Hello,
maybe someone can shed some light on this issue: it’s a new RockStor installation, filled with data and running without problems for a few weeks.
But yesterday Midnight commander had problems copying a file to a temporarily attached USB disk (NTFS). After that I saw “DEV ERRORS DETECTED” in the pool overview and the corruption errors in the disk table. I tried to restart the copy process, but that lead to the same error message in Midnight Commander.
I’m using RockStor 4.5.8-0 and have one RAID 1 pool using all harddisks in the system (all are connected via SATA to the same controller card (LSI HBA 9201-8i).
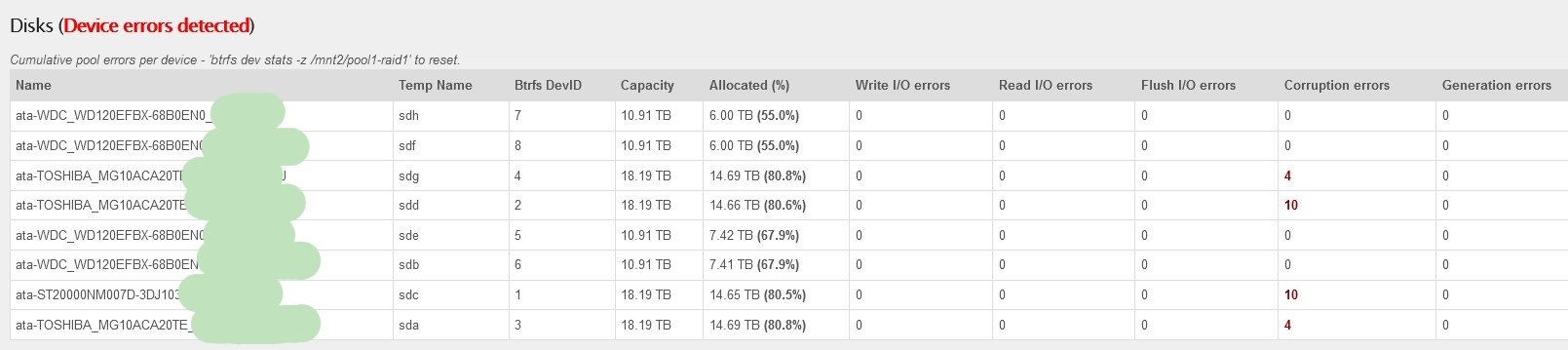
It seems a bit strange to me that the error count is so “even” ?!?
Shall I just run a scrub? I don’t think that 4 disks are bad or 4 cables at once.
Of course: I looked at the smart values of the disks: all fine. Then I ran the short SMART test on all of these disks: they all PASSED.
Is the file in question bad on 2 drives at the same time? Wouldn’t the file with correct hash be copied if one is found corrupted? Will only a scrub repair/replace the bad file?
@newUser2023 Welcome to the Rockstor community forum.
I can chip in a little here:
Re:
Keep in mind that btrfs-raid1 is not across all disks in a pool. Btrfs raid levels are similar but not identical to traditional raid. It is chunk based not drive based. You have 2 drives with 4 errors each and 2 drives with 10 errors each: ergo the corruptions happened across 2 drives at a time.
Also note no read/write errors - only corruption.
No it doesn’t look that way, it could still be the controller but memory is a far more likely candidate.
That’s good.
Or this part of the filesystem has become corrupt via memory issues. Bad RAM is the likely first candidate here I think. And before you do anything else this must be checked/established. One pass of the suggested program is often not enough 2 full passes is bare minimum.
Bad RAM and all bets are off as checksums/data can then be mis-calculated/corrupted in-flight. Ergo missmatch so file return fails as no copy passes tests.
So in short this is a bad look and point to bad RAM - corruption in flight between read and write. The wrong data/metadata was copied to the pool (likely duplicated also). This is why server class hardware uses extra robust ECC memory.
You must do nothing more with this pool untill you have extablished the likely cause: bad memory is my bet. Anything more you do will compound the likely errors as btrfs can only do so much to maintain data/metadata integrity if RAM changes ‘stuff’ on the fly.
Once you have established the likely hardware issue here, you can approach pool repair; but do nothing more on this pool until you have assured yourself that this hardware is reliable.
Thanks for the detailed answer and advice on what to do next and what to avoid! I actually already ran a memory test with this program: PassMark Software MemTest86. The default settings perform 4 runs and the 8 GB of RAM in this system were tested fine.
→ to be sure I will do a longer test with multiple runs with Memtest86+ too, as you suggested and reply with the result!
From the current standpoint - having these (few) corruption errors and making no further change to the pool’s data - I have two questions:
When I just read data from that RockStor system: when no additional corruption errors occur during the copy (read only) process then I assume, that the copied data matches the hash and is actually fine. Correct? I know the current corruption values and also I can check the logs if there are additional errors detected.
Assuming that the memory is fine, how could I check the LSI controller card itself? Are there vendor specific tools to diagnose such an adapter? Of course you cannot provide support for the controller, but did you come across any tools I could use?
This is a more generic way of troubleshooting the card … starting with checking out the hardware, moving on to command line and then ("not applicable in this case) via FreeNAS (there seem to be also some threads out there, about the controller overheating due to insufficient airflow/cooling, but not consistently reported):
Changing the controller has stopped any new errors from appearing within the last week. However, I reinstalled the whole system and copied the data back from backups, so it’s a new fresh situation since a week.
If the culprit was the (old) controller, then no new data corruption errors should occur. If it was the RAM (as initially suggested) despite of the negative test results, then new errors should appear sooner or later.