Note the top errors are pretty old and likely unrelated but I included them “just in case” the failed to get status errors (note the dates) are the relevant ones.
[25/Jul/2017 16:09:28] ERROR [storageadmin.middleware:32] Exception occured while processing a request. Path: /api/commands/refresh-snapshot-state method: POST
[25/Jul/2017 16:09:28] ERROR [storageadmin.middleware:33] Error running a command. cmd = /sbin/btrfs property get /mnt2/data/rockon-root/btrfs/subvolumes/e036e54af38ee90556073ed98d90ec8bf1514d919c733f4ac7a455c17e0e1a7a. rc = 1. stdout = ['']. stderr = ['ERROR: failed to open /mnt2/data/rockon-root/btrfs/subvolumes/e036e54af38ee90556073ed98d90ec8bf1514d919c733f4ac7a455c17e0e1a7a: No such file or directory', 'ERROR: failed to detect object type: No such file or directory', 'usage: btrfs property get [-t <type>] <object> [<name>]', '', ' Gets a property from a btrfs object.', '', ' If no name is specified, all properties for the given object are', ' printed.', ' A filesystem object can be a the filesystem itself, a subvolume,', " an inode or a device. The '-t <type>' option can be used to explicitly", ' specify what type of object you meant. This is only needed when a', ' property could be set for more then one object type. Possible types', ' are s[ubvol], f[ilesystem], i[node] and d[evice].', '', '']
Traceback (most recent call last):
File "/opt/rockstor/eggs/Django-1.8.16-py2.7.egg/django/core/handlers/base.py", line 132, in get_response
response = wrapped_callback(request, *callback_args, **callback_kwargs)
File "/opt/rockstor/eggs/Django-1.8.16-py2.7.egg/django/views/decorators/csrf.py", line 58, in wrapped_view
return view_func(*args, **kwargs)
File "/opt/rockstor/eggs/Django-1.8.16-py2.7.egg/django/views/generic/base.py", line 71, in view
return self.dispatch(request, *args, **kwargs)
File "/opt/rockstor/eggs/djangorestframework-3.1.1-py2.7.egg/rest_framework/views.py", line 452, in dispatch
response = self.handle_exception(exc)
File "/opt/rockstor/eggs/djangorestframework-3.1.1-py2.7.egg/rest_framework/views.py", line 449, in dispatch
response = handler(request, *args, **kwargs)
File "/opt/rockstor/eggs/Django-1.8.16-py2.7.egg/django/utils/decorators.py", line 145, in inner
return func(*args, **kwargs)
File "/opt/rockstor/src/rockstor/storageadmin/views/command.py", line 323, in post
import_snapshots(share)
File "/opt/rockstor/src/rockstor/storageadmin/views/share_helpers.py", line 139, in import_snapshots
share.name)
File "/opt/rockstor/src/rockstor/fs/btrfs.py", line 507, in snaps_info
snap_name, writable = parse_snap_details(mnt_pt, fields)
File "/opt/rockstor/src/rockstor/fs/btrfs.py", line 469, in parse_snap_details
'%s/%s' % (mnt_pt, fields[-1])])
File "/opt/rockstor/src/rockstor/system/osi.py", line 115, in run_command
raise CommandException(cmd, out, err, rc)
CommandException: Error running a command. cmd = /sbin/btrfs property get /mnt2/data/rockon-root/btrfs/subvolumes/e036e54af38ee90556073ed98d90ec8bf1514d919c733f4ac7a455c17e0e1a7a. rc = 1. stdout = ['']. stderr = ['ERROR: failed to open /mnt2/data/rockon-root/btrfs/subvolumes/e036e54af38ee90556073ed98d90ec8bf1514d919c733f4ac7a455c17e0e1a7a: No such file or directory', 'ERROR: failed to detect object type: No such file or directory', 'usage: btrfs property get [-t <type>] <object> [<name>]', '', ' Gets a property from a btrfs object.', '', ' If no name is specified, all properties for the given object are', ' printed.', ' A filesystem object can be a the filesystem itself, a subvolume,', " an inode or a device. The '-t <type>' option can be used to explicitly", ' specify what type of object you meant. This is only needed when a', ' property could be set for more then one object type. Possible types', ' are s[ubvol], f[ilesystem], i[node] and d[evice].', '', '']
