hello so far love this software after trying many others if i can get this on issue resolved it will be perfect!
my setup vmware esxi 6 running on a dell r720 my disks are connected to a netapp disk shelf the drives are sata this is connected to a lsi controller that is just passing the disks to rockstor version 3.9.1-0.
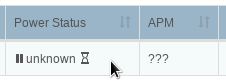
my issue is i know these drives support standby as they worked in freenas but the hourglass icon is grayed out and i am unable to enter the apm settings.
i found this post
it is 4 years old and tried a few of the suggestions but they did not work or i did not fully understand them or may be the fact that this is 4 years old im not very familiar with linux at all so if any one has a sugestion or where to start pleas explain it for a linux noob thanks in advance!
Glad your liking things so far. Not sure I can resolve your issue but I can chip in with more info hopefully.
FreeNAS is not linux based but nanoBSD based so the comparison is not relevant unfortunately.
I’m assuming you have the following:
Now to how Rockstor decides to grey out apm the hourglass icon.
This drive power down / apm setting feature was added in the following pull request:
which in turn details how this feature was implemented on the linux side of things.
Essentially we use the hdparm utility; quoting from the pr:
"The hdparm switches used are -C to set idle spin down time and -B to read and set APM level.
N.B. It is not possible to read a drives current setting for -C (idle spin down) which complicates matters, the meaning for these values can also vary between drives. The settings used are drawn from man hdparm and are apparently more reliable for newer drives.
Hdparm settings are maintained over a reboot but not over a power cycle. To address this a new stand alone rockstor systemd service is introduced (rockstor-hdparm.service). It does not depend on any other rockstor systemd service and no other rockstor service depends on it. The service is used simply to execute the tested hdparm commands that are otherwise executed on demand via the WebUI. That is if no error message and no non zero return code is received from a proposed (via user config entry) hdparm command then that same command is placed in this systemd service unit to be applied on the next boot to address the power cycle loss of these settings otherwise."
Now I’m going to work through the code hierarchy so that if we find a bug anyone with time/capability to address this can have both this sketch and the pr as a reference on how how this all works.
The decision as to if the related hdparm options are to be offered (greyed out hour glass or not) is dependant on the following code:
First the front end (Web-UI) html template code:
So we see that if poweStateNullorUnknown is True we show the icons but don’t give them a link. This is the greyed out state, otherwise they are orange which is the link colour to the settings page.
And poweStateNullorUnknown is a handlebar helper convenience function that is defined here:
The untested comment was due to me at the time accomodating major concurrent changes in these areas of the code that were to be merged just prior to my pull request. They ended up working as intended, we just need to update those comments.
So the this.power_state fed into the handlebar helpers from the html template comes from each disk object in turn. This is defined as a property within the Django disk model itself here:
Which in turn references the get_disk_power_status() which is from the import:
located in our system.osi:
Where we are approaching the ‘linux’ level:
So it looks like if the entire thing is greyed out it is because get_disk_power_status() returned “unknown” for your drive:
This procedure, as per the pr description, uses the hdparm command so we then look to see if it sees what it thinks it sees. I.e. is the output of the specific hdparm, for your drive, actually unknown.
From the comments and the rest of the code:
we see that the specific command run, skipping the intracasies of the device name retrieval, is:
hdparm -C -q /dev/disk/by-id/whatever-it-is
By way of example if I execute that on a real device here that is ‘supported’ we have:
hdparm -C -q /dev/disk/by-id/ata-ST3000VN000-1HJ166_W6A0J98V
drive state is: active/idle
echo $?
0
which has no error line out and gives us the 4 fields the last bit of code expects. We then strip out the last column ([3]) and return it. Hence the display for that drive is then: “active/idle”.
If we now execute that same command on say a virtio device that doesn’t support power down and is where I got the first “unknown” image from in this post, we have:
hdparm -C -q /dev/disk/by-id/virtio-13579
drive state is: unknown
echo $?
