Hey guys - first off, search on the forum isnt working… or I’m dumb
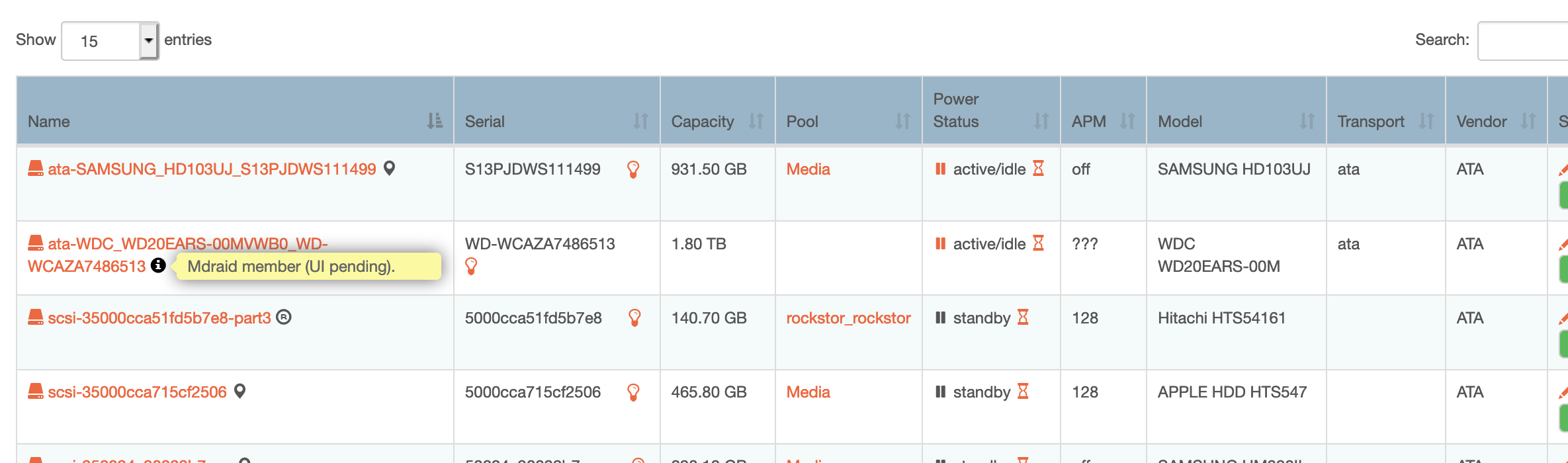
Now on to the reason I am here… I have installed a new SATA disk, and I after getting it to appear (needed to reboot…) I am not able to add it to a pool. When I try and add it, I see
We have a css / theme issue of sorts so that the normally visible magnifiying glass icon for search is black and so becomes invisible. If you mouse over in the top right you should see it. I’ll try and have a look at this soon.
The “Rescan” button at the bottom of the Disk page should have help here, but yes sometimes hardware can be tricky when live plugged.
This is currently ‘by design’ as we don’t cater for mdraid except in a very limited use. And so we currently just show the:
message whenever we encounter one. If you are certain that this disk’s prior life is over then you can wipe it’s mdraid personality along with all it’s prior data via the instructions in the following issue we have open to improve the docs on this element of using prior use mdraid disks:
But do note that this will wipe the disk of all it’s prior data. This disk was likely in a NAS before hand which used the mdraid software raid system. Rockstor only caters for the btrfs raid/file system. Hence the requirement to wipe and start afresh.
Of particular importance when you do this, as root in a local terminal or via a ssh session to your Rockstor machine, is that you select the correct disk.
In your case the disk name is displayed in the picture you posted. And so it’s full by-id name (those used in Rockstor) is as follows:
/dev/disk/by-id/ata-WDC_WD20EARS-00MVWB0...
so if you use that name (TAB key should auto complete) and make absolutely certain it is definitely the correct disk, then you can use the “mdadm --zero-superblock you-dev-here” command, after first stopping what is likely to be /dev/md0 and you should be good. The disk will then no longer have this ‘special’ superblock and so should be usable by Rockstor.
Hope that helps and take a look at that issue for a little background. And if you are at all unsure of what you are doing here then do ask for more explicit instructions as you will be destroying prior data on whatever disk you specify.
It may well be all of them but to be sure first if you post the output of:
ls -la /dev/disk/by-id/
So you can see the by-id names to canonical temp names.
And then from the output of the following command:
cat /proc/mdstat
You / we should be able to see what drives are associated with what /dev/md* (Multi Device) software raid devices.
If as I suspect they are all only associated with your previously indicated drive (indicated in the Rockstor Web-UI), and there may also be a missing drive their if it came from a set.
Hopefully that should help. If they are all associated with the same devices and that device translates to the by-id name given in Rockstor’s Web-UI and you are happy to loose all data on their then you can proceed with the process of wiping it via stopping all associated md devices and then executing that --zero-superblock command with either the by-id name or the short temp name of the problem drive.
Hope that helps. And if in doubt then just post the output of those command here to help others see what the situation is.
From a quick look your have successfully stopped the /dev/md devices but your have not specified the correct device for the --zero-superblock.
If you have a look at the original issue:
One stops the md devices (hence them not then being available) and then zeros the superblock on each of their members.
And as you say it looks like you have only the one member sdf.
But do take care as the link between by-id names and the canonical /dev/sd* names changes from one boot to the next so do double check that sdf is the correct drive.
If you haven’t rebooted then it should still be the same one.
So in short you ran the zero superblock commands on the meta multi devices that you had already stopped. But you need to run the zero superblock command on the md members, once you have stopped the md devices that a disk backs.
Hope that helps.
Also note that you should be able to use the by-id name, which doesn’t change from boot to boot, with the zero superblock command. At least I strongly suspect so
Couldnt get that too work… then I realized that since I didnt care about the data - there was no reason to keep the partition table that was giving me this headache. I destroyed the partitions and Rockstor was happy and I was able to add them to a pool Thanks!
@Ben_Abecassis Glad you finally go this sorted and thanks for the update.
If it was only the partition table that was upsetting things then the Web-UI would have been able to help you their. Anyway you are sorted now which is great. We have to be extra careful with deletes and so tend to tread lightly. Ideally all drives arriving are wiped of all prior ‘lives’. Ex mdraid and ex ZFS members are the most problematic as it goes. All others should be ‘wipable’ from within Rockstor’s Web-UI via the cog that appears next to them.
 Thanks!
Thanks!