as I was calling smart.available(), I set up some logging which I piped to a file.
When I first restarted rockstor services, it logged SMART info for two HDD disks, but not for the NVMe SSD disk. I waited a bit and then killed the service.
I’ve tried again. This time I set up tail -f log in another tty session.
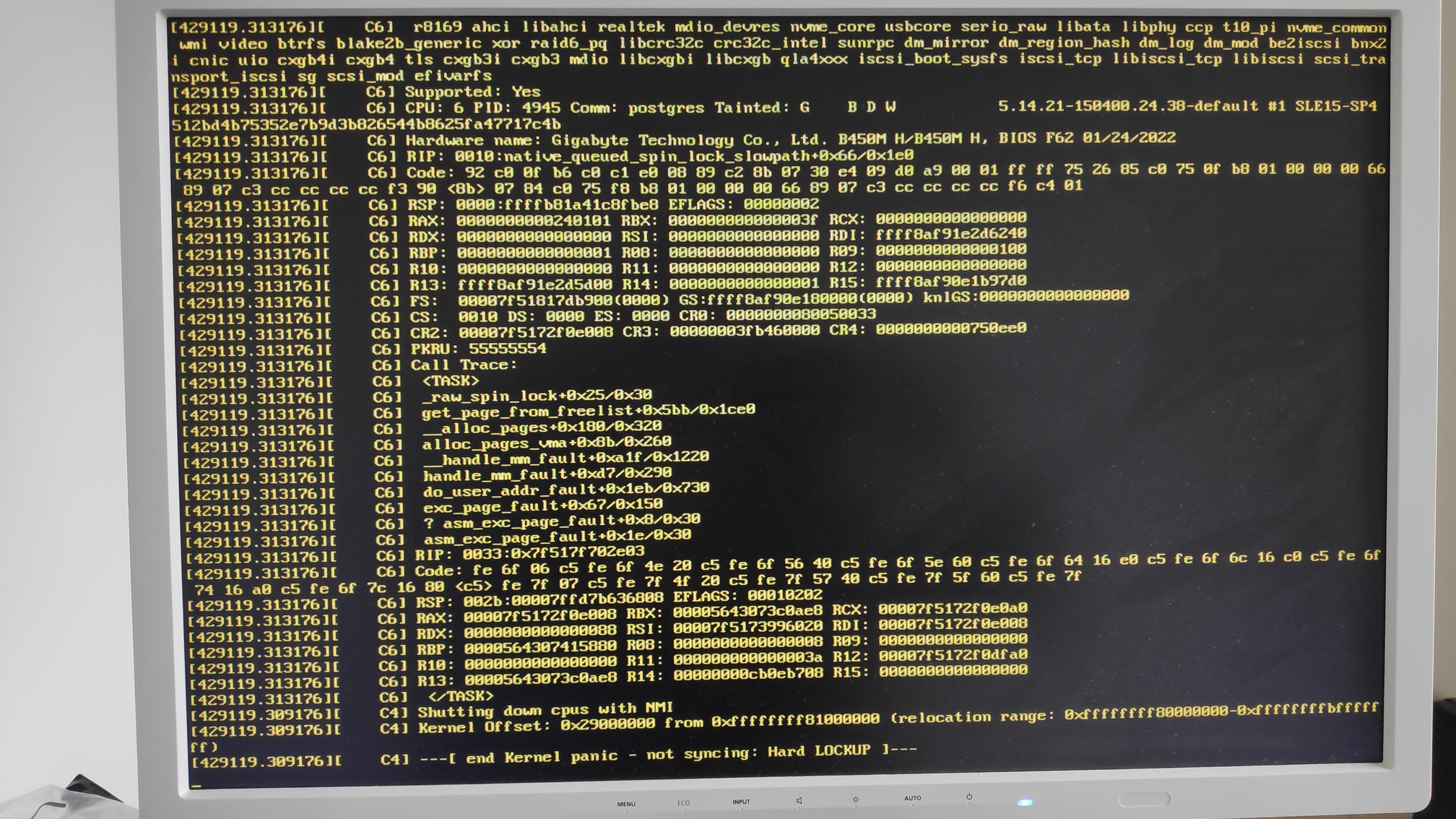
When trying to kill tail with CTRL-C, my kernel panicked. It didnt respond to keyboard as well.
