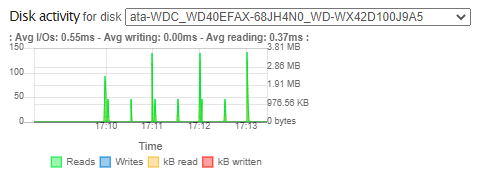
My non-active disk drive does not go to sleep at all with version 4.0.1. This drive is not attached to anything. It use to sleep all the time in version 3.9.1 with the same configuration.
It’s a brand new disk model WDC WD40EFAX-68JH4N0
The Rockstor dashboard shows that it’s reading from it every 30 seconds
Could you specify the configuration for spin down that you’ve used with this drive.
Although from your graph it now does look very much like something is accessing the drive which of course would stop it from entering sleep anyway.
That dashboard widget, by way of context, surfaces the metrics found in /proc/diskstats:
Just in case we are seeing a miss reported activity here.
cat /proc/diskstats
or for a live output of changes:
watch -d 'cat /proc/diskstats'
and the output of the following during the same boot session will be required to work backwards to the by-id names used in the Rockstor Web-UI:
ls -la /dev/disk/by-id/
The iotop program may be a useful tool for the job here:
zypper in iotop
“man iotop” should help with the options and you will likely want the “-o” one. You should be able to see which process is potentially accessing this drive.
Also, to double check if this drive is associated with a pool could you paste the output of the following:
btrfs fi show
Other forum members may have more informed ideas on how we can track down the suspected background process running here that is keeping this drive awake. Assuming it’s not just a miss report on the Dashboard. Also, does the drive still stay awake when the Rockstor Web-UI is not running. I.e. closed completely and not open on any system. The Dashboard processes themselves could be causing this pooling, even though the drive is no a pool member. Also does the drive have any other filesystem on it, and if so is it mounted for instance:
cat /proc/mounts
There may well be a differences in how other filesystems are treated here.
Hope that helps, if only to get a little more context for others to chip in if they are able to.
Although you may have a preference for the slightly more shiny Netdata Rock-on which may also help with what’s going on here. You can always turn it off/uninstall once the offending program / system has been tracked down. Although Netdata is surprisingly light footed given the massive number of things it tracks.
And in case you’re not familiar with the Rock-on initial setup, see our following doc entry:
Iotop, by default, is not accumulative; it only shows transient access. The access shown there is normal and is associated with normal rockstor access to presumably refresh the Web-UI header. Login via ssh and try, with the Rockstor Web-UI closed completely, or as suggested install the netdata and access it’s Web-UI as we just need more info on this one. I’ll see if I can reproduce locally but it won’t be for a little while I’m afraid.
Yes this is what it looked like from your prior post. But my requested command outputs were looking to see if this was a red hearing or a miss drive reporting. Hence the “watch -d ‘cat /proc/diskstats’” and ls command output requests. That way we can rule those things out. I.e. is it really being kept awake by the reported disk access or is the spin down setting that you have yet to specify not taking effect. To help to clarify if we are talking about the same spin down setting take a look at the following doc entry:
Also, to help with the diagnosis, we will need the outputs of the previously suggested commands and questions. I.e. the proc/mounts and
and from earlier:
and:
As we may just have a read herring here. All info requested will help others help you diagnose this which in turn may well turn up a bug or otherwise overlooked or changed issue. The more info the better really especially given it looks to be transient repeated access to a drive this not in any pool. Hence question on exact config of this drive, i.e. it’s filesystem and the assumed spin down config already applied. A little tedious potentially I know but it really helps to know if the drive is even mounted or if it’s just a smartmontools/S.M.A.R.T default update thing.
Maybe others with this drive model can chip in here, once we know the applied spin setting used by @Tony_Cristiano. Also note that spindown settings are often not persisted form one boot to the next, hence Rockstor using an hdparm systemd service to re-establish any spindown applied via the Web-UI each time the system boots up.
So in short:
From just that no. Unless that is the only activity you see and you have captured just that bit. In which case we need more info and a different tool. Those familiar with monitoring transient disk access are welcome to chip in as I’m afraid I can’t spend much time on this currently.
