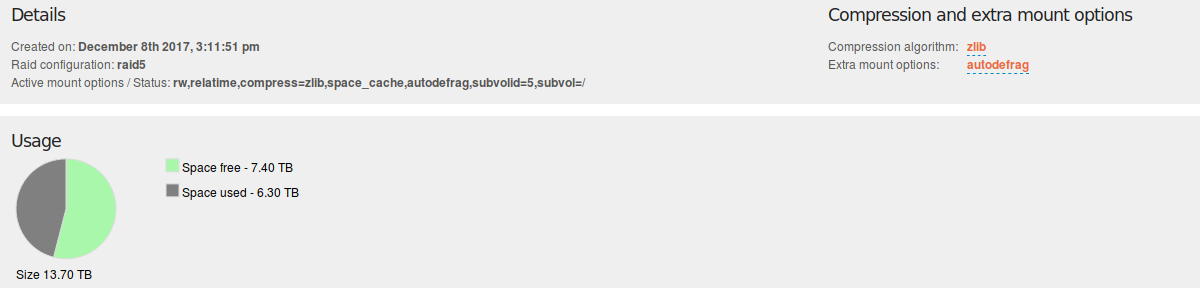
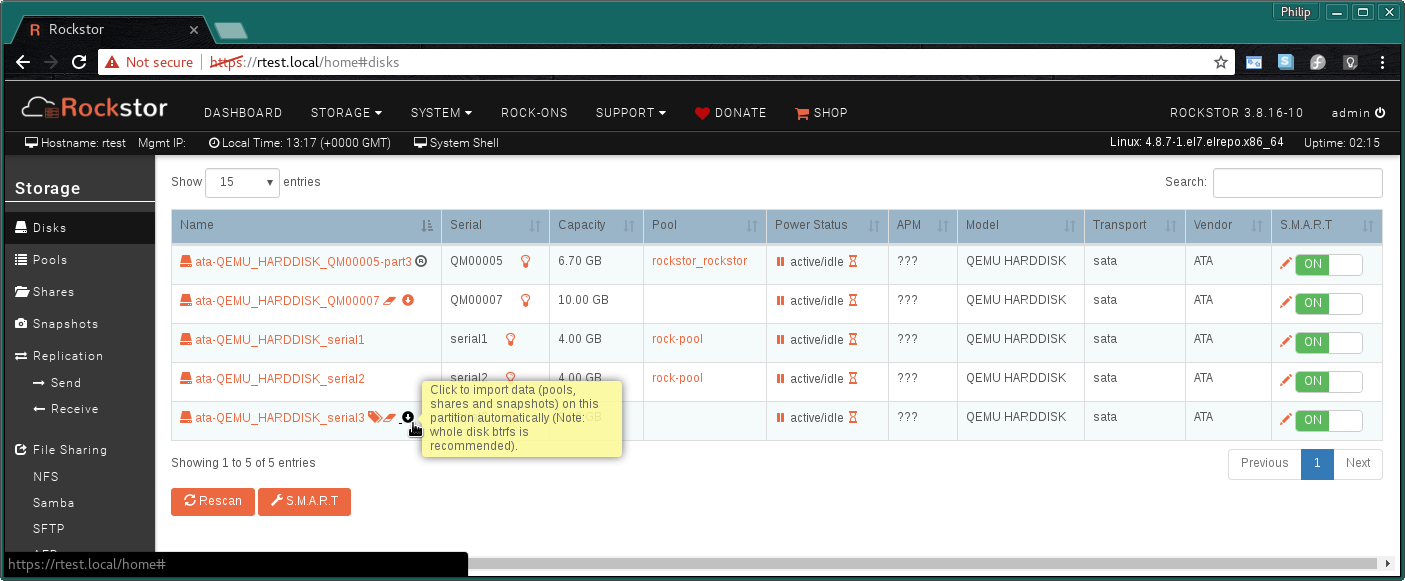
i had a pool with 4 disks Raid5 (3x6Tb, 1x 3TB) and wanted to replace the 3TB info a 6TB. Did this on cli (deleted the 3TB disk, added the 6TB disk and did a balance) and it worked as expected but the Web-UI doesnt reconize that the new disk belongs to the existing pool. After reboot the pool doesnt get mounted as before, cause the mount options are now wrong! I disabled quotos. No change.
