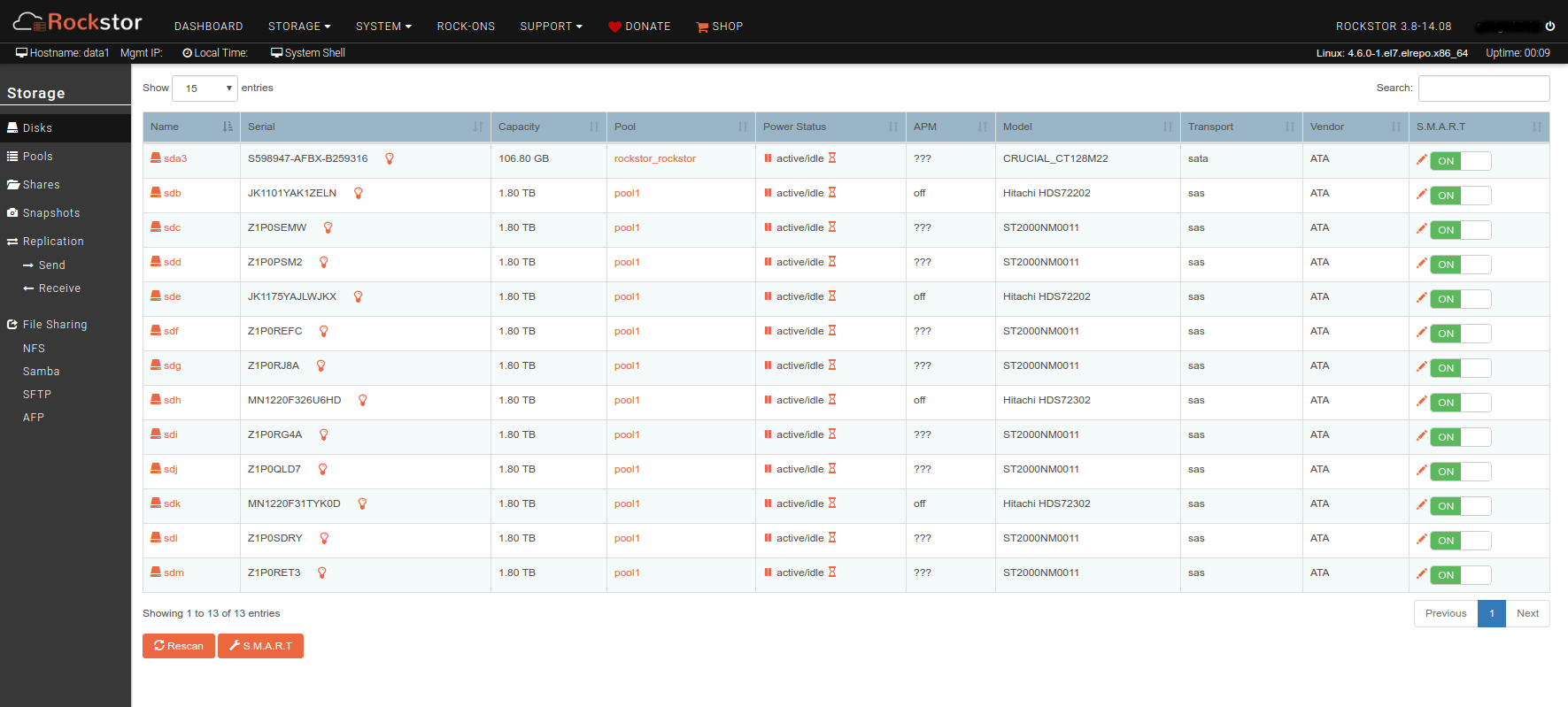
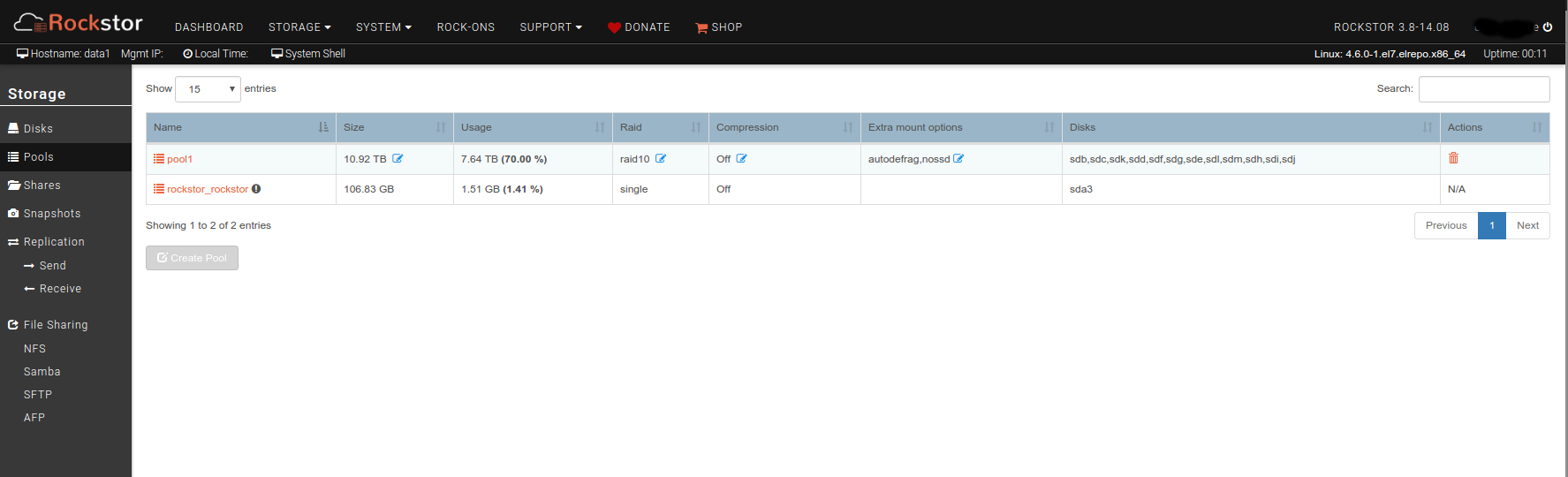
Now, things started looking a little weird at this point as I started seeing inconstent data reported in the web ui. When looking at the Drives page, 3 of the 4 new disks show in pool1 but one does not, and the pool detail pages shows only 11 drives in the pool. However, the total size of the pool shows 10.92TB which seems about right for all 12 disks. More concerning is that the reported usage for several of the stores suddenly dropped, by about 450GB total. One share appears to have lost all it’s data, going by the reported size. I think the reported usage is wrong, though, because running “du” on the mounted share still reports the original total file size. The rebalance seems to have run overnight and reports 100% completed.
As I said this is just experimentation, so I don’t mind if I just need to kill the pool and restart from scratch, or even reinstall RockStor if I need to, but I thought I’d post in case there’s any info that it would be useful for the developers to have about this case or in case there’s a way to check/fix the pool? I’m pretty comfortable with Linux, so let me know if there’s more data I can provide.
Oh, I forgot to mention that the disk which does not show as a pool member does have a ton of read/write activity as viewed from the dashboard, same as the other disks.
Thought I’d add a couple of screenshots. If no-one is interested in gathering more info, I’m going to wipe out the pool and recreate it from scratch. And I guess I’ll work under the assumption that online expansion is unstable for now?
