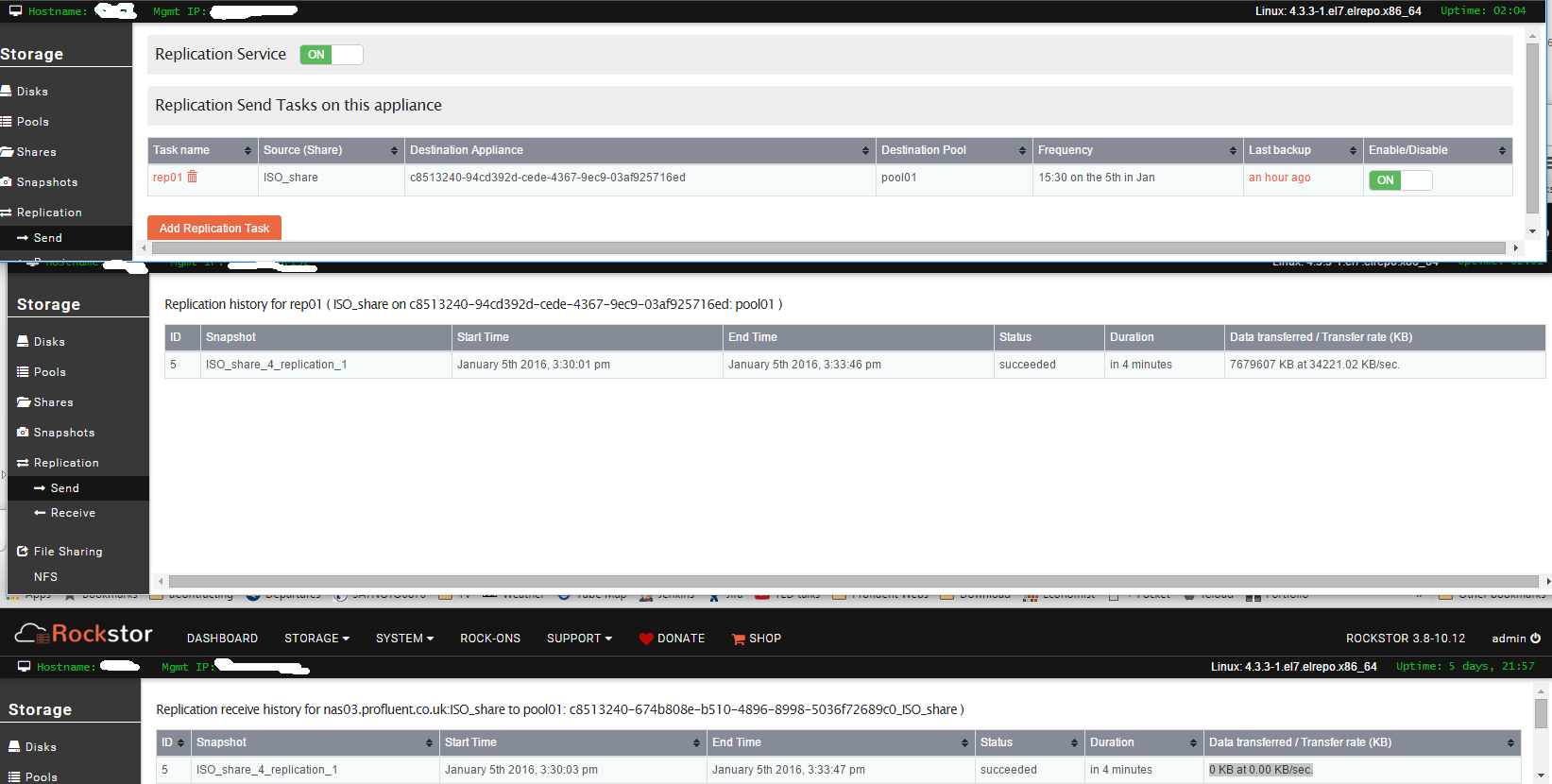
I’m struggling to replicate a share (containing 7.4Gb). No errors, just nothing is transferred. Top two windows in below screenshot show the source NAS, bottom is the destination. Notice although the source says Data Transferred: “7679607 KB at 34221.02 KB/sec” , the destination says “0 KB at 0.00 KB/sec”.
files in /opt/rockstor/var/log should have clues. Check both machines. I wonder if it’s a reporting error given there are not errors in the trail history on both sides.
The destination Share being empty is normal(Check Snapshots view, you should see new snapshots associated with replication), until a few diffs are sent over. On first rotation of snapshots on the destination, the oldest one becomes the Share. It’s a little counter intuitive at this point. But we hope to document the behavior clearly, soon.
Have you tried reproducing using another Share?
Either way, I am really interested in finding out if there’s a bug. Let’s narrow this down.
I’d like to delete all snapshots and start a fresh replication attempt. However I can’t delete the older copies as an “rm -rf /mnt2/pool01/.snapshots/c8513240-674b808e-b510-4896-8998-5036f72689c0_ISO_share/ISO_share_3_replication_1” results in: “Read-only file system”. Likewise in the GUI, I tick the only snapshot shown (from the latest replication), and press Delete, and OK to confirm. The delete button fades as if pressed, but nothing happens and if I refresh the screen, it’s still there. I’ve already deleted the replication task & (empty) share.
I initially tried replicating a much larger (5tb) share, and it failed, which is why I’m starting smaller. It seems there is a bug on the receiver as it shows “0 KB at 0.00 kb\sec” even when a destination snapshot is successfully created.
I encounter the same issue. I’m running 3.8-10.9. The following logs are from a 5GB share, where replication ends successfully, but the snapshot is not being mapped to the share folder on the receiver. Also the snapshot is not listed on the webinterface under Storage/Snapshots.
This is what I see in my logs.:
rockstor.log[sender]:
[07/Jan/2016 17:06:30] DEBUG [smart_manager.replication.sender:313] Id: a8cXXX-5 Sender alive. Data transferred: 5.56 GB. Rate: 29.91 MB/sec.
[07/Jan/2016 17:06:32] DEBUG [smart_manager.replication.sender:289] Id: a8cXXX-5. send process finished for a8cXXX_TEST_5_replication_1. rc: 0. stderr: At subvol /mnt2/DATA/.snapshots/TEST/TEST_5_replication_1
Thanks for sharing using information @grizzly and @gigolizer. I’d like to clarify a few things. Please read carefully.
@gigolizer, from your logs it’s clear that both sender and receiver exited with exitcode 0. Which means replication “functionally” succeeded. Do you see any error on the UI in the trail table either on sender of receiver side? I am guessing not.
If you don’t see any error on the UI, but if the UI shows 0KB transferred, it’s most likely a “reporting” error on the UI and not a “functional” error. Still a bug, but cosmetic. I don’t see it in my infra, but I am sure we’ll track it down and fix it soon.
The way replication works is, as you may know already, 1st transfer is a full transfer. However, after the first transfer, a mirror Share does not magically appear on the receiver with all the data. It’s a bit counter intuitive, but put that aside for now. Subsequent transfers are diffs and should happen pretty fast. Only after the 6th transfer, the Share on the receiver appears with data. That’s when the first full transfer is upgraded into a full Share. So my question to you both is, how many replication tasks have completed? Wait until 6 of them are completed.
@grizzly If you want to delete snapshots manually, don’t use rm -rf. Use btrfs subvol delete with the same argument.
The sad part of this is that the UX is bad enough to make us think there’s some functional bug. We will make it better and I thank you for the feedback. And there’s pending documentation