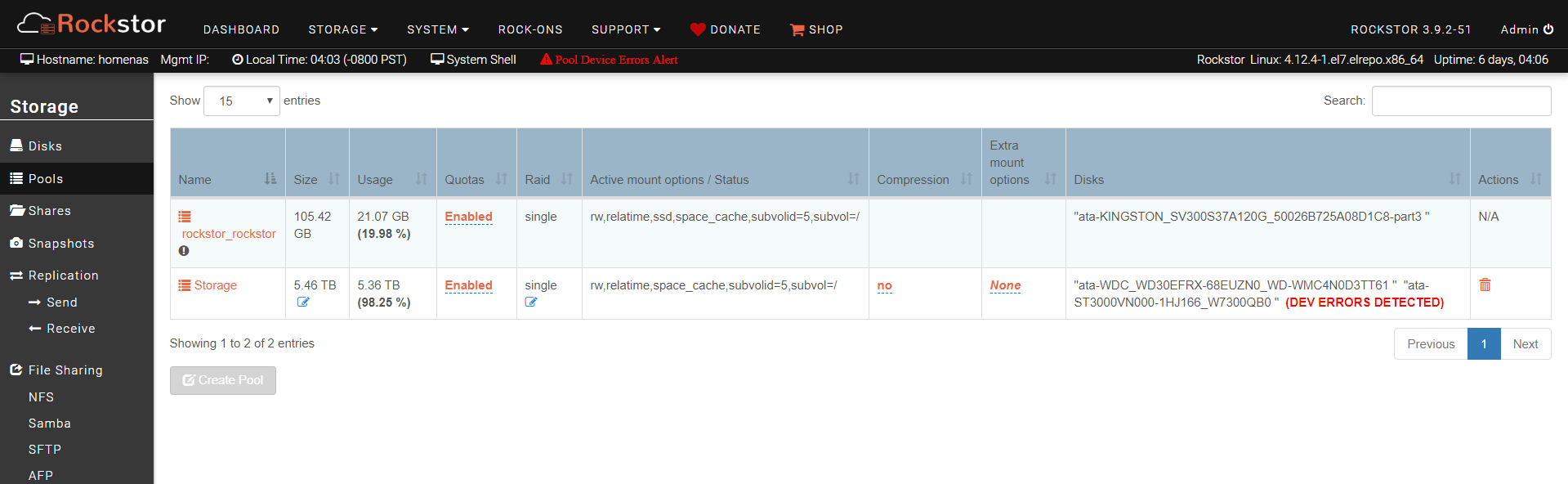
I started having troubles when i uploaded some files to my rockstor and the upload started to go super slow, then drop out, then reconnect etc. So i logged into the rockstor box and there was an error in red
" Pool Device Errors Alert"
I went back into FTP nad i couldnt delete
Error: rmdir /mnt2/*******: received failure with description ‘Failure’
there are about 100GB free of a 5TB pool.
Can anyone shed some light on whats going on>? Could my drives be failing? I cant see any info around this in the drives page.
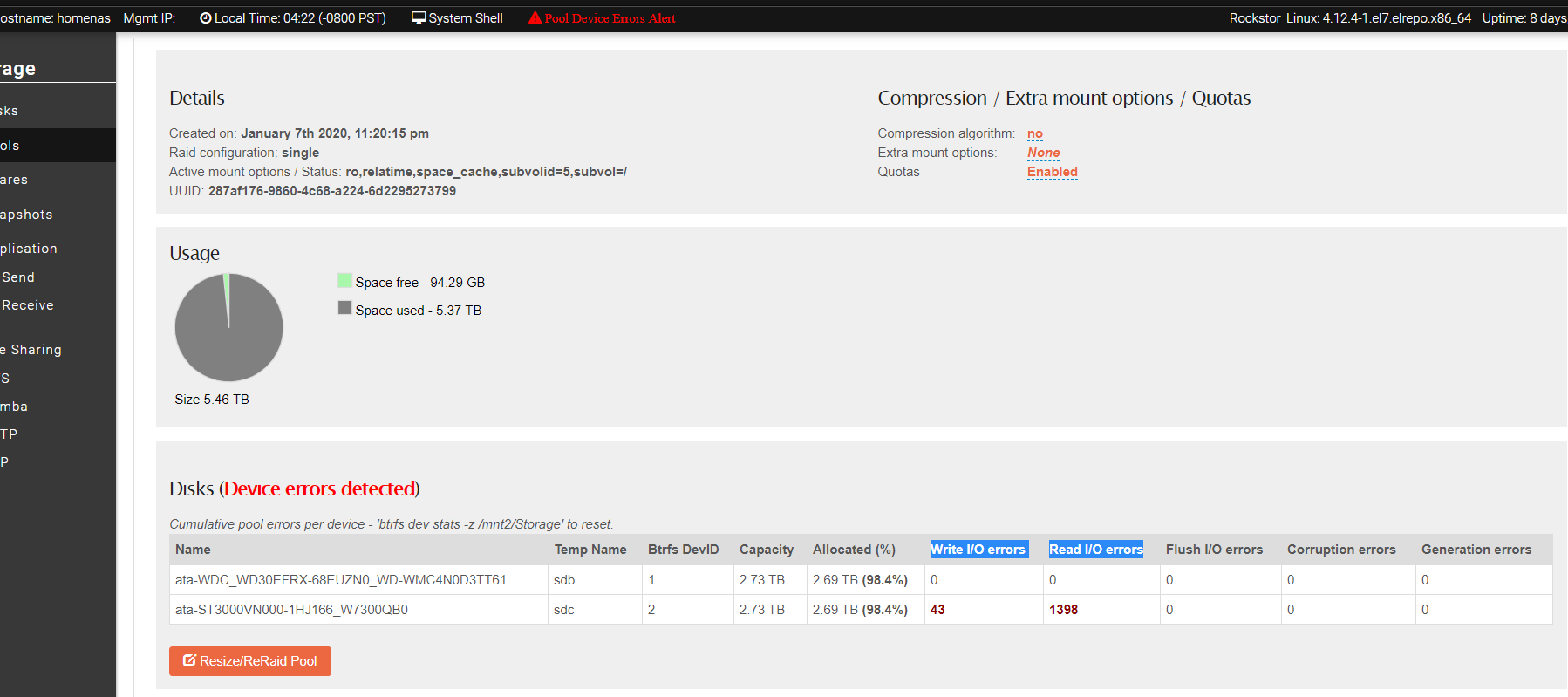
I know @phillxnet will most likely be able to give you more help, but in the meantime, you should be able to see info on the type of errors by looking at the details page for the pool in question. Just click on its name and you should see a table with the number of errors if any.
Pretty much yes. Although a faulty / loose SATA cable can cause this also. Btrfs is keeping a tally of the times it had trouble Writing and Reading. And depending on use you may be reading more often, hence more read errors. That’s pretty simplified and there are a few layers below btrfs but this does look like it could be a failing drive.
You could visit this drives S.M.A.R.T page within the Rockstor Web-UI and update that page to get more info from another angle: from the drive itself in this case. See the following doc entry for where these pages are:
Do be sure to click the “Refresh” button on that page to get the latest info. If you have never visited these pages then they will initially be blank until you click that refresh button. You could compare the 2 drives S.M.A.R.T info, but given btrfs is listing having had issues with only one drive it does look to be drive/cable related.