@shpxnvz Welcome to the Rockstor community and sorry for the slow response here, as you appreciate this looks to be quite a deep problem and as such requires quite a bit of focus; however as far as I’m aware the main developers are all fairly tied up with current issues. Your investigation on this is much appreciated however and thanks for the additional info and screen shots.
Whatever info you can put here to try and narrow down the problem would be great. From your first report it looked like the balance was still in progress. That is we do have a current issue open on reporting in progress balance status in the Web-UI:
which as it goes I am just in the process of wroking on, so hopefully that should soon not be an issue.
But that is only the Web-UI reporting of the balance. Can you confirm via the following command that there is no, in-progress balance:
btrfs balance status /mnt2/pool1
By now it’s pretty certain that there isn’t one but still good to know and rule out. As a balance does also take up a load of space temporarily which might explain your previous space drop.
I’m afraid there is also a know issue on some space usage reporting which relates to share usage. But my understanding currently was that this occurred mainly after importing pools with existing share on. Again I hope to have improved this a tad just recently as part of my current and long overdue contribution to the following issue initiated by @suman :
Additional info that may help could be rockstor.log entries either via System - Log Manager GUI facility or via command line tools ie less or tail on the following file:
/opt/rockstor/var/log/rockstor.log
Especially directly after pressing the “Rescan” button on the Storage - Disks page.
