So I just recently switched my large (120ish TB nas) over to Rockstor after testing it for a handful of months.
I really enjoy everything it has to offer but I am currently running into my first major issue.
I have a pool that is running raid5c1 and it is my biggest pool. It experienced a hard drive failure, as one does. The good thing is that the pool didn’t have any issue picking up the slack and I have been running in parity.
The bad starts right after that. This failure occurred at the beginning of the month and I am still running in parity 11 days later as I just cannot get the missing disk properly rebuilt on a new drive. All this time in parity has caused lots of corruption to occur and now the house of cards is crumbling.
Today I woke up to something like 20k read IO/errors on 2 of the drives in my pool. I rebooted the system and tried to mount the pool in ro mode so I could work on getting something done with this missing drive, but now I can’t get into ro mode.
Below is the rather helpful screenshot I am getting

I can recreate the issue at will but nothing pops up in the system logs related to this. I am really struggling to right now. Luckily there isn’t anything “critical” on here, that is all on a raid 1 and backed up offsite. But that doesn’t make the current experience any less painful or frustrating.
I have therefore 3 major questions
- How do I get this pool mounted in readonly mode?
- What is the correct way to deal with replacing a drive that dies suddenly? There has to be a better way that doesn’t take weeks
- (Not mentioned yet), what is the correct way to perform scrubs?
I am kinda lumping things together here, but scrubs just don’t happen on this pool which is likely a contributing factor as to why I am where I am. They take absolutely forever. I am running all WD Red Pros (except for 2 Seagate IronWolf drives), so there is no SMR shenanigans going on.
Below is a screenshot showing the pain, you can actually see in the speed when content began ending up on this pool.
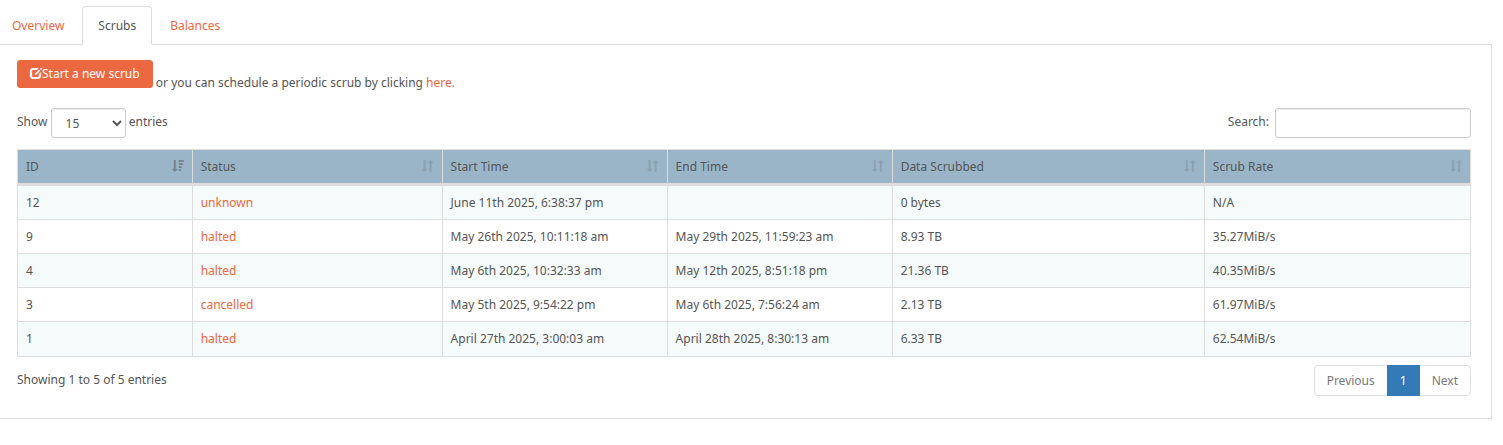
I acknowledge the scrub speed issue is a btrfs raid5 thing but hopefully I can get some guidance on it as well.
Edit:
I should add, I did what was advised in the screenshot (stopping rockstor, unmount and restarting rockstor) and the only thing that did is remount the pool in rw which is not the desired outcome here