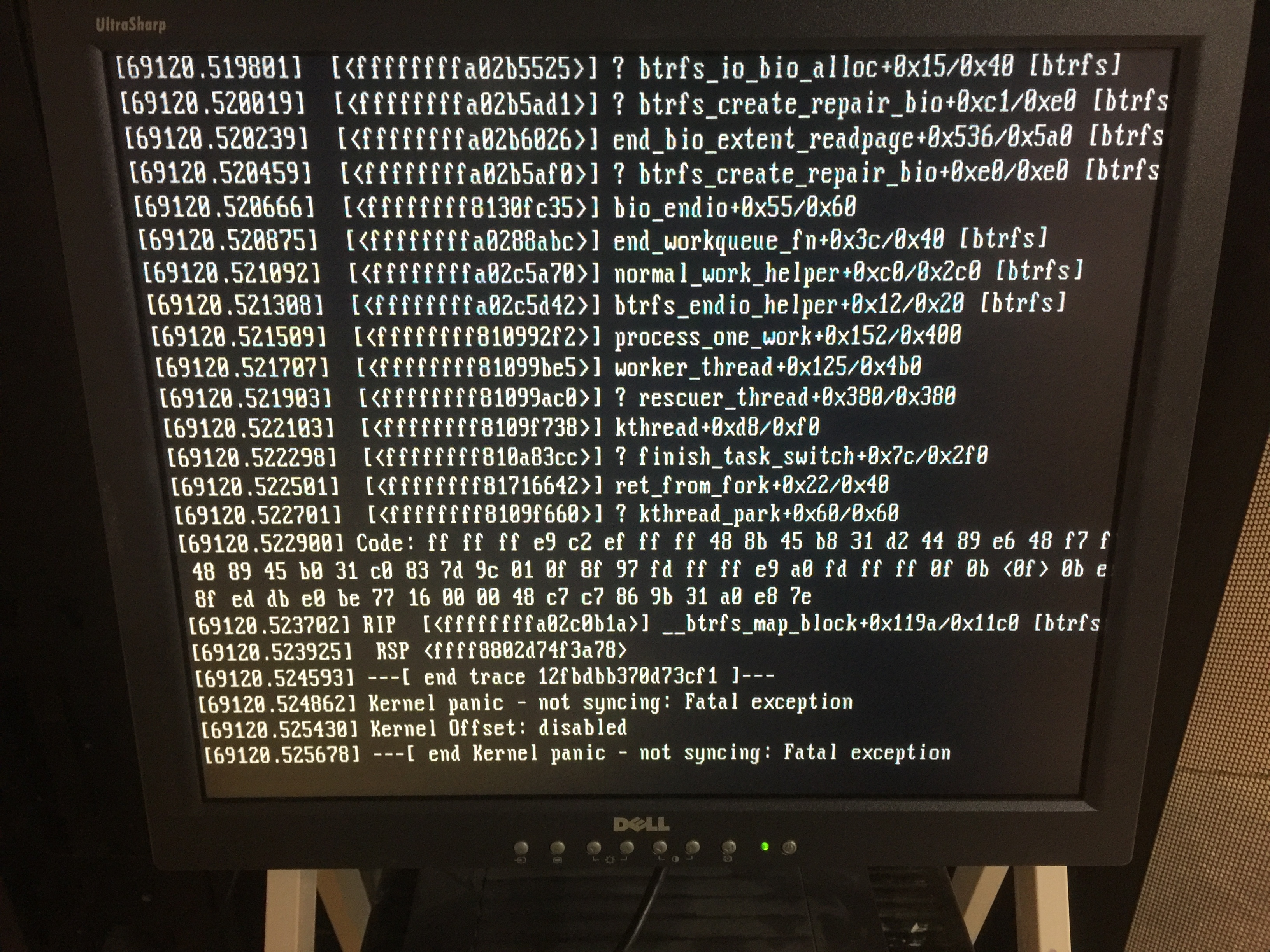
I have gotten kernel panics from what I believe to just be high I/O on btrfs volumes. I have a SSD running rockstor root and then 2 pools on RAID10 btrfs pools.
I have had a bad disk on each that I am replacing but during the replacement of the second pool disk the server crashed with a kernel panic. After starting back up again, btrfs actually seemed to be replacing the wrong disk. I reverted to the old (bad) disk, am rebalancing and plan to try again.
So when the kernel panic happens I am either doing a btrfs job or copying/backing up data. So I’m led to believe it’s I/O or bad disk related but I can’t be sure.
The problem is journalctl is not persistence (well now it is) and I don’t have much data on the crash. I could enable kdump but I wouldn’t know what to do with the result (not sure if anyone does) and I also can’t find a comparable bug or issue on the btrfs mailing list or forums or github issues.
Here is a picture of the monitor (it doesn’t contain nearly enough info) of the kernel panic. Obviously this halts the system completely.
I don’t understand why btrfs volumes that aren’t the root would do this. Do the other volumes go through a single point of failure that affects the root btrfs volume also?