Btw i use partitions not whole disks.
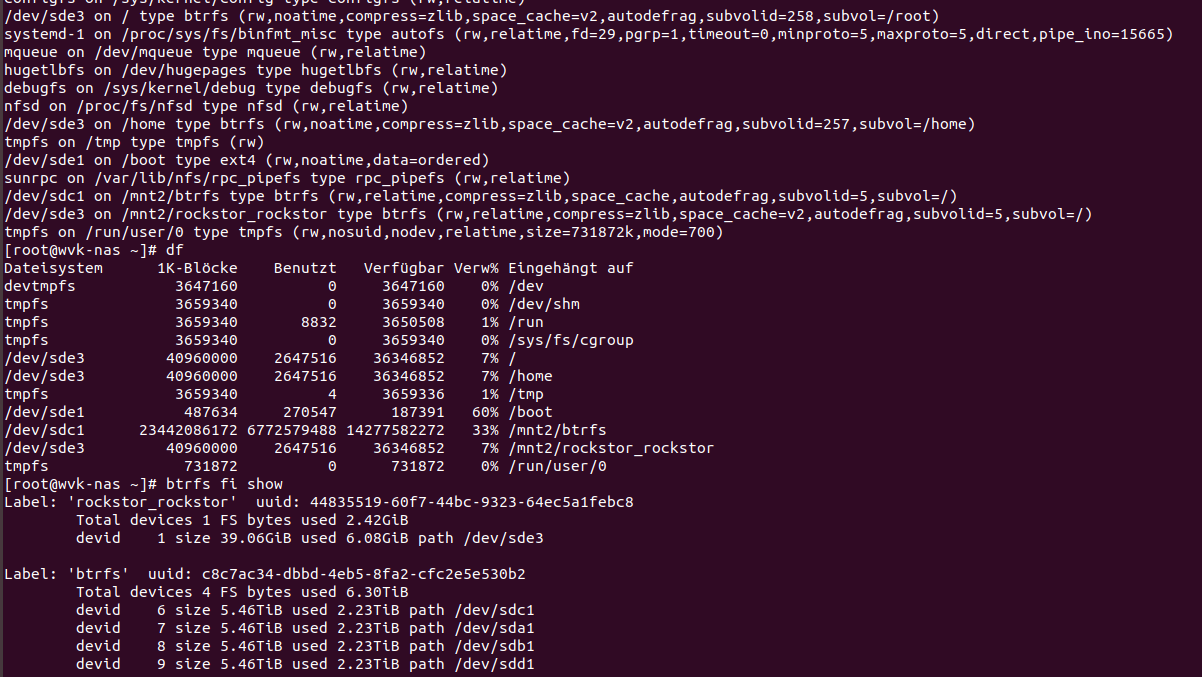
wrong: rw,relatime,compress=zlib,space_cache,autodefrag,subvolid=5,subvol=/
It mounts the btrfs root instead ot the subvolid=5…so it should be subvol=/mnt in this case
Btw why do you use subvol AND subvolid simultaniously?! if one is set wrong the whole mount breaks! So imho only one option should be used and is sufficient! This would reduce mount errors.
This could have been done via the Web-UI pool resize where you first removed a disk and once that was done and it’s consequent balance completed you could then have resized again and added a disk.
The partition use (not recommended for Rockstor but not impossible) does complicate things though.
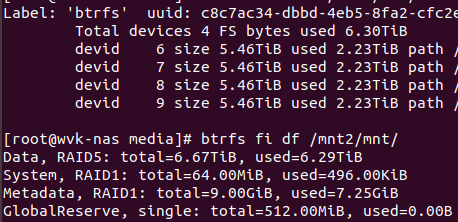
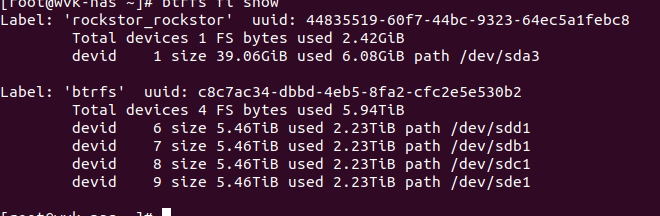
Could you give the whole output, ie including the dev names and all pools, for your output from:
btrfs fi show
as that will help to to see what the actual state is: we only support some types of partition use.
