Hi,
I’m facing a strange and difficult to diagnose issue currently. Let me explain my setup first.
We have in our small office been using Rockstor v3.9 for nearly a year now. We have a ~14TB RAID 10 array that is used by multiple server (4) machines to download documents from the web (mostly PDFs and XMLs) and store them them in 1 place. The files are made available via a Samba share and this is mounted via a CIFS mount on each of the Ubuntu server machines. We had no problems with this setup for the past year. However, with our usage reaching nearly 90%, we chose to expand the capacity of the array by adding 2 additional disks and at the same time also upgrade to the newly released Rockstor v4.1.0-0.
There were a couple of minor issues during the import related to file/share permissions etc that I was able to resolve. During the rebalance when the new disks were added, btrfs started complaining about read and write errors on 1 of the disks so I used btrfs replace to replace that disk using the instructions here. I ran a balance after this for good measure to ensure that my array was fully redundant again.
However, once we started our download servers, Rockstor seemed to work fine for a while until all of a sudden it froze with the WebUI becoming unresponsive and my SSH connection also getting disconnected. I restarted it manually and it kept happening again and again. I have looked at the rockstor, smbd and nmbd logs to try and see if I could figure out what the problem is but tbh, I’m not familiar enough with either btrfs, Rockstor or Samba to work out what the problem is. On top of that, the fact that the server runs just fine and then hangs all of a sudden makes diagnosis all the more difficult since I cannot get into the machine anymore and have to manually power cycle it.
I’m currently running a scrub to see if any file system corruption surfaces but I’d be happy to share the logs or any other details if they help. I’m at my wit’s end with this and any help would be greatly appreciated.
UPDATE: I see the following messages showing up in dmesg
[6135.085241] perf: interrupt took too long (2522 > 2500), lowering kernel.perf_event_max_sample_rate to 79250
[ 6872.237948] perf: interrupt took too long (3169 > 3152), lowering kernel.perf_event_max_sample_rate to 63000
[ 8313.936003] perf: interrupt took too long (3975 > 3961), lowering kernel.perf_event_max_sample_rate to 50250
[10969.505087] perf: interrupt took too long (4971 > 4968), lowering kernel.perf_event_max_sample_rate to 40000
I suspect this is because there is a scrub running but just wanted to update here nonetheless.
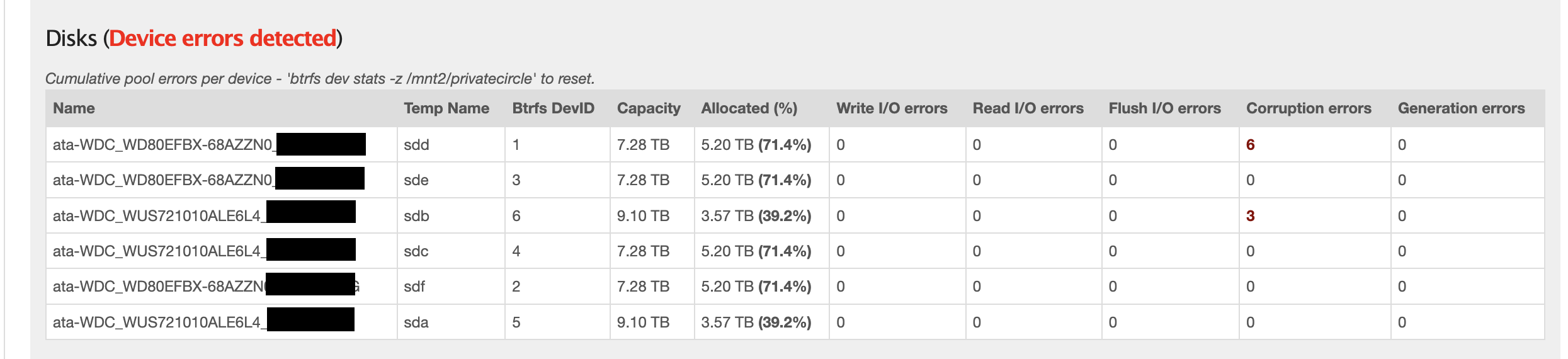
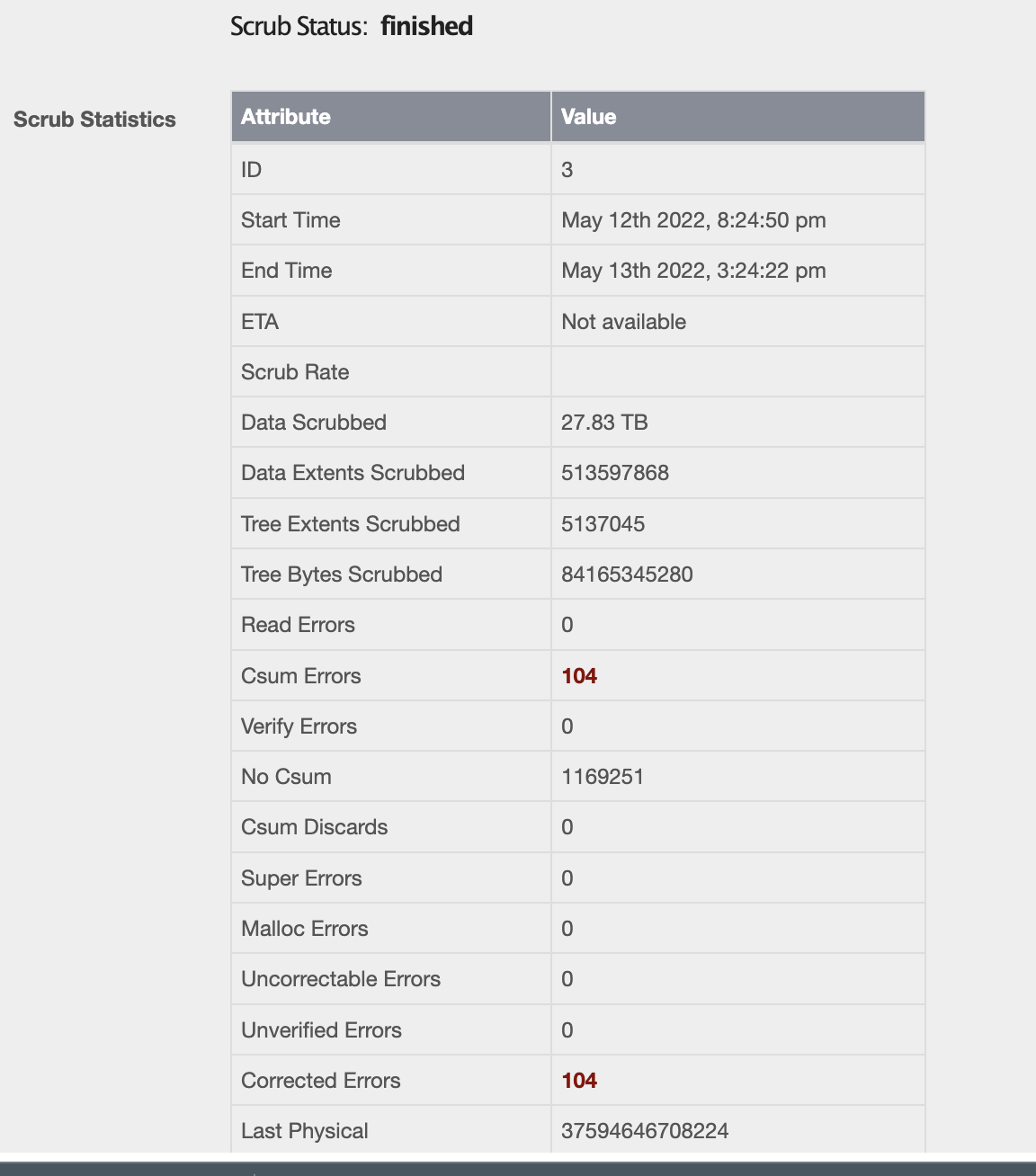
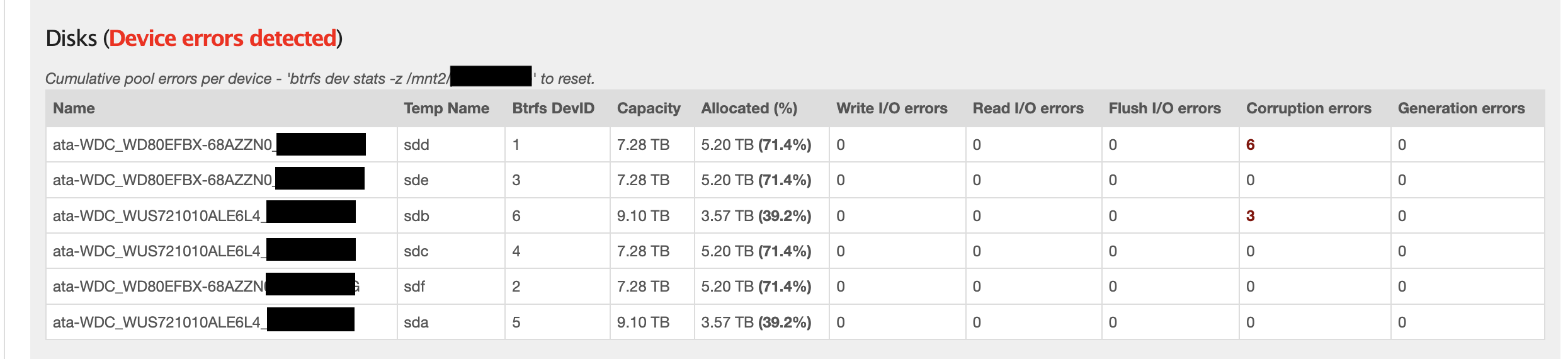
 . I still haven’t pinpointed which component exactly was the source of the problem but my interest is more in getting our applications up and running once again.
. I still haven’t pinpointed which component exactly was the source of the problem but my interest is more in getting our applications up and running once again. ) but the disk replacement was.
) but the disk replacement was.