[26/Jul/2017 07:00:02] ERROR [scripts.scheduled_tasks.pool_scrub:76] Failed to start scrub at pools/data/scrub
[26/Jul/2017 07:00:02] ERROR [scripts.scheduled_tasks.pool_scrub:37] Failed to get scrub status at pools/data/scrub/status
[31/Jul/2017 07:00:02] ERROR [scripts.scheduled_tasks.pool_scrub:76] Failed to start scrub at pools/bigdata/scrub
[31/Jul/2017 07:00:02] ERROR [scripts.scheduled_tasks.pool_scrub:37] Failed to get scrub status at pools/bigdata/scrub/status
[02/Aug/2017 07:00:03] ERROR [scripts.scheduled_tasks.pool_scrub:76] Failed to start scrub at pools/data/scrub
[02/Aug/2017 07:00:03] ERROR [scripts.scheduled_tasks.pool_scrub:37] Failed to get scrub status at pools/data/scrub/status
[07/Aug/2017 07:00:03] ERROR [scripts.scheduled_tasks.pool_scrub:76] Failed to start scrub at pools/bigdata/scrub
[07/Aug/2017 07:00:03] ERROR [scripts.scheduled_tasks.pool_scrub:37] Failed to get scrub status at pools/bigdata/scrub/status
[09/Aug/2017 07:00:02] ERROR [scripts.scheduled_tasks.pool_scrub:76] Failed to start scrub at pools/data/scrub
[09/Aug/2017 07:00:02] ERROR [scripts.scheduled_tasks.pool_scrub:37] Failed to get scrub status at pools/data/scrub/status
[14/Aug/2017 07:00:03] ERROR [scripts.scheduled_tasks.pool_scrub:76] Failed to start scrub at pools/bigdata/scrub
[14/Aug/2017 07:00:03] ERROR [scripts.scheduled_tasks.pool_scrub:37] Failed to get scrub status at pools/bigdata/scrub/status
[16/Aug/2017 07:00:02] ERROR [scripts.scheduled_tasks.pool_scrub:76] Failed to start scrub at pools/data/scrub
[16/Aug/2017 07:00:02] ERROR [scripts.scheduled_tasks.pool_scrub:37] Failed to get scrub status at pools/data/scrub/status
[20/Aug/2017 18:30:04] ERROR [scripts.scheduled_tasks.pool_scrub:76] Failed to start scrub at pools/bigdata/scrub
[20/Aug/2017 18:30:04] ERROR [scripts.scheduled_tasks.pool_scrub:37] Failed to get scrub status at pools/bigdata/scrub/status
[20/Aug/2017 19:33:52] ERROR [scripts.scheduled_tasks.pool_scrub:76] Failed to start scrub at pools/bigdata/scrub
[20/Aug/2017 19:33:52] ERROR [scripts.scheduled_tasks.pool_scrub:37] Failed to get scrub status at pools/bigdata/scrub/status
[20/Aug/2017 19:34:44] ERROR [scripts.scheduled_tasks.pool_scrub:76] Failed to start scrub at pools/bigdata/scrub
[20/Aug/2017 19:34:44] ERROR [scripts.scheduled_tasks.pool_scrub:37] Failed to get scrub status at pools/bigdata/scrub/status
[20/Aug/2017 19:35:41] ERROR [scripts.scheduled_tasks.pool_scrub:76] Failed to start scrub at pools/bigdata/scrub
[20/Aug/2017 19:35:41] ERROR [scripts.scheduled_tasks.pool_scrub:37] Failed to get scrub status at pools/bigdata/scrub/status
[21/Aug/2017 07:30:03] ERROR [scripts.scheduled_tasks.pool_scrub:76] Failed to start scrub at pools/bigdata/scrub
[21/Aug/2017 07:30:03] ERROR [scripts.scheduled_tasks.pool_scrub:37] Failed to get scrub status at pools/bigdata/scrub/status
[21/Aug/2017 09:55:57] ERROR [scripts.scheduled_tasks.pool_scrub:76] Failed to start scrub at pools/bigdata/scrub
[21/Aug/2017 09:55:57] ERROR [scripts.scheduled_tasks.pool_scrub:37] Failed to get scrub status at pools/bigdata/scrub/status
[21/Aug/2017 09:55:57] DEBUG [scripts.scheduled_tasks.pool_scrub:87] task(5) finished with state(error).
