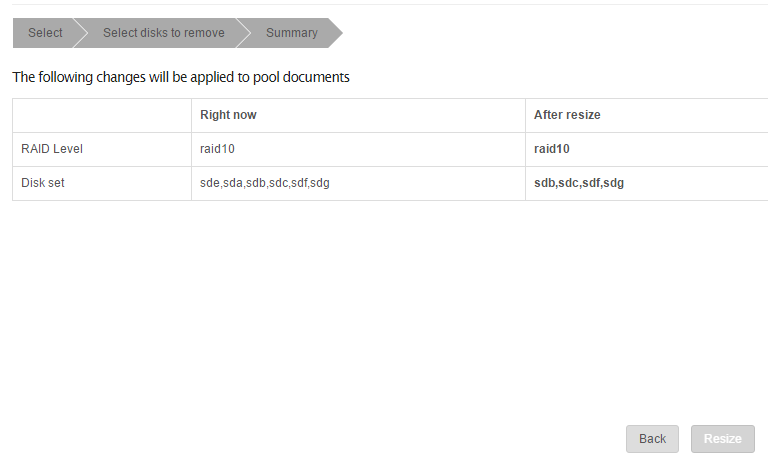
also it might be possible that the gui somewhat mixed things up during your attempts to add a disk (going back in the wizard and selecting another option leads to the same selection as the previous, seems like a bug)
this being said im able to do this, which should not be possible to do:
what is your raid type?
it seems you used raid1 initially
the disks sda and sde have been added?
you should start a balance if you use anything different than single as currently your data is on sdb and sdc only
if the gui is still mixed up try starting a new resize and select “change raid level” and set to the desired setting but dont add any drives
There is some issue if the user goes back and forth on the wizard screens before hitting the resize button. Is that what may have happened @bdarcus? Are you all set now?
[quote=“suman, post:8, topic:454”]
There is some issue if the user goes back and forth on the wizard screens before hitting the resize button. Is that what may have happened @bdarcus?[/quote]
Am not sure. I don’t recall doing so, but it’s possible.
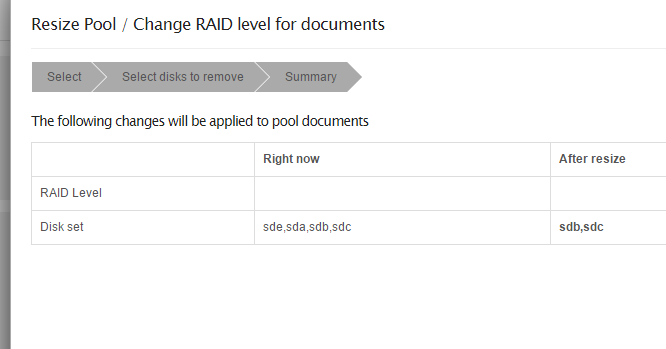
Actually, go back to my first post, and reproduce. I want to keep my same RAID1 config, but add two drives. I go to do that, but system won’t let me, etc.
Here’s another bug. I want to remove two drives from the four drive RAID10. I specify those two drives, so that the end result will be two drives in the pool. Hence, RAID 10 will not be possible. But Rockstor assumes RAID 10 will be the result.
PS - notwithstanding this, what’s the best way to just replace two drives?
That’s more of a feature than a bug at this point this is why.
If you click resize with that config, you will get the error you expect about 4 disk minimum for raid10. It’s just that the validation is handled on the server side and you need to click resize to trigger it.
At this point I don’t want to duplicate validation both on the frontend and backbend. But we will in the future as btrfs behavior settles down and our understanding gets better.
To replace two drives you need to add 2, and then remove the other two after the first resize finishes. So two resize operations in total. Perhaps we need to support add and remove together to save on balance times. But again this is one of those operations with many variables and uncertainty and needs to be tested and understood better.
But the way the UI is setup leaves this user uncertain about that. So you may want to note that in the “The following changes …” text? Maybe “The following changes will be applied to the pool documents. Note that (currently) [insert whatever description]”
The button is disabled/grayed-out during the time it takes the server to respond. It usually happens fast enough that it’s not noticeable, but in this case, looks like server not only took time, but also threw an error. A screenshot of the error would have been helpful, but logs should have useful info.
