Nice find, thank you! I guess I haven’t been using Syncthing heavily. My logs are only 9.6k. I wonder why you have so much log data. do a “docker logs syncthing” and see if there is any useful information. You can also open that json.log file for more clues.
Here’s the temporary workaround: echo “” > 94c3198928ec48c7007b27e9c2e44164fc45e30fee66c0e7975b261fee48ad4d-json.log. That will truncate the log file. You might want to turn the Rock-on off, but looks like it crashed anyway.
It will list all qgroups not in use and delete them. It could free up a LOT of space depending on your scenario. I think that + truncating the json log file(from my previous commend) should fix your problems.
I have a proper fix in the works, but it will take some time. I may choose to wait for 4.2 kernel as there could be very useful qgroup fixes in it. Here’s the issue for your reference: https://github.com/rockstor/rockstor-core/issues/687
I then rebooted my Rockstor server and still same result.
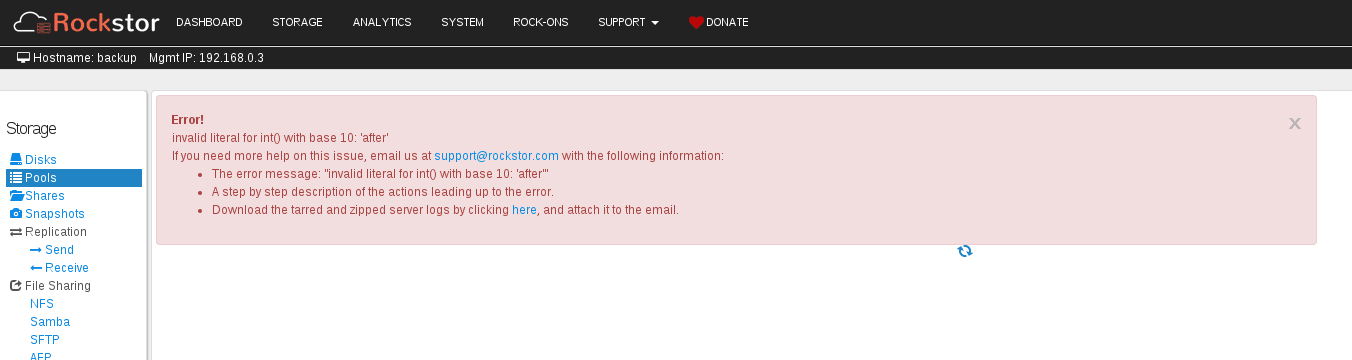
If I upload logs can you please help me to diagnose this problem I dont see why a 250GB subvolume should be recieving these errors when it has ~6MB used.
What commands can I use to view the used quota amounts?
Could it be another volume that has the quota exceeded?
What logs can I upload in order to have you assist me to diagnose this issue?
@sirhcjw Happy to help, but I request that you provide as much data as you can in your comments. When you ran the qgroup-clean, what was the output? You can run it again and report back.
Also, did you truncate the json log file of syncthing container?