[21/Aug/2017 10:02:02] ERROR [scripts.scheduled_tasks.pool_scrub:76] Failed to start scrub at pools/bigdata/scrub
[21/Aug/2017 10:02:02] ERROR [scripts.scheduled_tasks.pool_scrub:37] Failed to get scrub status at pools/bigdata/scrub/status
[21/Aug/2017 10:02:02] DEBUG [scripts.scheduled_tasks.pool_scrub:87] task(5) finished with state(error).
root mail
From rocky@gamull.com Mon Aug 21 10:02:02 2017
Return-Path: <rocky@gamull.com>
X-Original-To: root
Delivered-To: root@rocky.gamull.com
Received: by rocky.gamull.com (Postfix, from userid 0)
id DD5332858A8; Mon, 21 Aug 2017 10:02:02 -0400 (EDT)
From: "(Cron Daemon)" <rocky@gamull.com>
To: root@rocky.gamull.com
Subject: Cron <root@rocky> /opt/rockstor//bin/st-pool-scrub 5 \*-*-*-*-*-*
Content-Type: text/plain; charset=UTF-8
Auto-Submitted: auto-generated
Precedence: bulk
X-Cron-Env: <XDG_SESSION_ID=8>
X-Cron-Env: <XDG_RUNTIME_DIR=/run/user/0>
X-Cron-Env: <LANG=en_US.UTF-8>
X-Cron-Env: <SHELL=/bin/bash>
X-Cron-Env: <PATH=/sbin:/bin:/usr/sbin:/usr/bin>
X-Cron-Env: <MAILTO=root>
X-Cron-Env: <MAILFROM=rocky@gamull.com>
X-Cron-Env: <HOME=/root>
X-Cron-Env: <LOGNAME=root>
X-Cron-Env: <USER=root>
Message-Id: <20170821140202.DD5332858A8@rocky.gamull.com>
Date: Mon, 21 Aug 2017 10:02:02 -0400 (EDT)
Traceback (most recent call last):
File "/usr/lib64/python2.7/logging/handlers.py", line 76, in emit