Also a pic of the current ‘Storage → Disks’ page would be helpful.
Disabling the quotas will break many things currently so best re enable before proceeding.
I take it your are referencing the mount options as displayed in the UI on this one.
Please see the output of
cat /proc/mounts
Which we use as the canonical source of mount state, ie straight from the kernel info. I think 'cat /proc/mounts is just being thorough and redundant here.
Sorry but I forgot to ask the Rockstor version you are on?
Also I’m assuming the pool was not originally created within Rockstor and that you have manually mounted at /mnt2/btrfs (ie no mount on boot).
I’m not quite sure how the mount even worked ‘before’ when there are not redirect roles in play, ie if your Rockstor version is new enough (which I think it is) then every disk that is part of a pool managed by Rockstor must be either a whole disk btrfs member (ie not partition table) or the specific partition you are interested in has to be selected per device (via the cog). Only your systems state is not familiar to me in that it is populating the pool column without without any re-direct roles on any of the members: it’s required on them all and were the pool to have been imported they would have been (hopefully) auto added on all but the first drive used for the import.
My initial ‘fix / work around’ would be to boot the rockstor system drive with all drives detached (possibly by booting the usb system disk on another machine as may be easier). During that boot you could delete all the ‘detached-’ device entries which will give you a clean slate. Then shut that down and re-insert to your nice 4 drive system and then follow the instructions on re-importing from a device that has btrfs in partition:
Import BTRFS in partition “But if all pool members are partitions then a manually applied ‘redirect role’ will be needed on one of the pool members in order to enable the import icon on that member. During the import all other partitioned members of the pool will have their required redirect roles applied automatically.”
N.B. DO NOT delete the existing pool with drives attached as that will remove all subvols etc: but it does aNnounce / warn that this is going to take place and that there will be data loss. We need to add a ‘remove from database only’ option on that one .
My suggestion is heavy handed I know but your are not currently in a working state anyway as far as I can see as there are no redirect roles in play so Rockstor doesn’t really manage these disks. You will also have to recreate exports etc so not sure how much of a pain that is going to be.
From the docs we have the following indicating when a partitioned disk has a redirect role in play and is ready for import:
If you are using Rockstor as an ‘add on’ to manually created and managed pools then you may be out on a limb here so it’s difficult to know whats going on as Rockstor does impose certain restrictions that are not prescent in the underlying technology and so it’s behaviour in such circumstances is ‘undefined’.
Hope that helps and do read that import section as it may give you an option to start over and have Rockstor manage your pool and share more as it was designed. Assuming of course your pool can be imported: a test of which could be a fresh install on another usb device and try the ‘Import BTRFS in partition’ approach on that install. Then if it fails you can sort from there on that install knowing you always have the existing usb dev to boot as if nothing had happened as it will still be in it’s current state.
Hope that helps and let us know how you get on.
Please note however that btrfs in partition is very much a young facility within Rockstor, but at least once you have all your disks and redirect roles in line you could alter in place (if backups are up to date of course) by sequentially removing (via resize), wiping, re-adding (via resize) each disk in turn. Waiting of course for each balance to finish. Or not
Let us know the Rockstor version first though as redirect role may not even be on your version.
Also if you are on stable channel best to post output of:
yum info rockstor
Just in case (I found and fixed a recent bug re version number reporting).
[root@wvk-nas ~]# yum info rockstor
Geladene Plugins: changelog, fastestmirror
Loading mirror speeds from cached hostfile
* base: centos.schlundtech.de
* extras: centos.schlundtech.de
* updates: centos.mirror.net-d-sign.de
Installierte Pakete
Name : rockstor
Architektur : x86_64
Version : 3.9.1
Ausgabe : 16
Größe : 85 M
Quelle : installed
Aus Quelle : Rockstor-Testing
Zusammenfassung: RockStor -- Store Smartly
Lizenz : GPL
Beschreibung: RockStor -- Store Smartly
i follow the suggestion to delete the drives…this might be a quick, but dirty fix.