I have taken a picture of the last few lines of the kernel panic before forcefully rebooting.
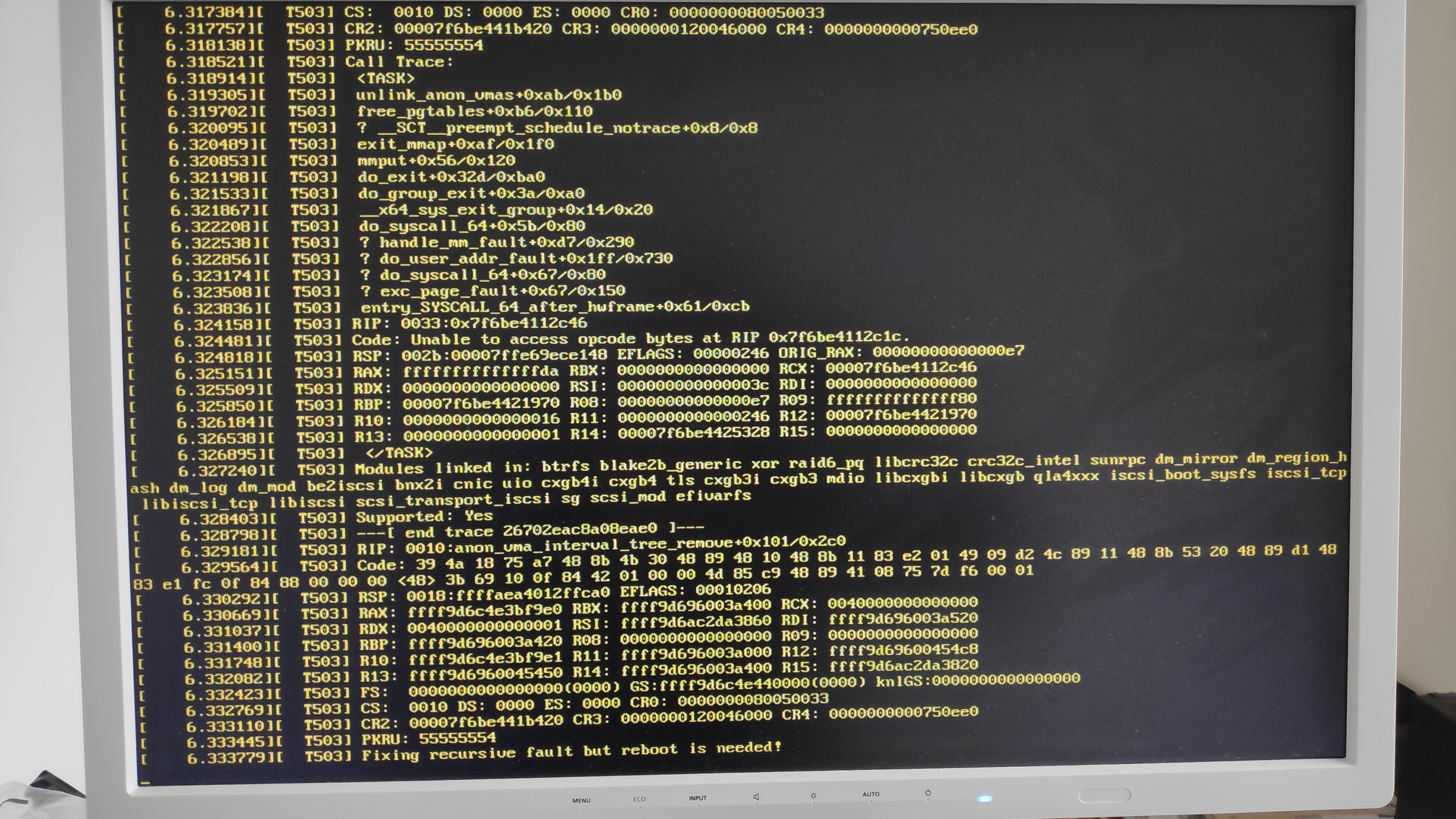
Kernel panicked again, this time at boot time and I took a picture as well. This time it seemed like a soft lockup, because the keys worked. The last line said something about “Fixing recursive fault but reboot is needed!”