if self.shouldRollover(record):
File "/usr/lib64/python2.7/logging/handlers.py", line 154, in shouldRollover
msg = "%s\n" % self.format(record)
File "/usr/lib64/python2.7/logging/__init__.py", line 724, in format
return fmt.format(record)
File "/usr/lib64/python2.7/logging/__init__.py", line 464, in format
record.message = record.getMessage()
File "/usr/lib64/python2.7/logging/__init__.py", line 324, in getMessage
msg = str(self.msg)
TypeError: __str__ returned non-string (type list)
Logged from file pool_scrub.py, line 78
Traceback (most recent call last):
File "/usr/lib64/python2.7/logging/handlers.py", line 76, in emit
if self.shouldRollover(record):
File "/usr/lib64/python2.7/logging/handlers.py", line 154, in shouldRollover
msg = "%s\n" % self.format(record)
File "/usr/lib64/python2.7/logging/__init__.py", line 724, in format
return fmt.format(record)
File "/usr/lib64/python2.7/logging/__init__.py", line 464, in format
record.message = record.getMessage()
File "/usr/lib64/python2.7/logging/__init__.py", line 324, in getMessage
msg = str(self.msg)
TypeError: __str__ returned non-string (type list)
Logged from file pool_scrub.py, line 39
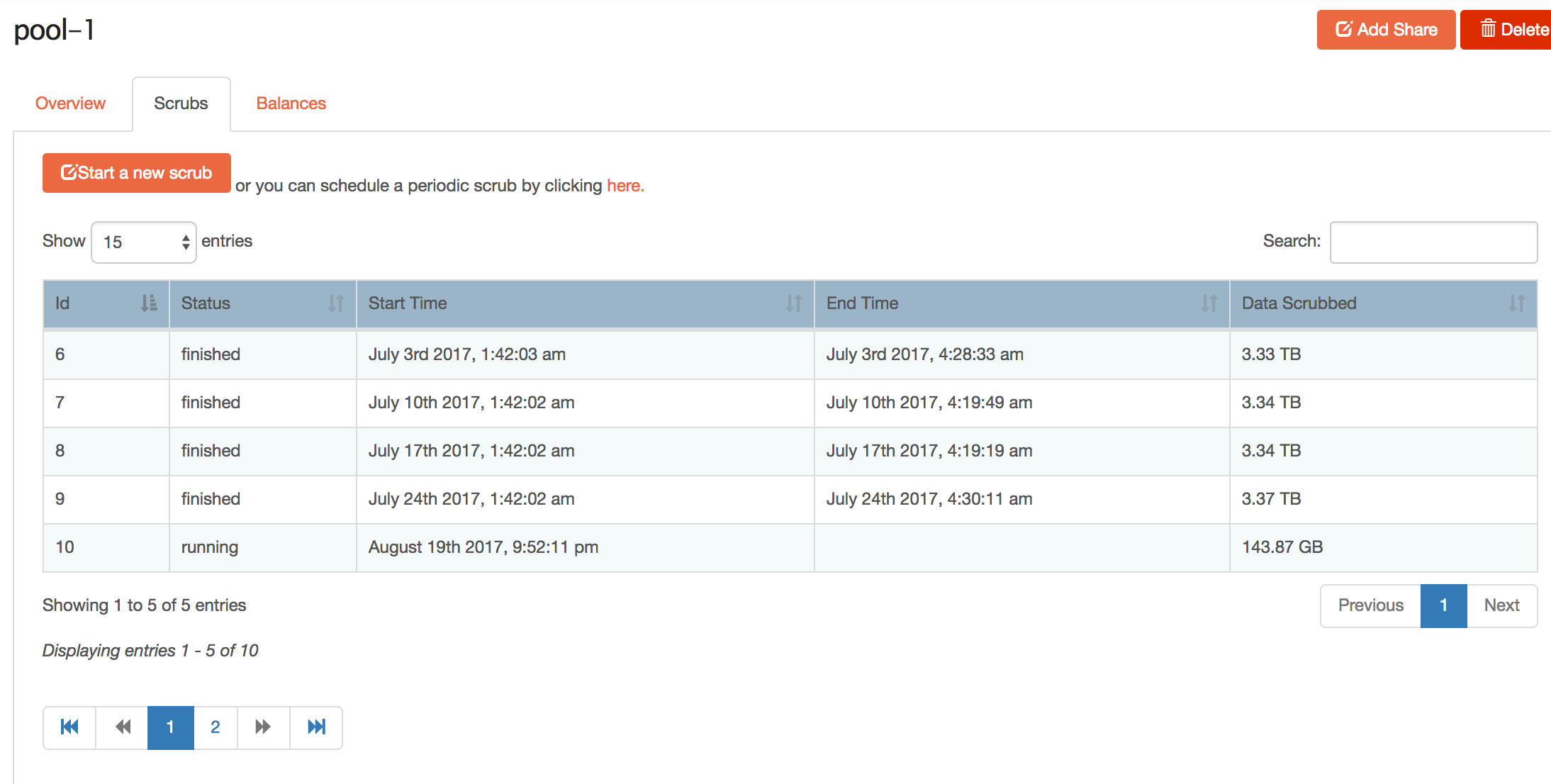
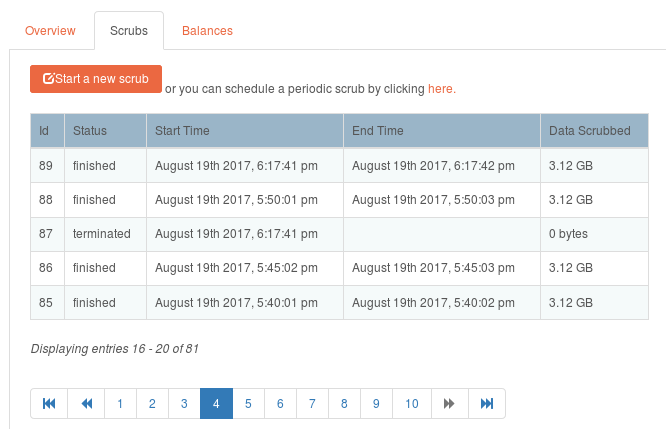
 let me know if you want me to contribute if that’s the path.
let me know if you want me to contribute if that’s the path.