Hi!
I had two failing disks this summer, which meant data loss (yes, I had a backup, all files recovered, new disks, new pools, new shares). Most likely, those two disks didn’t fail at the same time so if I had a routine to log in every once in a while I would have detected a disk failure and replaced the first one, avoiding data loss. I didn’t, until too late (but good error message in the GUI).
Question: is it possible to set up a mail notification in Rockstor if/when a disk starts to log errors? I assume S.M.A.R.T will detect such errors automatically? Or do I need to set up a script to run SMART checks on a regular basis and on-error send an e-mail? I do get status mails from rockstor/anacron on updates etc, so e-mail works just fine.
To my knowledge, smartctl is not a continuously running service, so it’d have to be a cronjob of sorts. Frankly, it shouldn’t be too difficult to cook up a script for that.
Did you have a scheduled scrub set up? I’m not 100% sure if those generate e-mails if they find issues, but I’d assume that’s an even better way of knowing things are starting to go pear-shaped.
I agree with @doenietzomoeilijk that SMART data won’t give you the whole story, even though it is still useful.
Your question actually reminded me of an older thread in which @petermc and @Haioken (among others) had an interesting discussion about “health” metrics and some example scripts as well… I haven’t tried it myself, but it may be worth a read:
The thread you suggested look very promising; I’ll try it out - however I realise it would be good to have a stockpile of half-broken disk in order to test it out
At least there are no btrfs errors!
There is a rather underdeveloped (on the Web-UI side) feature within Rockstor that hides behind the S.M.A.R.T button at the bottom of the Storage Disks page.
Next to the Rescan button:
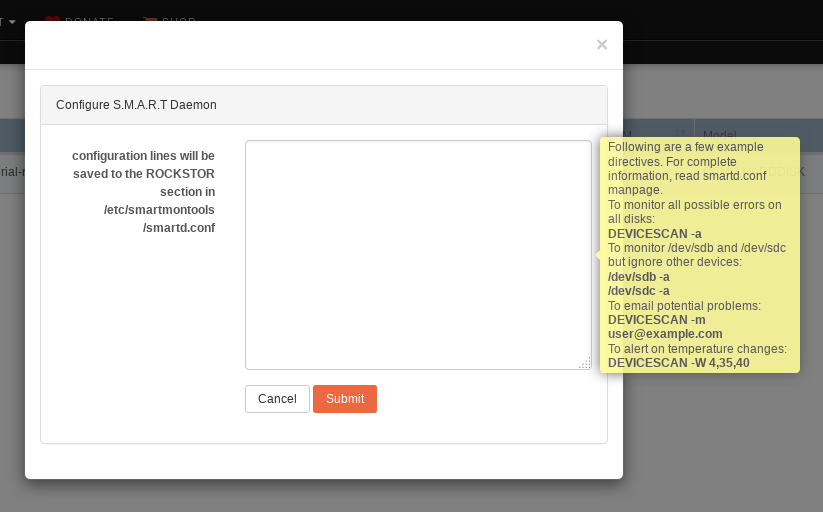
This in turn leads to a config dialog for smartmontools build in disk test scheduler which includes the ability to email reports:
As can be seen their are, admittedly brief, tooltip directions to achieve a number of things, but again this is much in need of some Web-UI development so that we instead have this option under an advanced tab on a page that otherwise presents sane defaults and some nice schedule options etc. Or it may be that we should have configuration here and scheduling as an option in our System - Schedule section. But as always these things are often more complex than they at first appear. A read of the tooltip suggested man page expands on what is possible.
Basically once you’ve digested what is possible you can forumulate a config line or two and paste it into that box. As I say - underdeveloped on Rockstor’s part and I’ve been meaning to get to improving this for some time now.
Also note that the indicted config file has a wealth of example options so that’s also worth a read. This system is what most scheduled S.M.A.R.T drive test systems are ultimately based on. Once configured it’s pretty good, it’s just that config part that’s the problem really.
Hope that helps.
Note to those involved in the openSUSE migration effort (@Flox namely here); I’m pretty sure the location of that config file, and/or others related to smartmontools is not shared between CentOS and openSUSE so we have additional work to do on that front. @Flox feel free to update our Wiki on this accordingly if you fancy.
But @Flox and @doenietzomoeilijk suggestions are pretty much the rest of it currently. We do hope to build in a full pre configured log analyser / reporter later but as always we are having to go bit by bit.
If you could share what ever config you end up finding works for you that would be appreciated as it all help with how we might, in the future, set up such things by default.
@phillxnet One thing that might be worthwhile to consider as a partial/temporary solution could be to ad an e-mail alert to the error message I got in the Dashboard/web GUI interface - can’t remember exactly the wording - but it informed very clearly about a degraded pool and provided a short notice about trying to mount in degraded mode. I would think that already after one failed disk this error would be detected and the message activated so it’s still a bit after the fact but quite likely before actual data loss
Ooh, so there is a daemon kicking around, that’s excellent! Even if the interface is somewhat sparse, it’s there, so it’s something to play around with for sure.