I see that in this case you have configured your pool to be btrfs ‘single’. That is ‘all space and no redundancy’ that means there is only a single copy of data so btrfs has no means of repair. So when these read / write errors happened it had no ‘fall back’ to a second copy of any data. It also means that if the drives couldn’t ‘get around’ these errors you pool may be toast. But then the pool is also really really full so presumably space was more important than data safety / self healing capability. I would look to the integrity of your backups as soon as possible in this scenario, if relevant.
Also note that on this page the pool is indicated as being ro (read - only)! Btrfs, when in distress, will turn a pool to read-only to prevent further ‘damage’. It is likely that this pool, being of only a single raid level, had no ability to self heal and these disk/cable errors have caused it to go ro to protect what’s left. Hence the backup suggestion above. When the data is more important than the available space you are best advised to use btrfs raid levels of 1 or 10. See our Pools doc section of a rough break down of the btrfs raid levels.
The S.M.A.R.T page for the disk at issue doesn’t show anything in error logs and Overall Health Self-Assessment Test shows as passed. I tried switching the cables between the disks and it still showing the same disk as the one with read error.
I’m really confused now, should I go ahead and replace the drive?
These pool error stats are cumulative, i.e. they will stay the same until reset by the indicated command. But the fact that there are errors (or an error) showing does not, in itself, cause issues: it’s just reporting the current tally of errors to date. These are on the btrfs level. They may or may not be reflected in S.M.A.R.T stats.
But the fact that your pool has gone read-only does indicate that the encountered error may well have lead to a situation where the pool is not able to self correct. Btrfs goes read only when it encounters serious anomalies that it can’t just side step. And a device that can’t be read, even once, may lead to this read-only ‘save my data’ state.