What does that output of btrfs fi show look like?
Could you also share the screenshot of the Storage -> Disks screen? Also, if you think btrfs balance finished successfully, but still see that the UI attributes sde and sda to the pool, could you click on the rescan button on the Disks’s screen so see if that updates the UI?
Thank you for patiently providing detailed information. I am finishing up on a different issue, but I’ll thoroughly test all resize code paths right after that.
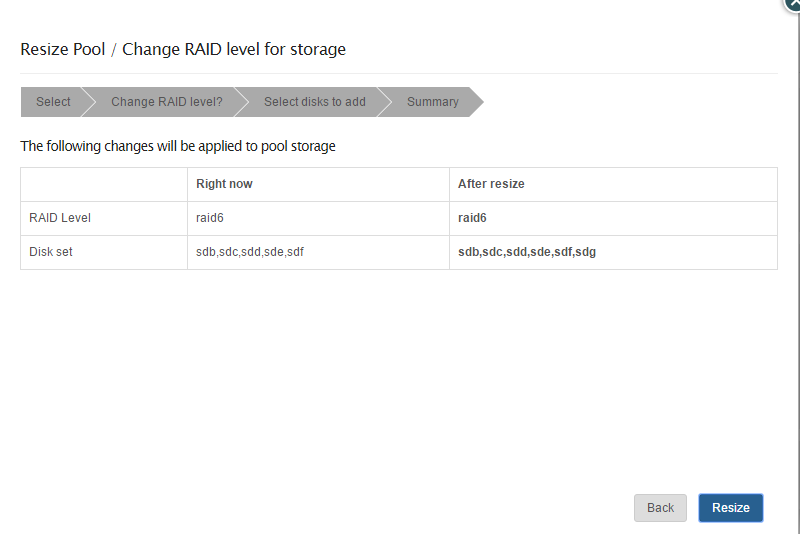
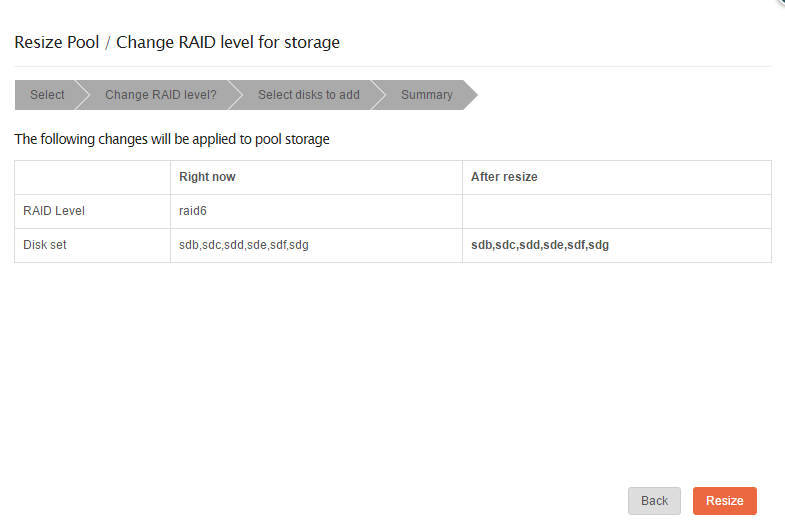
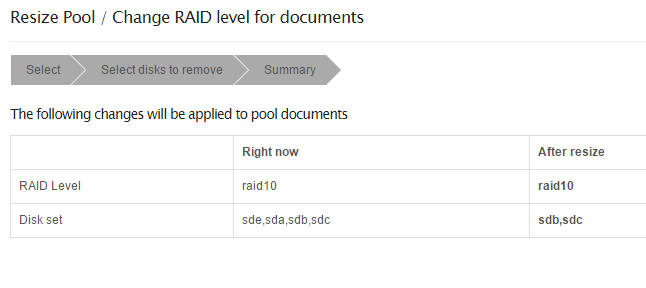
 this is why.
this is why.