Hi there,
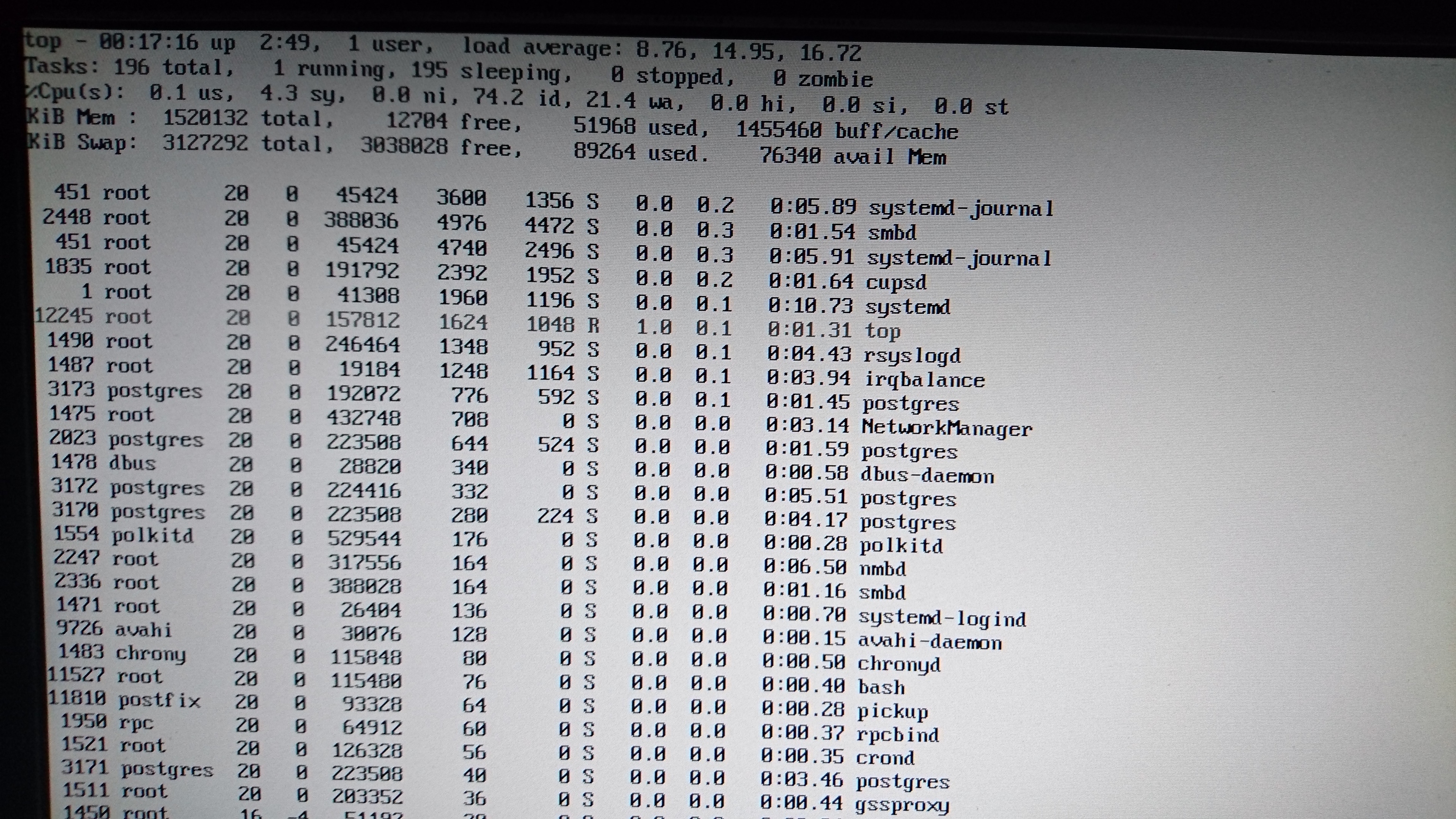
after updating to latest testing channel I keep getting these errors that I can’t track down. Rockstor complains about missing memory (granted, there are only 2 GB in the box, but that never was a problem) and kills processes. The system is so unresponsive that I usually can’t even login or start a program. I managed to start top -o %MEM to see which program eats my memory, just to find… nothing.
Any hints?
The OOM Killer selects Rockstor related processes presumably because it can free up the most by killing them and probably because other system processes are considered more important by default.
This is definitely worth investigating more. Can you tgz -f logs.tgz /opt/rockstor/var/log and send it over to support@rockstor.com? Alternatively, you can go through those logs and post the errors and patterns to the forum so more eyeballs can look at it.
Thanks @suman for your interest,
truth be told, I was about to wipe the installation clean and start anew, also because I had so many issues with this installation in the past. Chances are that one thing led to another and I now have a completely borked system.