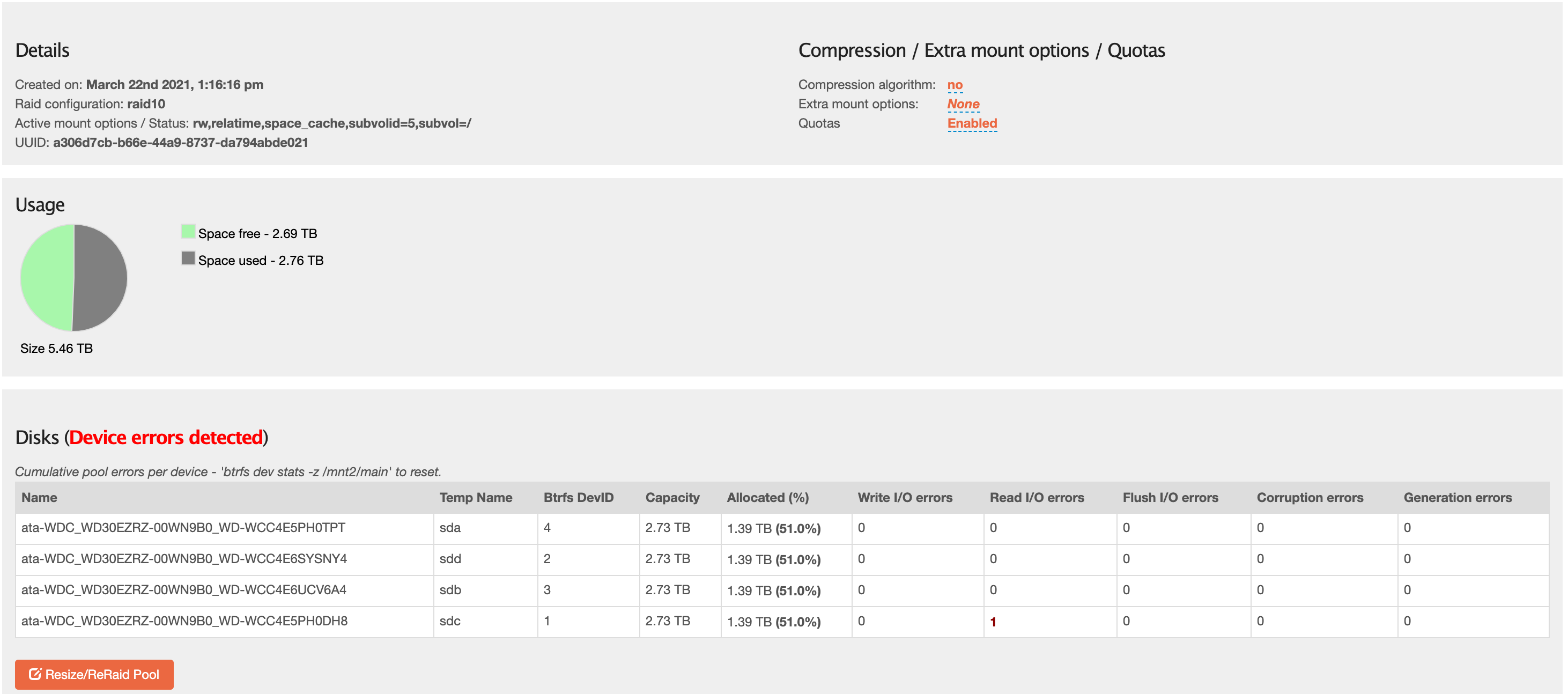
So given your disk count is the minimum for raid 10, and one disk is having difficulties, this could be the cause of the read-only state. Best start off with refreshing your backups given you still have read-only access to the pool’s data. Then assess your options from there on.
Keep in mind that once you have refreshed your backups, mounting the same pool with the suspect drive missing, for example to add a fresh drive or change the raid level, will require a degraded mount option as the pool will then have fewer than minimum members.
I’ve had a similar error message - but in my case there is only 1 Read error so I was going to clear the fault and keep an eye on it. There is a helpful message which says the command to clear the fault is:
btrfs dev stats -z /mnt2/Media
When I go to System Shell and try to run it, I get the message
btrfs: command not found.
Should I just go ahead and install the btrfs package? Sorry I am not familiar with OpenSUSE and thought I would check first.
This is most likely due to you not running as the “root” user. Other users generally can’t run system level stuff and so it’s often not even in those users path (where stuff is looked for).
So once you are running as the “root” user you should have access to the suggested command. It does not require installing as we use it extensively under-the-hood to do the btrfs management via the Web-UI.
Doh! Thanks for your patience - should have thought of that but the nice UI makes me forget about using root on occasion. All errors now cleared and will see if they reappear. Many thanks