25
So here we have no error line but a code (which is ignored currently anyway) but hdparm tells us anyway that it is “unknown” and thus we treat it as such and grey out the table cell contents by the above mechanism.
My strong suspicion is that as your are ‘passing’ drives through via ESXI to the linux that is Rockstor, ESXI is failing to pass this info in a way it can be used. Rockstor’s expects to be in direct control of hardware and some ‘passthrough’ variants are in part ‘fake’ and so don’t appear as ‘real’ or are in some way masked. The raid controller reference you sighted in an example of this in hardware rather than hypervisor and so ‘special’ attention needs to be taken in that case, ie sometimes specific to the particular controller / driver.
So to see what’s output from your hdparm for the specific drive first get your dive names from:
ls -la /dev/disk/by-id/
and select one that is showing this greyed out “Power Status” column. Rockstor’s Web-UI uses these names. It might also be helpful for you to also execute the echo command directly after the hdparm command as we can then see what the error return code was.
It may be to get this function you will have to pass the controller itself through to Rockstor, or run Rockstor on real hardware. Lets see what the output is from your version of this command:
So in short we now have the code path that ‘greys out’ this “Power Status” column but you have 2 potential confounding factors. You may be using an lsi raid controller, you state only that it is lsi, and you are running Rockstor within a hypervisor that may mask some elements of what is available to the linux that Rockstor users (CentOS in your case). Both are big blockers but lets just see what that command outputs.
If the issue is ‘just’ the LSI controller, assuming it’s a raid controller, then there is another way to set drive spin down that is as yet not supported by Rockstor; but we do have the following issue open that details this other way:
Quoting from that issue for convenience:
“Currently -d and -T options are supported; however in some instances it may be useful to support the: “–set” parameter such as to provide a work around for those drives where the hdparm command is unable to set spin down times due to certain LSI controllers not implementing this function of hdparm.”
From there you will see that the alternative way to configure a drives standby time is via smartctl. And that issue details how this might be done via an extension of our existing Disk Custom S.M.A.R.T Options but this is only a sketch up and not as yet proven as a workable proposition.
But again you state passing just the drives through, this I think means that if it is the LSI controller not allowing hdparm to report, set spindown then you will have to do this in the modified “linux” that is the ESXi leve as that is the only thing that has direct access to this controller.
Hope that helps, at least to clarify the levels involved here; both in hypervisor / rockstor as guest / drive / controller visibility at these levels and ultimately how the greyed out Web-UI element is decided upon.
My suspicion is that you will have to visit your hypervisor to do these spin down settings as it has direct access to the controller, which it in turn masks off from Rockstor and just passes the disks themselves, which hdparm may not then be able to setup spindown on. Lets see your command outputs to add a little info. And done worry if any of the above references don’t mean much to you; I have simply sketched out this stuff as then others can chip in with potential patches, suggestions more easily as the info of what happens on the Rockstor side is then there for them to do so.
wow huge response thanks ill try some of this when i get some free time today! also just to clarify the lsi controller is handed strait to the rockstor os exclusively vmware is not in the way at all as far as that goesalso the lis controller is a LSI SAS9207-8E.
Yes so that’s simplified things a little then. I’d look to that last issue references as given this info you may just be able, for now at least, to set your disk timeouts via the command line using the smartctl command.
Keep us posted on this as if there is sufficient interest that helps to prioritise feature extensions such as is detailed in that last issue reference.
The output of the suggested commands will still be useful however as then we can see what to expect in setups such as yours and hopefully advise the user accordingly to use the alternative method; once it exists within the Web-UI of course.
i have not gon further in this as i want to make sure this is worth investing my time discovered that raid 5/6 is not suggested and is the main thing im looking for getting a general consensus on another thread before i go further with the software
Yes it is a shame that the parity raid levels of 5 and 6 in btrfs are less mature. But did you know that btrfs raid 1 stores only 2 copies (currently) and so will only half your available space. It’s done on a block basis so if you have 3 or more drives it will still only store 2 copies but on 2 different physical devices. It also generally performs better than the parity raids.