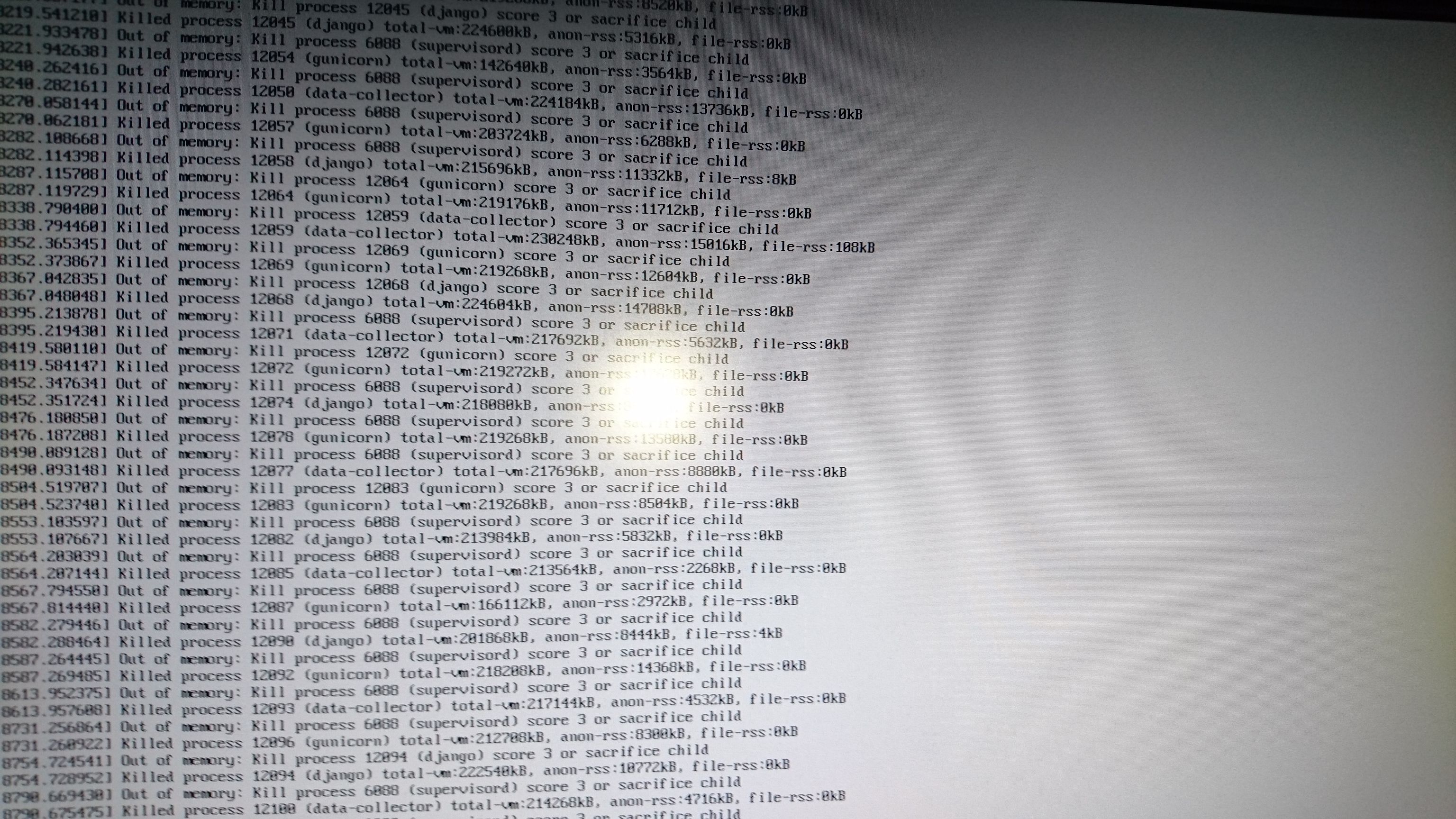
Anyways, I sent the files you asked for- there’s nothing conclusive in there I’d say, so I also captured a copy of /var/log. The only thing related is probably in the gunicorn.log:
Thanks for the logs @arneko. I think these lines provide the right clue
Mar 20 13:59:32 datengrab kernel: Out of memory: Kill process 3098 (django) score 6 or sacrifice child
Mar 20 13:59:32 datengrab kernel: Killed process 3098 (django) total-vm:396376kB, anon-rss:0kB, file-rss:0kB
Mar 20 13:59:32 datengrab kernel: btrfs-transacti invoked oom-killer: gfp_mask=0x2400840, order=0, oom_score_adj=0
Mar 20 13:59:32 datengrab kernel: btrfs-transacti cpuset=/ mems_allowed=0
the django process is taking about 400MB of RAM which is normal at times. btrfs-transaction thread is known to consume a lot of CPU, there’s a thread about it on btrfs mailing list also. I don’t have anything useful to add there, but, in this case 2GB RAM proved to be too little.
I’ll be watching out for this behavior in our environment here. And if others run into this issue, please report. I hope this is not caused by a bug in 4.4.5 kernel. But more data points the better.
Alright, fair enough. 2 GB is not a lot, and it sure is cheap enough to upgrade.
I also tried with Kernel 4.2.5 with the same issue. So I guess we can rule out a kernel regression. The one thing that bothers me is, that it seemed to run fine before the upgrade.
I will try a clean install on another drive. If that runs smooth, there has to be something else. I will also, for funsies, try to shutdown “unnecessary” services (django). Is a systemctl stop rockstor enough to achieve that?
I actually run a btrfs drive on a small ARM machine without issues (2 GB RAM) and had the same drive on a raspberry Pi (256 and 512 MB) - not in a RAID mind you, so I am a little surprised that it shouldn’t run on my x64 machine.
What about swap btw. Rockstor’s standard installation creates a swap partition, but seems to set swappiness to 1 by itself. Not sure where that happens, but I guess it’s related to my running rockstor on a USB drive.