Btw i find the partioning more flexible than using whole disks. this is handy when there disk mixed with different sizes. but i know the whole disk thing is easier to handle.
The /mnt2/btrfs should be /mnt2/mnt which is a subvol (id=5 as mentioned above) within the fs called btrfs. i still think this is because of the wrong auto mount by rockstor. and i swear it worked before changing the disk! But thinking of the removed 3TB disk…i guess this one was used as whole disk and not partition…might this be the cause why it worked before?
With btrfs it isn’t necessary for the devices all to be the exact same size. Ie they can all be different sizes if need be so we can do away with the complexity of partition tables / partitions all together as no requirement any more: plus it’s single dev single purpose type stuff at the hardware level which is nice.
Potentially as Rockstor needs the re-direct role to get the device name correct for mounting purposes when it’s dealing with a partitioned drive. However the mounting may have been unreliable as it could have failed to jump to the next in line when it found no whole disk btrfs when grabbing the first disk and it wasn’t the whole disk. We have more recently been trying all disks in a pool in turn before failing though. But I think I’ve seen it fail never the less. Also only one btrfs part per dev is allowed / catered for, hence my earlier query re btrfs fi show.
As per mounts Rockstor does things it’s own way and will simply not work with manual mounts unless they are exactly as it would do them itself (though it has a go by creating additional mounting as it wants to see it), which should become apparent once you’ve hopefully done a fresh and hopefully successful import. They are all fairly arbitrary anyway, ie we mount both the pool and it’s associated subvols (shares in Rockstor speak) in /mnt2 directly though they are also available in /mnt2/pool-name/subvol-name by virtue of subvols appearing as directories within their parent pool’s mount as well. Pretty sure I’ve missed an element of your point here, sorry.
A pool auto mount point:
mount | grep rock-pool
/dev/sdb on /mnt2/rock-pool type btrfs (rw,relatime,space_cache,subvolid=5,subvol=/)
and it’s associated subvol (rockstor share) mount point:
mount | grep test-share-4
/dev/sdb on /mnt2/test-share-4 type btrfs (rw,relatime,space_cache,subvolid=276,subvol=/test-share-4)
and the subvol/share’s associated directory look alike within it’s parent pool mount point (rock-pool here):
ls -la /mnt2/rock-pool | grep test-share-4
drwxr-xr-x 1 root root 0 Dec 9 16:10 test-share-4
As per your Rockstor version, agreed, you look to be on latest testing channel release so no quota disabled by docker-ci (latest stable release) and all recent disk management except auto mounting when quotas disabled fix.
Good luck and best do a test import with a fresh / independent and similarly updated usb install. That way you can always get back where you are. But do take care to not have both usb devices attached simultaneously as the disk stuff goes a little strange then as it can’t tell which is the real rockstor install device/pool: so only one rockstor install disk/dev per system.
followed you order. removed the disks, deleted the disks and the pool, rebooted, everiting was removed, insert the disks again, set a redirect role on the partition of the …VN0033 disk and imported the pool. But it doesnt resulted in what we should expect.
The pool was successfully added, but after a reboot the disk i added was again gone from the pool as before The “older” disks are still there!
So were all the disks successfully associated and mapped (the map icon) to the btrfs pool directly after the import but before the reboot.? Or did one drive loose it’s map icon shortly after the import but before the reboot.?
Yes it does look like it and thanks for the report. I can’t look into this right now but if you could send me the output of the following command it should help with looking into this later.
We are looking for an anomaly on that disk that the consequent disk re-scan is tripping over. Is this setup running inside of something like proxmox by chance.
But on a plus note that arrangement looks a lot closer to Rockstor native as you at least now have the redirect roles in place and, bar the mystery drive, all the ‘mapped to a pool’ icons.
Lets see what that command puts out? Probably best to preceded and follow the paste with lines containing only ``` (ie 3 backticks) as then it should format better for examination directly on the forum.
Thanks for persevering as it would be good to get this one sorted, although I haven’t seen the like of it for quite some time. Once we establish what’s going wrong we can open an issue to address it.
