This is similar to my issue, with a problematic complication.
After removing a disk and putting a different one in, the disk order changed and the pools got … confused?
Checking the btrfs volumes/subvolumes they are assigned to the correct sdX dev nodes. However, they are being mounted in the wrong places. The most problematic one, is showing a two disk pool sdd, sde. Unfortunately, sdd is actually the disk rockstor is installed on (SSD). sde is being mounted as a subvolume of the /root subvolume of the install disk. sde is also being mounted with the SSD option flag, though it’s a HDD.
sdd shows the “trashcan” icon but I’m nervous about using it, since I don’t know what command will actually be issued. sdd contains the OS, and in the disk GUI sdd shares the same serial number as sde. Best case would be it doesn’t do anything at all. Worst case is it erases sde or sdd.
I’ve used the btrfs tools to check/confirm the volume/subvolume id’s of the affected disks, and I can umount/remount them all manually, but I’m guessing it will be messed up again next reboot.
I ended up putting all my shares into /etc/fstab addressed by UUID. Not ideal of course, but guaranteed to work. It’s probably your best bet until Rockstor switches to UUID.
I’m still on 3.8-9 so don’t know if there is any change of behavior, but deleting the missing disks in Rockstor GUI simply deletes Rockstors’s housekeeping records for the disk, and wouldn’t actually touch your volumes.
subvolume pools and shares are mounted to /mnt2/<pool>/<share>. However, the shares also appear as /mnt2/<share>. Is that normal behavior, and are they mounted using --bind?
I have the same problem where the disks changed physical order on the machine when I rebooted it. I’m running inside virtualbox over windows 7, but I can see that the device id’s changed by running (wmic diskdrive list brief). I can edit the files mapping the physical disk drives to names (they are *.vmdk in virtual box), but I just want this work. I remapped the vmdk files and restarted, and one of the disks is stubbornly misassigned to it’s pool, probably because of some related kind of issue.
In my system, it insists on assigning disk sdd to a pool, when it should be sdb. What are the commands to force mounting disks to known locations? I’m afraid I’ll lose my hours of setting things up, only to see it gone on my next os restart.
@baldusjm I’ll have to leave your other questions re pools mounting in the wrong place to others but I can address the:-
This is an artefact of 3.8-10 (stable channel and earlier) retaining the device name for drives that have since moved and just to confuse things further it also incorrectly attributes missing drives with current dives details. Obviously very confusing however to fix it required a deep change that wasn’t ready for the last stable release however that change was put into effect at the beginning of the current testing channel, see the first post in the 3.8-11 dev log. This fixed the “… disk showing wrong disk details” issue. This issue is worth a look as it demonstrates, with screen grabs, the before and after nature and as can be seen replicates your findings of a moved / missing drive being miss represented with an existing drives serial etc. In the last 2 pics you can see that the newer system drops removed drives previous dev names and retains their correct info. The dev name is replaced by a long random string to avoid the confusion caused by the old dev name. The new system only uses dev names found by the most recent scan of attached devices; given that in modern systems these dev names jump around all over the place from boot to boot.
If all goes well there should soon be a new stable channel release which will incorporate this fix / enhancement. Note that you’re current database entries will be re-interpreted by the new system on the first re-scan and should then, hopefully, appear less confusing. ie there should be no dev name against removed / missing devices. The dev name is actually for display purposes only as Rockstor evaluates drives by their serial number as this is the only unique property of the hardware as any uuid’s are at a higher level, ie the partitions, but Rockstor has to keep track of the disks themselves and this repeated / missleading info is disk tracking related primarily. So this should address your:-
and hopefully also addresses:-
As when your drives are re-scanned with the new system the details for attached and missing disks on the “Disks” page should be less confusing as only attached disks will have recognizable device names. And if you doubt the information is current then just do a “Rescan” via the button which re-scans the attached drives and update the database as best as it can.
All fixes mentioned are in current testing channel and should be available shortly in the next stable release update.
Thanks for the explanation and pointer. I think that is what happened to me, I did remove a disk. The question is, how can I fix it now? I just want to get back to a working state. Basically, where is it storing the information for what it thinks is the disks, and the assignment of disks to pools and shares?