I’ve not reproduced just yet but I have seen the following:
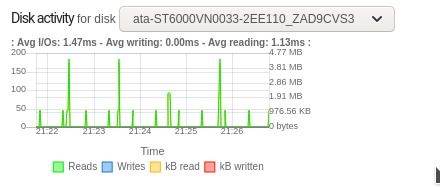
Yet this new drive, which I’ve just attached to a Rockstor 4 instance, is not being woken up by these accesses, at least not for a while, after I’ve pressed the pause button on this drive with the tooltip: “Force drive into Standby mode” within the disks overview table.
This approach of ‘pausing’ the drive and looking to see what or how long before it wakes up may be helpful in diagnosing this issue. I’ve not tried any power down config on this drive just yet but just thought I’d post the pause button thing and the indication of non waking ‘reads’ which does look odd to me.
I have to press this drive into ‘action’ soon but just noting what I’ve seen here of late.
I can confirm however that the spikes of read in the Dashboard do correlate with this ‘spare’ drive’s canonical name within /proc/diskstats. I.e. watching /proc/diskstats shows activity against the correct /dev/sdx name that relates to this drives by-id name. So looks like our activity monitor is OK on that front.
I’ll update if I manage to look into this further before I have to add this drive to it’s intended pool. But I should get the chance again soon to duplicate this arrangement as I have another system that has to have a drive added.
Hi
Yes, I did what you did with the “Pause” button and my drive just became awake directly after that. So, I couldn’t get my drive to stay in standby mode at all.
When I killed the dashboard and used a terminal only the /proc/diskstats showed no activity on the drive. Therefore, in my case, it was the dashboard causing the read activity and keeping the drive awake.
I’ve attached that drive to a pool now and since then it sleeps like a baby until required.
So I’m happy with that.
By the way, I installed Netdata rockon and I love it.
@Tony_Cristiano Thanks for the update and extra info. Glad your now sorted.
We definitely have a little more work to do here, available time permitting, and interesting that the dash looked to be blocking disk sleep. I seem to remember that the disk overview page could also do this, but didn’t re-awaken drives that had already gone to sleep, at least with my test setups at the time.
The “Pause” button simply executes an:
hdparm -q -y dev-by-id-name
here:
And curious that once part of a pool it manages to sleep just dandy. There must be some kind of exploratory probe going on when no fs is found or the like that in turn is having this effect.
Anyway good to know and we can keep an eye on this behaviour and gather info in this thread as we go. I’m quite keen on having functional drive power down capabilities as it really helps with power consumption/noise etc.
Thanks for your input and at least now your drives can get some rest.
Thought you might like Netdata; that was an @Flox addition from a couple of years ago. They also have a free cloud service for up to a fairly generous number of client machines so you can get an overview of all your netdata instances. I believe you sign-up ‘in the cloud’ and then register each of your client machines with the cloud account you created.
While we’re talking about drives going into sleep mode for all the good reason, I couldn’t find any doco on how to put the whole appliance to sleep to further power save. Is this possible? I tried to schedule a suspend task but I don’t think it worked.
@Tony_Cristiano Re scheduled power down, yes, that was added a while back but no accompanying documentation was added at the time. The associated issue:
may have some info in though. There is also this suggested improvement with a forum link:
indicating a current limit of 24 hrs for wake up.
It was tested as working, but very much depends on accompanying bios settings and may well vary, success wise, between systems. It does use a standards compliant methods, i.e. acpi / RTC stuff, but as we know not all standards are all that standard!
If you can’t get the scheduled suspend bit to work but you can get the scheduled shutdown, you may have an option within the bios to wake up at a set time. There-by having Rockstor do the normal shutdown and bios do a timed power-on.
Let us know who you get on and if you fancy contributing to the docs to tend to this short fall then it would be most welcome. The docs repos is here:
And we have a dedicated doc section on how to contribute:
There has also been another power save option added that pinged another machine and if it was not found it would go to sleep. Again, another un-documented goodie awaiting doc contributions. This feature was added by @betula-pendula.
Issue:
Hope that helps and let us know how you get on. And if you become sufficiently successful or familiar with any of these do consider contributing the associated doc entries as it’s a shame we don’t have referenced to these, at least once working features in our official docs.