@g6094199 Thanks for the extra info.
Sorry but I forgot to ask the Rockstor version you are on?
Also I’m assuming the pool was not originally created within Rockstor and that you have manually mounted at /mnt2/btrfs (ie no mount on boot).
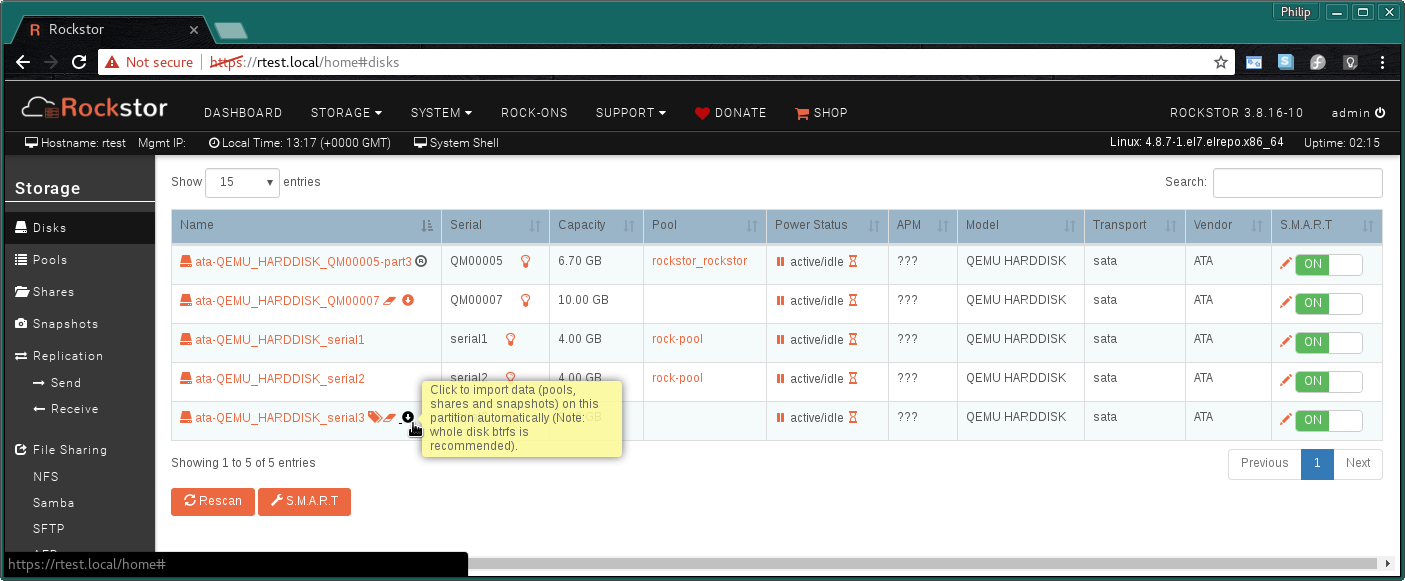
I’m not quite sure how the mount even worked ‘before’ when there are not redirect roles in play, ie if your Rockstor version is new enough (which I think it is) then every disk that is part of a pool managed by Rockstor must be either a whole disk btrfs member (ie not partition table) or the specific partition you are interested in has to be selected per device (via the cog). Only your systems state is not familiar to me in that it is populating the pool column without without any re-direct roles on any of the members: it’s required on them all and were the pool to have been imported they would have been (hopefully) auto added on all but the first drive used for the import.
My initial ‘fix / work around’ would be to boot the rockstor system drive with all drives detached (possibly by booting the usb system disk on another machine as may be easier). During that boot you could delete all the ‘detached-’ device entries which will give you a clean slate. Then shut that down and re-insert to your nice 4 drive system and then follow the instructions on re-importing from a device that has btrfs in partition:
Import BTRFS in partition
“But if all pool members are partitions then a manually applied ‘redirect role’ will be needed on one of the pool members in order to enable the import icon on that member. During the import all other partitioned members of the pool will have their required redirect roles applied automatically.”
N.B. DO NOT delete the existing pool with drives attached as that will remove all subvols etc: but it does aNnounce / warn that this is going to take place and that there will be data loss. We need to add a ‘remove from database only’ option on that one ![]() .
.
My suggestion is heavy handed I know but your are not currently in a working state anyway as far as I can see as there are no redirect roles in play so Rockstor doesn’t really manage these disks. You will also have to recreate exports etc so not sure how much of a pain that is going to be.
From the docs we have the following indicating when a partitioned disk has a redirect role in play and is ready for import:
If you are using Rockstor as an ‘add on’ to manually created and managed pools then you may be out on a limb here so it’s difficult to know whats going on as Rockstor does impose certain restrictions that are not prescent in the underlying technology and so it’s behaviour in such circumstances is ‘undefined’.
Hope that helps and do read that import section as it may give you an option to start over and have Rockstor manage your pool and share more as it was designed. Assuming of course your pool can be imported: a test of which could be a fresh install on another usb device and try the ‘Import BTRFS in partition’ approach on that install. Then if it fails you can sort from there on that install knowing you always have the existing usb dev to boot as if nothing had happened as it will still be in it’s current state.
Hope that helps and let us know how you get on.
Please note however that btrfs in partition is very much a young facility within Rockstor, but at least once you have all your disks and redirect roles in line you could alter in place (if backups are up to date of course) by sequentially removing (via resize), wiping, re-adding (via resize) each disk in turn. Waiting of course for each balance to finish. Or not ![]()
Let us know the Rockstor version first though as redirect role may not even be on your version.
Also if you are on stable channel best to post output of:
yum info rockstor
Just in case (I found and fixed a recent bug re version number reporting).