@g6094199 Thanks for the info.
Just having a quick glance at that output and there is something different about that drive:
Still looks like a bug as it just shouldn’t make any difference but the info may help you resolve it in the mean time.
All data drives but the problem one have no UUID on their base device: ie UUID="" this is normal I believe: ie look to the rockstor_rockstor drive.
This is based on the problem, ie strangely left out, drive being:
These UUID’s are normally only found on formatted partitions, not on the base device ie ST6000VN0033-2EE is the only device that is showing one. But all your partitions have one.
Kind of another wrinkle / complexity that can be introduced by having partitions in the first place.
As I’m not likely to get to looking further at this for a bit and it only affects partitioned devices (not our focus really) and then only if the base dev has this rather unusual UUID I’d suggest you try a slow and steady move to not using partitions buy removing that device via command line then once that’s complete wipe it using the Rockstor build in (which is actually just a “wipefs -a devname”):
or by hand of course, and then see if it still displays that UUID on it’s base dev:
My fairly strong suspicion is that we only find UUID on whole disk file systems and that is taking priority in the consequent disk scan which parses the above output. That could be a risky change to make to code that we haven’t had to touch for ages now. And that UUID on base dev is potentially misleading / confusing.
By way of an example here is a 2 data disk Rockstor and as per yours the rockstor_rockstor system disk base dev has no UUID but the 2 whole disk btrfs do and that UUID matches that of the btrfs fs:
btrfs fi show
Label: 'rockstor_rockstor' uuid: 7d3c7e55-d732-43d0-97f0-4769e10df411
Total devices 1 FS bytes used 2.07GiB
devid 1 size 12.93GiB used 4.30GiB path /dev/sdc3
Label: 'rock-pool' uuid: 3de597ec-842a-414e-b40b-f06fc5763de1
Total devices 2 FS bytes used 489.25MiB
devid 1 size 2.73TiB used 2.03GiB path /dev/sdb
devid 2 size 2.73TiB used 2.03GiB path /dev/sda
as does the sdc3 UUID ie matching the rockstor_rockstor UUID from the above command.
It’s as if your ‘problem’ disk has previously been formatted as a whole disk and has then been partitioned up and there is sill a whole disk fs reminant by way of the base dev UUID.
Hope that makes sense and gives you the means by which it can get sorted. I.e remove that disk via command line from the pool and properly wipe it then add it back and re-do the import trick.
Thanks again for the report but as it’s a pretty tight corner case I think it’s unlikely I’ll get to it for a bit so hence the hack guide. Plus you may have what amounts to a partial signature on that drive from a prior use which may end up haunting your (which of course it is kind of in this thread’s topic).
Let us know how you get on.
Oh and if you take a look at the wipefs man page
man wipefs
there is a -n switch that will allow you to run it and only show what it thinks are the disk’s signatures. Might be interesting as to where that signature / UUID on the base dev comes from. Might even still show up after the btrfs remove command. Obviously a fairly dangerous command to play with though so take care with that one.
Safer alternative would be:
udevadm info -q all /dev/disk/by-id/base-devname
Pointing it at the base device name rather than a “-part1” name and you may see info on what’s contributing the UUID
Just a though and maybe it will help you get up and running all ‘proper’ as it were.
This makes sense to me as in fact i always do try run/strss test on new disks before adding the to a fs to find early failing disks. As i can remember iI used the whole disk on these tests.
I will follow your advise and remove the partitions fom all disks step by step. Hope this will uncompicate things for now and the future.
Great so that would account for it. That’s a relief. Always best to do a proper wipe prior to new fs / or partitioning, especially if the last fs was a whole disk variant (rare) and one is to there after partition.
Yes this is a nice, if rather time consuming practice. We have an element of this in our: Pre-Install Best Practice (PBP) doc by way of the Wiping Disks (DBAN) subsection. Not really a proper stress test though, more of a write to all parts of the disk kind of thing. If you’ve got any suggestions on other more ‘proper’ stress tests, they could be put as entries in that same doc. I know a few programs exist for this but I’m not overly familiar with any.
Thanks for working through this one and let us know how it goes.