Once upon a time I started a scrub and it finished good. Strange thing is, that there are two entries in scrub history for the same scrub, whereas the first of the two entries did not finish (there is NO scrub running for any pool ATM!).
When trying to start a new scrub from GUI it throws the following error:
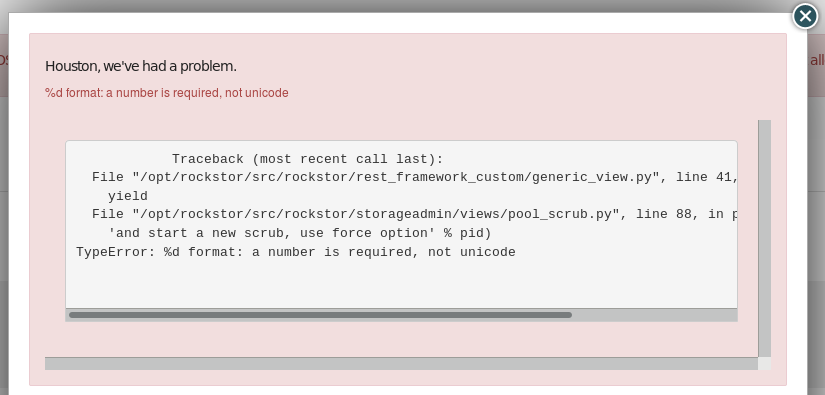
Traceback (most recent call last):
File “/opt/rockstor/src/rockstor/rest_framework_custom/generic_view.py”, line 41, in _handle_exception
yield
File “/opt/rockstor/src/rockstor/storageadmin/views/pool_scrub.py”, line 88, in post
‘and start a new scrub, use force option’ % pid)
TypeError: %d format: a number is required, not unicode
@Christian_Rost Hello again.
Thanks for reporting your findings. A complication in this case is that Rockstor’s reporting of the problem state has a very recent bug in it, the %d should be changed to %s:
An issue has been opened for this message formatting bug:
and a pull request to address it is awaiting review:
If you fancy trialing the ‘fix’ at least for the message formatting part of this then you simply need to change:
%d
to
%s
in the above highlighted line. Then a reboot, or Rockstor service restart, should yield the full message.
No worries if you are not game to edit that file on your installation (it’s a risky thing and not advised unless you are game and happy for this system to become unusable as a consequence(unlikely) and are also happy editing on the command line). We have nano pre-installed if you are game though.
The installed version of this file is in:
/opt/rockstor/src/rockstor/storageadmin/views/pool_scrub.py
To your point: the message should read:
A Scrub process is already running for pool (a-number-here). If you really want
to kill it and start a new scrub, use force option
So you could try ticking the force option that is presented just prior to starting the scrub.
As a curiosity you could also check the state of play scrub wise via the command line:
btrfs scrub status /mnt2/pool-name
Hope that helps and don’t worry about doing that edit unless you are game as all it will do is fix the message formatting bug; but you may be interested in dabbling and the info is presented in that light.
I were not precise enough. The error occurs even when running with ‘force’ flag.
A scrub is running for some time now by command line. My question in terms how to start a scrub was meant by using the GUI.
I’ll give editing the source a shot without starting a vim over nano discussion Might take some time since I’ll be AFK for a few hours, but I’ll feed back.
Sorry, but editing the source file just like you mentioned just comes up with another error:
Traceback (most recent call last):
File “/opt/rockstor/eggs/gunicorn-0.16.1-py2.7.egg/gunicorn/workers/sync.py”, line 34, in run
client, addr = self.socket.accept()
File “/usr/lib64/python2.7/socket.py”, line 202, in accept
sock, addr = self._sock.accept()
error: [Errno 11] Resource temporarily unavailable
This error shows, no matter if I check force option or not.
My manually started scrub finished successfully after about 4.5h and there is nothing running ATM. So there should definitely be no reason for scrub to not start even without force option.