Thanks again for the offer to help but unfortunately I personally can’t properly engage with this particular issue due to on going commitments elsewhere in the project; at least for the time being anyway. But your help is much appreciated and maybe with some log entries and what ever else you can find out to narrow down what’s happening others on the forum may be able to assist. Once narrowed down do feel free to open an issue on GitHub with the relevant details.
I’m not aware of any adding drives to pools issues like this, there is another ongoing forum thread where they seem to have issues with adding more than 8 drives on a particular controller but that shows signs of being driver / card firmware related currently and the drives themselves don’t show up, even under lsblk, so not like your experience.
Do please paste what ever you find and if you need to blow away and re-do no worries and thanks for thinking of the greater good. Of course if you manage to repeat the issue then great; sort of . As this may help to establish how to reproduce the problem which is going to go a long way to getting it sorted.
I ran the btrfs balance status /mnt2/pool1 command on the machine and it confirmed no balances are running.
# btrfs balance status /mnt2/pool1
No balance found on '/mnt2/pool1'
I tailed that log file while hitting the rescan button and got no output at all. I’ll look around a bit and see if there’s a knob to adjust verbosity/debug output.
does your missing drive name appear to be part of pool1 in that output? As these names change from one boot to the next you will have to confirm on the same boot and web-UI refresh of pool disk members.
As an experiment I did a graceful reboot of the NAS, and the “missing” disk persisted. Then I remembered getting a notifcation email from the NAS that the scheduled software update failed due to the RockStor YUM keys not having been accepted. So, I SSH’ed into the system and manually did an update while accepting the new keys, which updated RockStor among other things, then rebooted after.
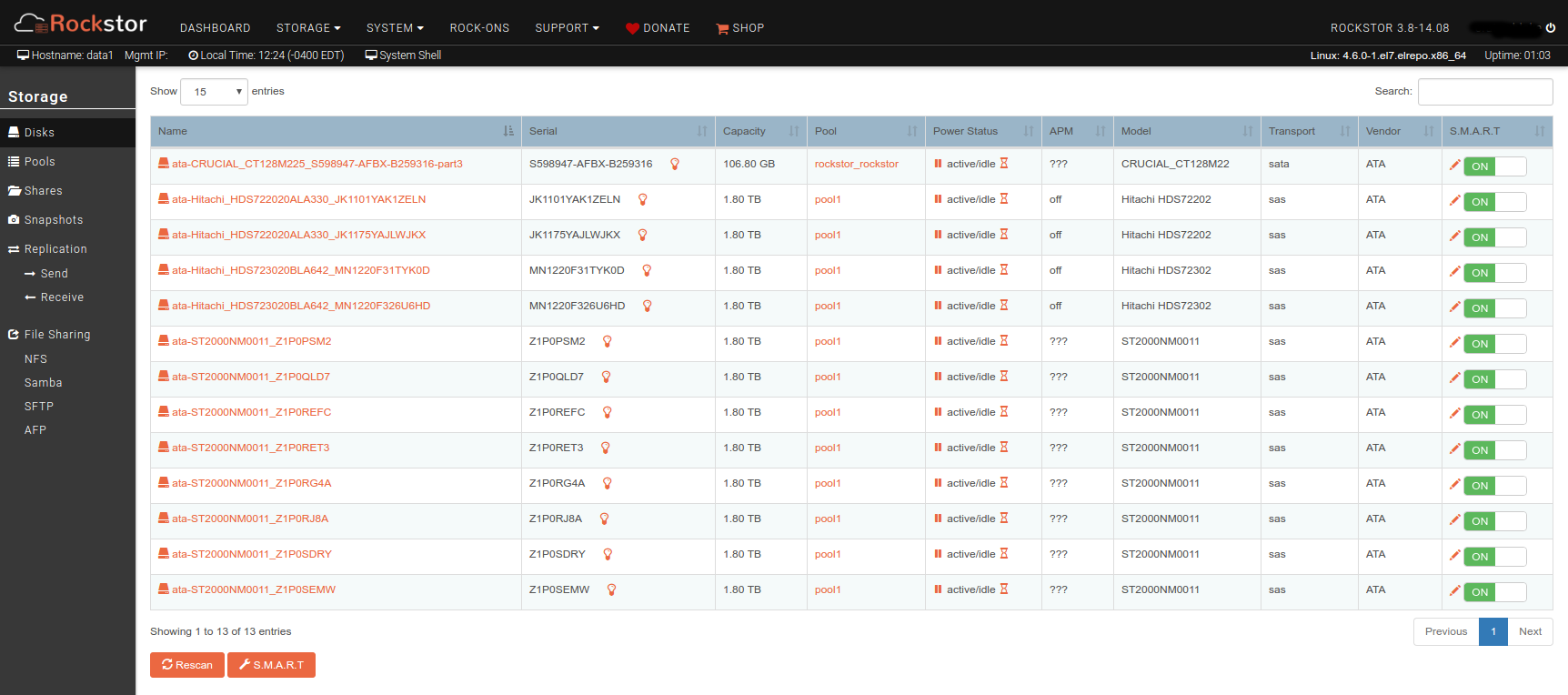
This time, when I looked at the Disks page it shows all the disks as members of pool1. The device names have been shuffled around, but I assume that BTRFS uses drive metadata to keep track of stripes and replicas so that’s not an issue?