So I rebooted again.
This time Rockstor is up and running.
My question is: where can I find the kernel panic logs? /var/log/dmesg only holds the log of the latest, successful boot. There are no rotated dmesg files here. /var/crash is empty.
Question #2 is finding out what happened.
Can you help? Should I talk to openSUSE folks?
This is a brand new PC. I have run some tests on RAM and disks before installing Rockstor, and no problems were found.
Thanks!
EDIT: I’m getting constant CPU stalling kernel-panic-like messages, mentions about postgres, gunicorn, so I am shutting the PC down now, because I need to go.
I wanna try booting without starting the rockstor services (which may cause this behaviour?). Is that possible?
@aremiaskfa Let us know your investigations on this front.
Re:
Just disable the rockstor-bootstrap.service and you should be good. It in turn depends, and so starts, rockstor.service, which in turn depends, and so starts rockstor-pre.service. This part of our developer docs is still mostly up-to-date bar the new location which you are already familiar with.
On the hardware front it’s always good to check memory (memtest86+) for 24-48 hours, be sure to use a modern memtest86+ thought, see our:
Pre-Install Best Practice (PBP): Pre-Install Best Practice (PBP) — Rockstor documentation Memtest86+ Cautionary Note
doc entry.
Another thing to check is the PSU, these are not always up-to-spec, and some folks add more and more drives to a PSU that just can’t handle it. Especially on drive start-up. Some also have very poor quality (ripply) voltage.
We use generic Postgres and Nginx, but we also depend on a tone of other things.
I’ve little experience myself in diagnosing kernel issues having very rarely seen them, bar in the early days when I found compiling a kernel always failed on the floppy drive controller. Turned out to be failing/flaky CPU cache. Fancy that. I’d used this same machine for a long time with minor stability issues. Linux is excellently stable these days so you should have enough tools to diagnose what is happening here, thought the associated knowledge required is rather deep. But our own services no nothing special at any low level and are basically python through-out bar the interactions with Nginx and Postgresql. But we do need memory to do all this.
Let us know how it goes, and as far as getting the rockstor services out of the way, we are entirely systemd initiated. Stop or disable our services (this all begin with rockstor*) and we don’t exist on the system; and you have what is a essentially a partial development extended (to acomodate for Poetry building our dependencies on install) JeOS Just enough Operating System of the openSUSE Leap 15.4 variant these days. Hence the “Built on openSUSE” use to hounour various upstream ‘marks’.
For an exact indication of what constitutes a rockstor install (minus the stuff installed by dependency) take a look at our installer repo:
Obviously I am not saying that Rockstor is causing the kernel panic, since your stuff is so high level.
But it seems a weird combination of smart. available() and my logging and my nvme ssd might be causing this.
A note for other readers: I have modified the original Rockstor code.
I should also note I have seen a red dmesg line saying something like “nvme ssd error log increased from 8 to 11”.
I will investigate it further and run more deep tests on my RAM as well as the nvme ssd.
My specs are:
DDR4 16GB PC 2666 CL19 G.Skill KIT(2x8GB) Aegis
F4-2666C19D-16GIS
CRUCIAL P2 SSD 250GB M.2 80mm PCI-e 3.0 x4
NVMe, 3D QLC CT250P2SSD8. very cheap, could be problematic
Two HDDs. sry im on phone and am pretty sure these are not at fault
BE QUIET! System Power B9 450W (BN208) 80Plus
Bronze ATX
AMD Ryzen 5 5600G
GIGABYTE B450M H DDR4 AM4 mATX RGB
EDIT: I’ve run short tests on the nvme ssd and ram. Ram is dead