I do still think of the history table as being the matter, since I guess that this is being looked up rather than issuing a syscall. (See my posted screenshot)
@Christian_Rost Thanks for the feedback and as mentioned your circumstance had the complication of the error reporting formatting bug.
ie (from the pull request quoted) before the formatting change:
and I needed to get that out of the way first as it would affect anyone attempting to start a scrub while an existing one was running. Also it was standing in the way of the real exception message.
Now that you have the formatting issue out of the way we should be able to see the actual exception error rather than the formatting one. As you see the Traceback for yours and for the instance of a running scrub are identical; what is the message you receive directly under “Houston, we’ve had a problem.” (in red text).
Also what is the exact output of:
btrfs scrub status /mnt2/pool-name
as requested before, as this is also used (as well as the table) by Rockstor code to assess current status.
Agreed but the ‘force’ option is intended to apply in such cases so we just need to narrow down a little more what’s not working as intended and why, at least in your case.
It would be great to get to the bottom of this one so your assistance is appreciated, I’m just not sure just yet exactly where the problem is, once it’s more closely identified and we have a reproducer then an issue, and consequent fix, should follow.
After getting the above command output (for this thread), does the problem persist after a reboot?
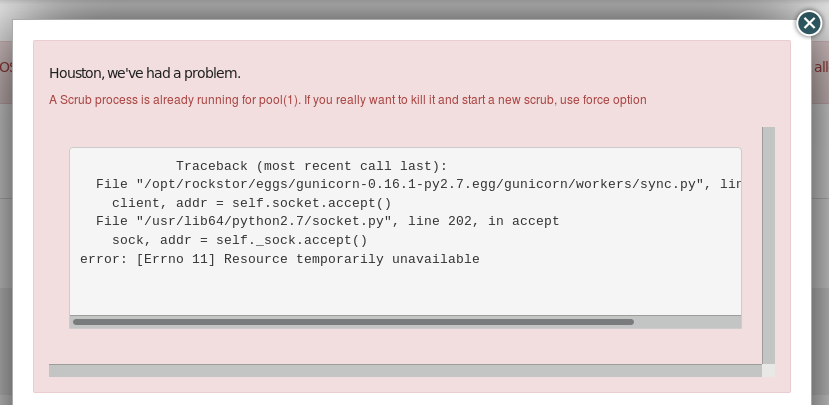
The error message shows (with ‘Force’ Option checked and after reboot):
Houston, we’ve had a problem.
A Scrub process is already running for pool(3). If you really want to kill it and start a new scrub, use force option
Traceback (most recent call last):
File “/opt/rockstor/eggs/gunicorn-0.16.1-py2.7.egg/gunicorn/workers/sync.py”, line 34, in run
client, addr = self.socket.accept()
File “/usr/lib64/python2.7/socket.py”, line 202, in accept
sock, addr = self._sock.accept()
error: [Errno 11] Resource temporarily unavailable
Here is some system output that might be of relevance:
btrfs scrub status /mnt2/DATA/
scrub status for 2e798215-006d-4c8f-b85f-bcf0ae6c41ca
scrub started at Sat Jul 29 14:29:44 2017 and finished after 04:35:19
total bytes scrubbed: 8.87TiB with 0 errors
date
So 30. Jul 13:36:10 CEST 2017
(Just to point out, that the manually started scrub finished ‘long’ time ago.)
Thanks for the outputs. Just to let you know that I have now opened an issue and made some progress on at least one cause of this bug. I hope to track down the other (the ‘force’ option lacking the essence of it’s name) as part of the same issue but may have to break that out into another:
and both these issues now have associated pull requests so upon the review process going as hoped these fixes should be in place in the testing channel updates soon.

 Might take some time since I’ll be AFK for a few hours, but I’ll feed back.
Might take some time since I’ll be AFK for a few hours, but I’ll feed back.