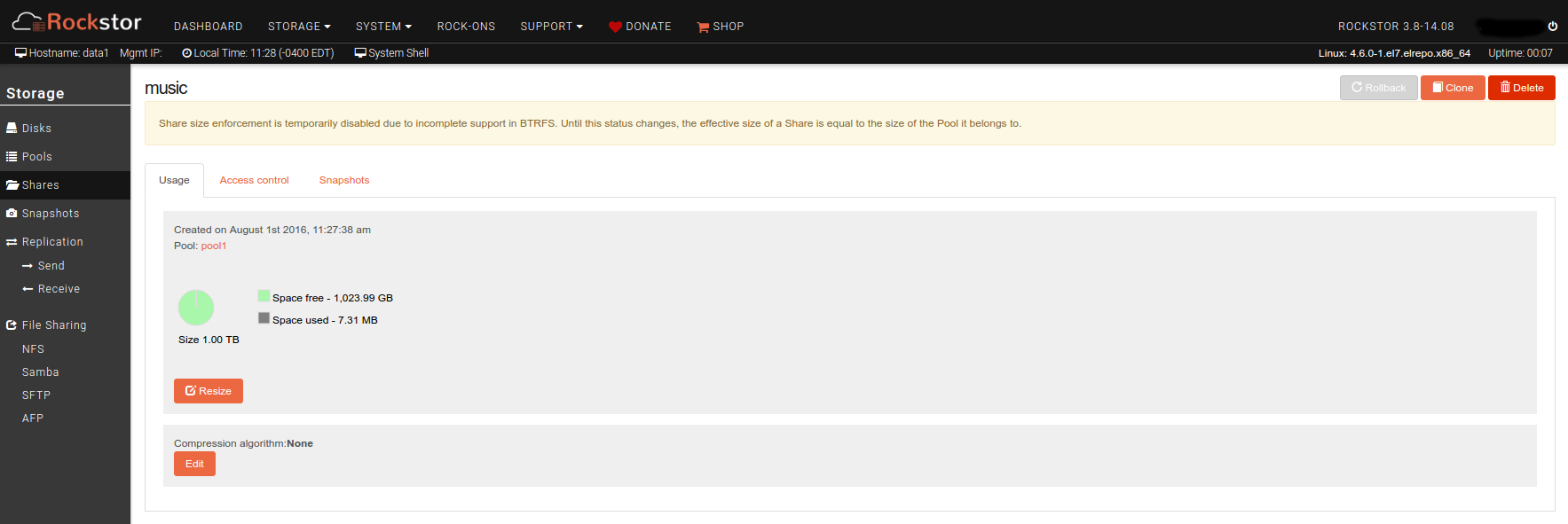
But, oddly, continues to report incorrect usage at the share level (and all the shares together report usage far below the usage the pool itself reports):
# btrfs fi show
Label: 'rockstor_rockstor' uuid: 013d809c-48f5-4c55-85aa-c13c7b87991f
Total devices 1 FS bytes used 1.52GiB
devid 1 size 106.83GiB used 4.02GiB path /dev/sda3
Label: 'pool1' uuid: cf9730a3-ffae-4200-ab2a-63eb39ff6171
Total devices 12 FS bytes used 7.64TiB
devid 1 size 1.82TiB used 1.27TiB path /dev/sdd
devid 2 size 1.82TiB used 1.27TiB path /dev/sdg
devid 3 size 1.82TiB used 1.27TiB path /dev/sdj
devid 4 size 1.82TiB used 1.27TiB path /dev/sdm
devid 5 size 1.82TiB used 1.27TiB path /dev/sdc
devid 6 size 1.82TiB used 1.27TiB path /dev/sdf
devid 7 size 1.82TiB used 1.27TiB path /dev/sdi
devid 8 size 1.82TiB used 1.27TiB path /dev/sdl
devid 9 size 1.82TiB used 1.27TiB path /dev/sdb
devid 10 size 1.82TiB used 1.27TiB path /dev/sde
devid 11 size 1.82TiB used 1.27TiB path /dev/sdh
devid 12 size 1.82TiB used 1.27TiB path /dev/sdk
So, there appears to be some improvement in the situation, and evidence that the RAID array is correct even if the share info is not. So, positive progress.
