I have recently got really invested into building a fully self hosted echo system and currently am using the Rockstor as my NAS storage. I built a somewhat of a beefy setup for this so I could also run a Plex media server with local access to the data and removing the element of Smb shares.
I am relatively new to working directly with a NAS. I would like to back up the entirety of my NAS, including data to another backup device, in the even I experience any failures that will result in the loss of data.
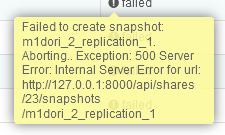
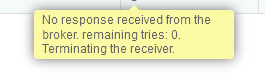
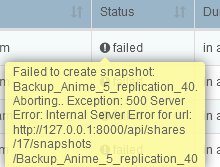
From my understanding after reading documentation on Rockstor replication, I believe this is what I am looking for.
I just had a few questions about this I was hoping for some assistance with.
-
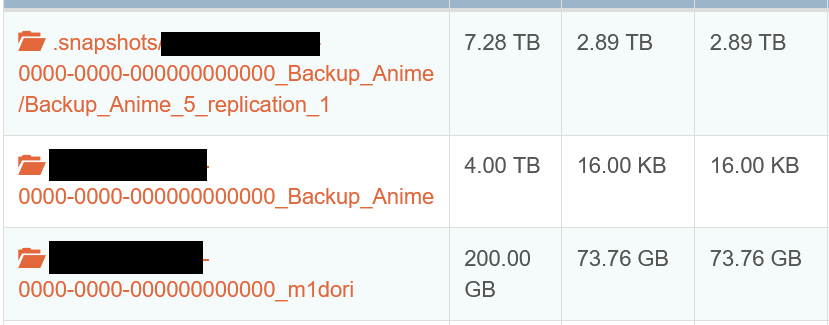
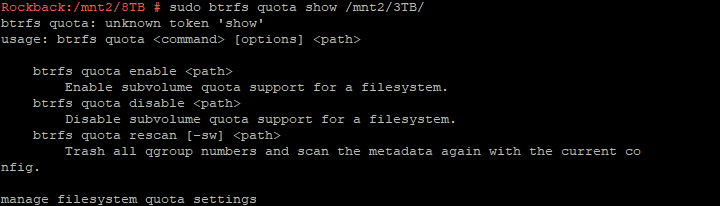
In order to backup data and shares on the second Rockstor instance with Replication, do I need to have the same hard drive sizes? My thought is that it is based on shares, so if i have an 8 TB share on the main NAS, I would need at least a HDD to support an 8 TB share on the instance being replicated.
-
Is this the best solution for having an entire backup of my NAS with the Data? I do not want to store data on anything that is not self hosted.
I plan to support this project once I finish making sure it will work for me the way I need it to.
I appreciate any feedback.