I noticed a couple of days ago that my logs were full of the following parent transid verify failed error:
BTRFS error (device sdb): parent transid verify failed on 2763865407488 wanted 2560346 found 2586243
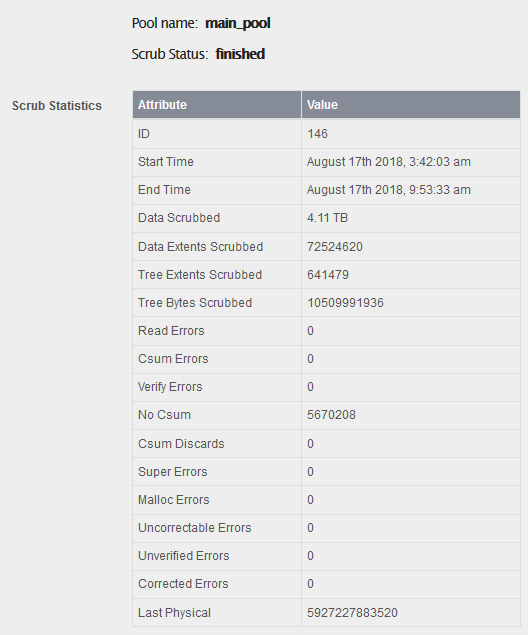
Notably, I have not observed anything not functioning or broken on my system: my NFS export seems to work (I haven’t verified my SMB ones, though), all my Rock-ons work normally. Furthermore, no errors were found in my most recent pool scrub (as per webUI’s report).
I of course would like to:
Make sure this does not reflect another substantial problem that might be lurking somewhere.
Get rid of this “error message spam” in my logs.
After some Googling, it appears that one may not worry about this error when the disk is in advance when compared to the journal like in my case (2,586,243 vs 2,560,346), and that it may be safe to clear the journal logs with btrfs-zero-log /dev/sdb (as read here on SO, for instance). However, I noticed that the btrfs-zero-log manpage says one does not need to use btrfs-zero-log if the filesystem can be mounted.
Now, what would be the best way to verify everything is fine (or not) with my system? Would a btrfs fi show or btrfs check /dev/sdb help and be recommended?
If everything is confirmed as well with regards to this error, would btrfs-zero-log be ok to use? I do remember having some other “errors” in the journal related to qgroup rescan failing, for instance, but that may be material for another topic here.
PS: my config is simple and as follows:
latest rockstor release (-32 or -33 if I remember correctly)
1 OS SDD
2 x HDD in RAID1 in a single pool (sdb is part of this).
"In a nutshell, you should look at:
btrfs scrub to detect issues on live filesystems"
Also note that on occasions btrfs log messages will indicate a drive simply because it’s the one used during the mount and that the issue relates primarily to the fs. Worth noting as it can be misleading this way, at least currently anyway.
This can happen simply because of an existing qgroup rescan, or if qgroups is disabled.
Not from what I can see. All look ok from those outputs; I just wanted to confirm we don’t have observable issues from those tools first.
As to where to go from here, I’m afraid I don’t have sufficient depth of knowledge on the parent transid verify failed issue to comment from an informed perspective so I’m going to have to refer you to other forum members who are more experienced with this particular direction of transid id error, ie the found id being greater than the know one being.
There is always the linux-btrfs mailing list to trawl, and possible quiz, given they are essential the canonical authority on btrfs. Although you may be best advised to move to the most recent ml kernel-ml from HTML Redirect and to compile the most recent btrfs-progs also prior to asking as we are slacking some what on that front unfortunately (although I do have this issue in my sights currently).
That’s all I’ve got currently. But probably best make sure all backups are in place and tested before you do anything, just in case; especially since things currently appear to be OK. It may just be that this scenario is a threat to recovery rather than ongoing service.
Thanks for your help @phillxnet! I’ll have a closer look online and see if there’s something else to do. I’m just glad nothing seems to be wrong… not at first glance at least.
@Flox Did you ever get this sorted? I’m now in the same situation.
I had some files copying from my laptop to the Roskstor system. I got up and walked away. My wife alerted me that Plex had stopped working, so I went to check on the server. It didn’t respond to pings. I hit the power button on the system to do a shutdown, but nothing happened after 30 minutes. I force power cycled it.
It started up, Plex was happy for a few minutes then it died again. No respond to pings or the web interface. I dug up another Ethernet cable and plugged it into my IPMI port (we just moved to anew house a month ago, still getting things unpacked and set up) and started a session. The IPMI web page responded, but the IPMI application couldn’t connect to a session.
So, yet again, I forced a power cycle.
This time, everything came up and stayed up and is happy, expect that I’m getting parent transid verify errors.
Edit:System died again overnight. There’s no response to pings. I can open an IPMI session, but I don’t get any response on it. Just see lots of ‘Parent transid’ errors which is what was showing when it crashed. Software shutdown on IPMI doesn’t work either. I can’t figure out a way to hold left Alt and Print Screen over IPMI so I can’t do a REISUB shutdown. I found another post that said to run a scrub to fix the transid error, but I suspect the transid error is a side effect of these lockups, not the cause of them. I think I should start a new thread.