@William212 Hello again. It might be as well to establish what the actual status of the balance is. This can be done with the following command run as root:
btrfs balance status /mnt2/4TBNAS
if that is the correct mount point for your pool.
Also what raid level is the pool in question? If it’s a large raid5 or raid6 then it can take this long; known issue with these ‘not production ready’ parity raid levels, especially if there are many snapshots.
Not sure if 4TB in the name is still relevant here.
Also we do have some pending improvements in this area by way of the following pull request:
@William212 Sorry, fighting for time here. Did you execute the requested command as the root user and ensure that the pool name used was the correct one?
Pool name info can be had from the following command as root:
btrfs fi show
and the expected outcome is something along the lines of:
btrfs balance status /mnt2/rock-pool
No balance found on '/mnt2/rock-pool'
if so I tried that with various passwords and couldn’t log on so I created another user via the GUI and assigned that user to the ‘root’ group (hoping that would give that ID root access).
After logging into the new ID assigned to the root group and executing “btrfs fi show” I received
ERROR: cannot open /dev/sda3: Permission denied
for each HD.
Or is there another login ID for root or should I reset the ‘root’ password following the steps I have found elsewhere?
Thank you so much for your help!! Much appreciated!
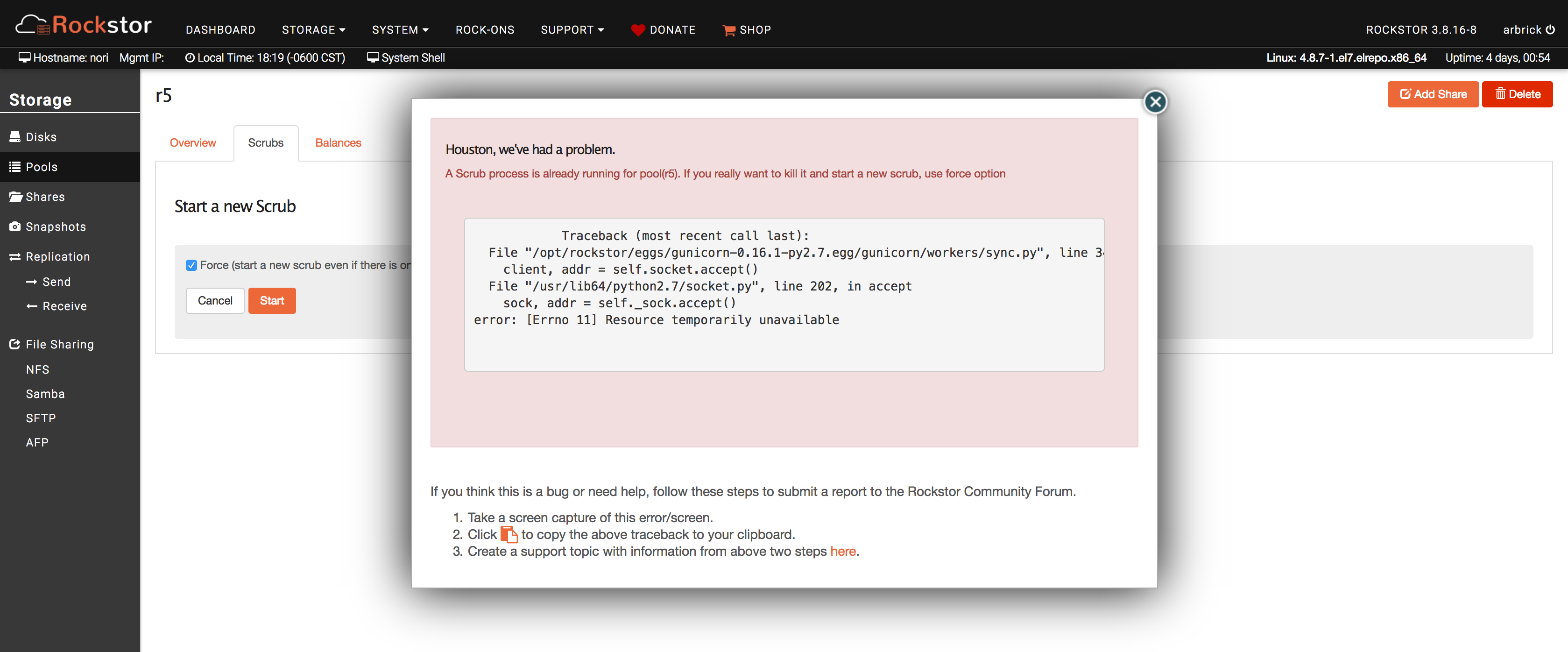
I am currently seeing a similar issue. My box experienced an unexpected shutdown during the execution of a scrub.
I am running the most current version of rockstor (3.8.16-8), but I believe the problem originated when I was running an older version. I provided below the information that was requested from @William212. The problem has persisted across restarts and upgrades. New scrubs cannot be scheduled (see screenshot below).
Traceback (most recent call last):
File "/opt/rockstor/eggs/gunicorn-0.16.1-py2.7.egg/gunicorn/workers/sync.py", line 34, in run
client, addr = self.socket.accept()
File "/usr/lib64/python2.7/socket.py", line 202, in accept
sock, addr = self._sock.accept()
error: [Errno 11] Resource temporarily unavailable
[root@nori ~]# btrfs fi show
Label: 'rockstor_rockstor' uuid: 8c05e66d-f6ec-4421-b7ab-515b7c25726b
Total devices 1 FS bytes used 1.75GiB
devid 1 size 107.68GiB used 8.02GiB path /dev/sda3
Label: 'r5' uuid: faf152cc-5d4a-48f5-895d-e68c5c7bf707
Total devices 3 FS bytes used 2.21TiB
devid 1 size 2.73TiB used 1.12TiB path /dev/sdb
devid 2 size 2.73TiB used 1.12TiB path /dev/sdd
devid 3 size 2.73TiB used 1.12TiB path /dev/sdc
[root@nori ~]# btrfs balance status /mnt2/r5
No balance found on '/mnt2/r5'