Evening all, new to the rockstor community but come to this arena w/ deep storage background in ZFS and open storage systems. Tonight I was attempting to spin up a rockstor instance as I am evaluating a few new stg solutions such as ScaleIO/ESOS/Rockstor. Install went silky smooth but I was caught off guard by a vt-D LSI 2008 HBA NOT seeing any disks. Same config on a Illumos/ZoL/etc derivative is just fine and see’s all disks attached w/ identical HW/VM config. I can see the mptsas module/drivers I believe and I see the HBA in lspci but no love in rockstor web interface/lsblk/fdisk -l.
HBA is in IT mode w/ v19 LSI firmware on it. (same FW I use on all my open-stg boxes)
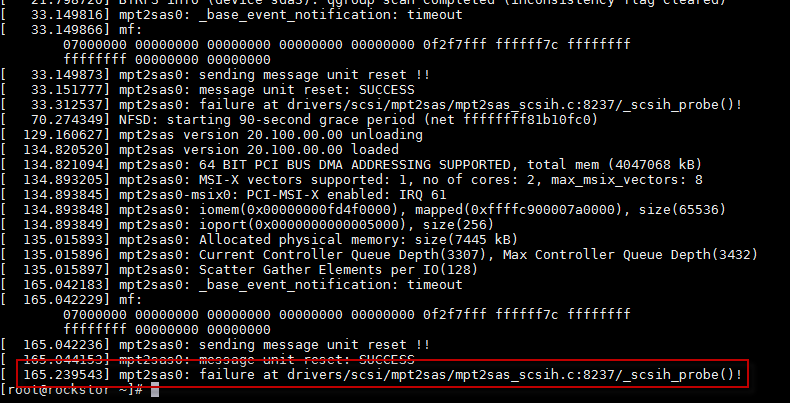
If I attempt to rmmod mpt2sas and modprobe mpt2sas I get this gnarly looking error:
UPDATE: I should confess that I added my vt-D HBA device post initial install, also did an immediate update from 3.8-7 to 3.8-8 which also did a kernel update…Gonna restart w/ vt-D passthru HBA attached from the get-go and NOT update just to sanity check things. Will report back shortly.
Well this is depressing, successful NFS mount to vSphere but when I try to use it APD (All Paths Down) errors…weak…super weak.
NFS on my OmniOS AIO setup still seems solid so I am hesitant to start monkeying w/ the vSphere side of the house.
SMB just copied a file to same location, feels like NFS permissions…yep a manual export entry of ‘/export/vmware *(rw,sync,no_root_squash)’ fixed me up.
Please advise if there is a better way to do this or if I am blind?
OK, pretty impressed so far, seems to be getting pretty good results from a raid1 mirror of two Intel DC s3700’s across 10G NFS. Jumbo frames didn’t seem to wanna play nice…even w/ jumbo turned up end-to-end. What gives?
Used Rockstor for about a month now under ESXi with 4 disks attached to a passthrough LSI. Today I wanted to remove one disk and replace it with another. Remove from the pool failed with some odd error (didn’t screenshot, duh…)
After reboot I got this mpt2sas failure. Tried a new 3.8.7 installation. Could see the disks and import. Pool and share present, but pool says 0% used and share 4.86 TB used (which was the amount before the problem).
ESXi can mount the NFS share but it’s empty. Any chance to get the data back? If not it’s not that serious. I would have lost only two pretty paeleolithic VMs.
I like to use Rockstor this way with ESXi but this is kinda setback. :-/
Update: maybe it’s kernel related. I’m pretty much a Linux dummy. Just rebooted my newly created Rockstor2 with the 3rd boot option (core 3 or something like that). It says
You are running an unsupported kernel(4.1.0-1.el7.elrepo.x86_64). Some features may not work properly. Please reboot and the system will automatically boot using the supported kernel(4.2.2-1.el7.elrepo.x86_64)
Now I could mount the old NFS share (although pool still says 0% usage) and migrate my VMs.
Probably I’ll stay a while with 3.8.7 after I cleaned up everything…
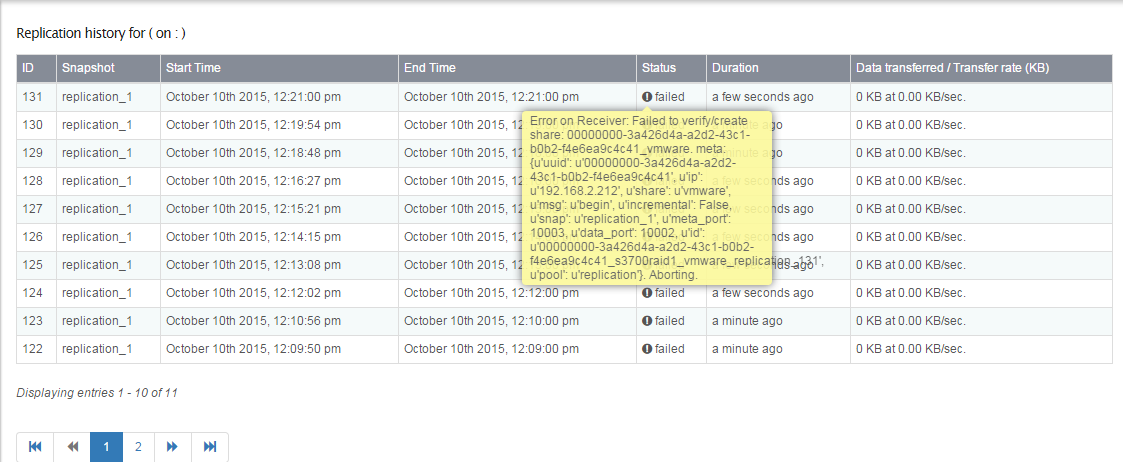
OK, so I am stumped w/ replication between two rockstor appliances. I paired/entered keys, enabled rep svc on each end, setup job and all I get is this.
@whitey Yes, not so good I’m afraid. There is a critical issue open for Appliance to Appliance replication but it may not be down to anything specifically Rockstor related. I know it’s on the cards for the next major milestone though. Anything you can find out / debug would be great though.
Wow, what a bummer, so this used to work but now is broke/some sort of regression introduced and now the rockstor/btrfs crew are ‘on the hunt to put it to bed’ essentially? Very disappointing and concerning to think that a feature I live and die by on my ZFS AIO’s is not working currently even cli (well i guess you have not confirmed that yet but that is how I do it on a zfs based system unless I am using a napp-it interface from Gea). Anyways will keep an eye out but am a bit leary now to hear this.
@whitey and @phillxnet, it’s fair to say that there is a regression in Rockstor code for sure. I wouldn’t be so fast and speculative about the upstream BTRFS code though. At least not until I test the behavior myself in our current(4.2.1) kernel.
As @phillxnet said in his comment, fixing replication is very important and is slated in the current milestone. So please stay tuned and we’ll update this forum thread and the github issue as we get to work.