@shpxnvz OK, that’s looking better. So currently only the share usage reporting a bit strange then. What does the following command output?
btrfs qgroup show /mnt2/pool1
And if you are game I may have a tiny code change for you to try out? Don’t think it will impact on your setup as I think it only affects imports but if you are game to break you existing system then let me know.
Are you on the stable or testing channel of updates by the way? From the version number displayed it looks like testing yet the drive names look like older stable variants!
Sure, I’m up for trying code changes. I’m primarily a Scala/Java developer but I’ve worked with enough Python to get around ok.
I’m on the testing stream for updates, but because the auto-updates were failing (due to keys that needed to be manually accepted) I did not have any updates between initial installation and about an hour ago. The pool and shares were setup before those updates obviously. Could that be why the naming looks odd?
@shpxnvz Thanks, all good info. Can’t really look into any of this at the moment though unfortunately but at least it’s here to re-visit.
No as drive names are re-written on the fly, Rockstor tracks drives primarily by their serial numbers, explained in the developer / technical manual entry Device management in Rockstor . I’m expecting to see by-id type names instead of the sdX type names. I take it you have by now already re-scanned on the Disk page; but they are polled anyway hence my surprise. It could be some kind of db locking issue that’s preventing the by-id name substitution, but this would be all over the logs.
Thanks for volunteering to break stuff. I’ll circle back around to this one.
@suman do you know what might be cause the failure to upgrade to the new by-id type names, I haven’t see this myself.
@shpxnvz OK, that’s great; and yes that is what I expected to see. That’s a relief.
Sorry getting a bit jumpy today; it’s been long but productive. I’d like to engage in your share size issue but couldn’t do it justice right now. But your help in testing stuff would be much appreciated.
The code change I was referring to is in:
where there is a single character change from “-2” to “-1”. But I really don’t think on reflection that this affects your size reporting issue. I suspect @suman is already aware of why we get these share mis-reporting issues and we just need to get around to fixing them. That patch was to address pool import shares reading as zero or near enough to it. Worth a try as doesn’t look dangerous, but be warned anyway. We may just be waiting on the quota accounting fixes upstream in btrfs.
You will need to do a restart of at least the rockstor.service for that code (character) change to take effect, so either reboot or less exhaustively:
systemctl restart rockstor
The function in question ( share_usage() ) should be on your system at /opt/rockstor/src/rockstor/fs/btrfs.py
No need to put any of the other changes in as you most probably realise.
This is pretty old code that I am currently chipping in to help provide unit tests for before it undergoes any re-vamp that is deemed necessary. But I couldn’t help but slip in a few fix-ups while I was working on the unit testing issue.
Never done any Scala myself but enjoying the Python having come from Java most recently, which I quite liked.
I made that change to the code and restarted, but it had no effect on the reported sizes as you suspected. I also added some new logging in the function, so I am sure the changed code was used.
I would like to try poking around more to try to debug on my own, but unfortunately, I might need to reinstall before I get time to do that.
I noticed that after the yum update which seemed to fix the disk membership information, the rock-on I had previously installed appeared to have lost it’s data. In the process of trying to figure out why, I ended up explicitly unmounting and remounting the NFS shares that were reporting incorrect size, and now all the data on them appears to be gone as well.
I’m really confused about this, because even after the update/restart I was initially able to run ls and du on the shares and get listings of dirs/files and sizes. I guess perhaps the NFS mount had stale data cached which got refreshed by remounting?
Whatever the cause, I don’t think I can trust that the system is in a state where data will be safe, so I will most likely kill it and reinstall.