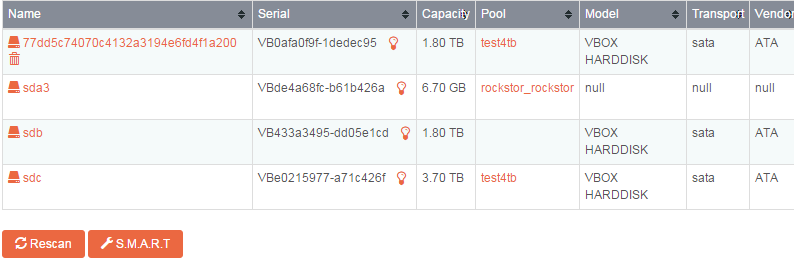
I installed the new release and rebooted my system. Things changed but the problem is not fixed. The disk I added and then later removed (removed it as part of trying to fix the problem with bad disk mapping) now properly is the one listed in the jpeg top with id 77dd… with the trashcan icon. It’s not currently in my box. I had to try multiple times to get it removed (kept getting an error when i clicked the icon that the disk wasn’t in the system). I have the error.tgz but I can’t upload it). Finally it did go away. Now the disks shows the same thing as before, except the 77dd disk is gone.
Notice the pool test4tb. That used to go across disks sdc and sdb (somehow I am guessing the catalog of btrfs shares got messed up during the time that the wrong disks were mapped). How can I fix the mapping and pools and other things to be correct? I feel like I just need to manually edit that mapping and put test4tb on that disk sdb (serial # …de4a6…26a) and it would work.
@Nick OK, thanks for reporting back. So it looks like the fix has done it’s job of no longer identifying removed drives by existing drive details, which was the focus of that issue, and to make things clearer by not using existing device names but those long random strings instead. I’m pretty sure that your removal issues were connected to the fact that the long string, which identifies the database entry for the missing drive, changes with each boot / Rescan, as can the device names. I suspect your success was as a result of recently having used Rescan so that the info was up to date. This need to be improved, maybe a suggestion to first Rescan prior to any Delete, which is good practice anyway. I have opened an issue to address that.
I do have a little confusion as per your current drive state (after removing the missing 1.8TB ec95 drive entry), you state things are the same as in the image, minus the now removed missing drive entry, but you also say that the drive with serial ending 26a should be part of the test4tb pool but it is shown in the image as your rockstor_rockstor drive so is unlikely to be part of any other pool. Note that Rockstor keeps track of drives by their serial numbers.
When every the Rescan button is pressed the db is updated with what it sees attached and what it has seen is retained (but with a different name) until the non sensed / missing drives are removed from the db manually via the bin icon. I’m afraid the pool allocation logic I’m going to have to deferrer to @suman . But I would say that Rockstor at least thinks you only have one connected drive that is known to your test4tb pool.
Did you create the test4tb pool from within the Rockstor WebUI?
Could you paste the output of the following command so we can see what btrfs says of your pool arrangement:-
btrfs fi show
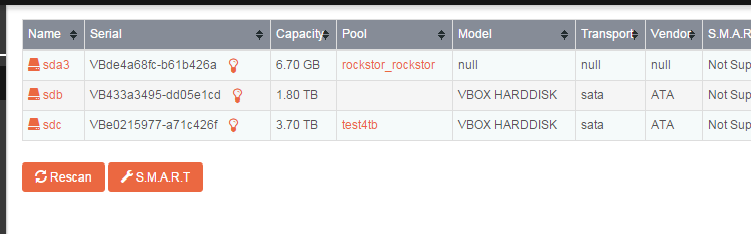
along with a current screen grab of the disks page on the same boot instance as the above command.
Thanks for the response! Yes, I created the pools using the rockstor UI. I’m guessing I have lost the previous data and should recreate it from scratch. I also had an afp that I was using to backup my mac. The 4tb disk sdc is a brand new disk, so it’s disappointing if it has a bad block or some other write error, as the btrfs fi show command suggests:
brtfs fi show
ERROR: could not open /dev/block/8:3
ERROR: could not open /dev/sdc
When I refresh the disks in the UI, I always get “BTRFS: open_ctree failed, … failed to read chunk tree on sdc.”
I have to be root to run btrfs fi show of course, sorry. When I run it as root, I get:
Label: ‘rockstor_rockstor’ uuid: d71e366d-0ae3-4600-801e-01f40ba7a6f3
Total devices 1 FS bytes used 1.65GiB
devid 1 size 6.71GiB used 3.39GiB path /dev/sda3
Label: ‘fred’ uuid: 964eba90-b0a4-43b3-96d6-f9c7b63cb116
Total devices 1 FS bytes used 432.00KiB
devid 1 size 1.82TiB used 1.02GiB path /dev/sdb
warning devid 2 not found already
Label: ‘test4tb’ uuid: 3354b75d-053e-4114-81ce-6ed103658465
Total devices 2 FS bytes used 885.72GiB
devid 1 size 3.64TiB used 888.02GiB path /dev/sdc
*** Some devices missing