When I cd /opt/rockstor, poetry is not a binary I can run. On either machine.
Edit: I assume you are using BASH. When I switch to BASH from FISH it works.
Edit the second: The cron job is firing, but I’m not seeing any logs show up when it does.
Edit the third: It’s working! I’m embarrassed to say that I had the receiving server listening on the wrong interface.
Thank you for your help. You guys were so helpful, I’ve decided to subscribe.
Again thank you!
Edit the fourth: If I were to offer a critique of my replication experience, it would be the lack of clear and useful information.
The replication process is pretty opaque. To start, the emails from cron weren’t helpful—in fact, they were misleading. All I was receiving was:
rcommand=b'SUCCESS', reply=b'A new Sender started successfully for Replication Task(10).'
b'A new Sender started successfully for Replication Task(10).'
If I had relied solely on those emails, I wouldn’t have known that the replication jobs were actually failing.
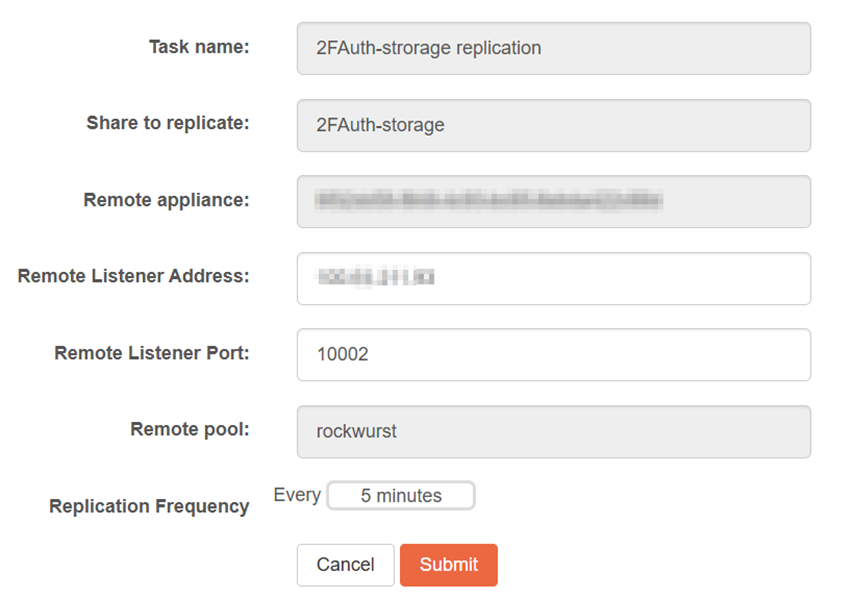
The replication interface showing the time elapsed since the last successful replication also isn’t very informative. As a sysadmin, I don’t care how long it’s been since a task ran—I care whether it succeeded. A simple “Success/Failed” status would be immediately more useful than elapsed time. If I want to know when the last successful backup was, I can always click the task and view the log.
And about those logs: the task logs shown in the UI could use improvement. Right now, they show successful runs—“happy-path” logging. They should also show failures with meaningful error messages like failed to connect to <receiver host> or snapshot already exists.
On top of that, the replication system itself doesn’t appear to generate system-level logs. While some underlying parts (like btrfs) might produce logs, the replication system doesn’t seem to emit its own. That makes it harder to trace problems or automate monitoring beyond what the UI shows.
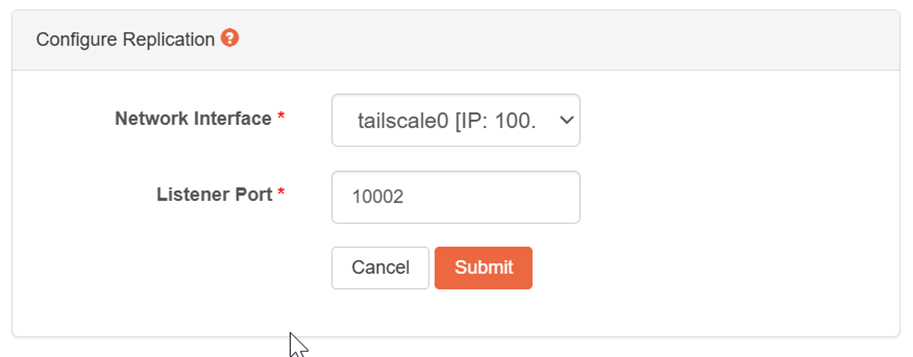
Finally, in my particular case, the root cause of the failure was a simple configuration issue: the wrong network interface was listening. If the replication UI displayed the interface in use, this would have been trivial to diagnose.
In conclusion:
- Replace ambiguous “time since last success” with a clear success/failure indicator.
- Improve task logs in the UI—show failures, not just successes, and include helpful error messages.
- Add system-level logging to the replication system.
- Show the listening network interface in the UI to simplify troubleshooting.
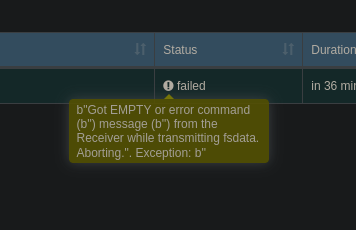
Edit the fifth: I jumped the gun on some of my criticism. I did trigger that exception again. And it did show up as “failed” in the replication UI.