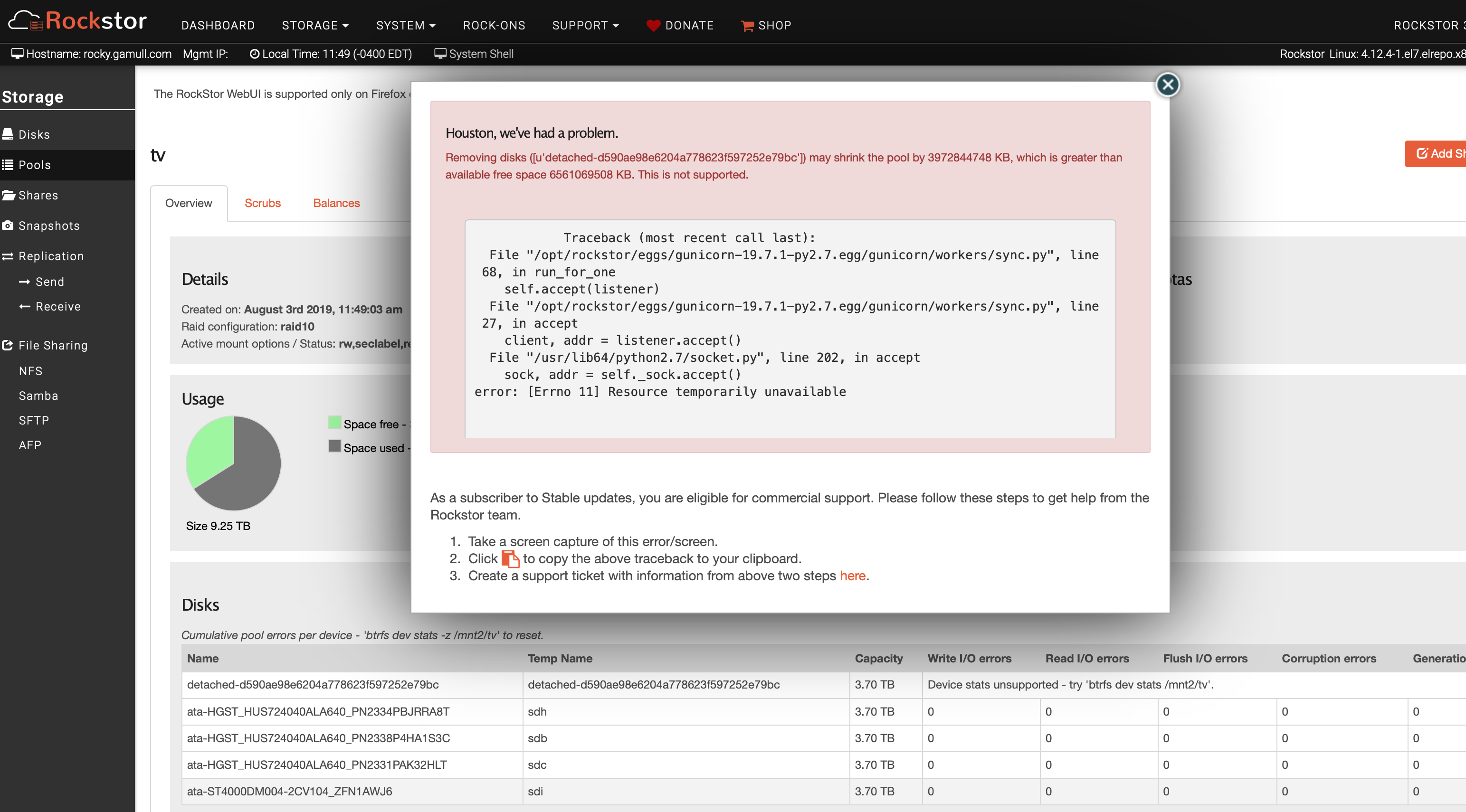
I’ve replaced a Btrfs disk and it shows as a detached member in the pool in the UI. The disk does not appear in the Btrfs fi show and the remove command (UI) reports not enough space to remove it.
Traceback (most recent call last):
File “/opt/rockstor/eggs/gunicorn-19.7.1-py2.7.egg/gunicorn/workers/sync.py”, line 68, in run_for_one
self.accept(listener)
File “/opt/rockstor/eggs/gunicorn-19.7.1-py2.7.egg/gunicorn/workers/sync.py”, line 27, in accept
client, addr = listener.accept()
File “/usr/lib64/python2.7/socket.py”, line 202, in accept
sock, addr = self._sock.accept()
error: [Errno 11] Resource temporarily unavailable
[root@rocky ~]# btrfs fi show
Label: ‘rockstor_rockstor’ uuid: 3e3b17e7-2490-484f-9c8a-f402b2a51517
Total devices 1 FS bytes used 14.54GiB
devid 1 size 122.66GiB used 18.06GiB path /dev/md125
Label: ‘tv’ uuid: 76b16cb2-0f13-401d-8395-c408cfc0fdfe
Total devices 4 FS bytes used 6.11TiB
devid 1 size 3.64TiB used 3.06TiB path /dev/sdc
devid 2 size 3.64TiB used 3.06TiB path /dev/sdi
devid 3 size 3.64TiB used 3.06TiB path /dev/sdh
devid 4 size 3.64TiB used 3.06TiB path /dev/sdb
Label: ‘backup’ uuid: 8ac79908-cb09-4568-bfc8-b0fd377dcf15
Total devices 1 FS bytes used 439.69GiB
devid 1 size 3.64TiB used 479.02GiB path /dev/sdg
Label: ‘movies’ uuid: c77c9722-7a5d-458c-bb1f-c077a950771d
Total devices 4 FS bytes used 5.40TiB
devid 7 size 3.64TiB used 2.71TiB path /dev/sdm
devid 8 size 3.64TiB used 2.71TiB path /dev/sdk
devid 9 size 3.64TiB used 2.71TiB path /dev/sdj
devid 10 size 3.64TiB used 2.71TiB path /dev/sde
[root@rocky ~]# btrfs scrub status /mnt2/tv
scrub status for 76b16cb2-0f13-401d-8395-c408cfc0fdfe
scrub started at Fri Aug 2 16:40:54 2019 and finished after 08:18:55
total bytes scrubbed: 12.22TiB with 0 errors
[root@rocky ~]#
Did you do this via btrfs commands at the cli or via the Web-UI?
I’m assuming you are using latest stable here by the way: 3.9.2-48.
Although this is not related to the core cause of this issue it does in this case represent the ‘blocker’ and we have an issue for it here:
which was addressed in the now merged pr:
Which also in turn addresses a bug we had in removing drives in the first case (i.e. as per the pull requests title).
This pr will be included in the pending 3.9.2-49 release. But that pr is actually quite substantial and changes a number of disk and pool management / reporting mechanisms. So we would be best to approach this issue once that code has been released. The issues re the detached disks are only really cosmetic and hopefully the new code should allow you to remove the drive by the normal Web-UI means anyway.
So in short lets circle back around to this one once that code is out. It may be that the new code doesn’t deal with this case ‘after the fact’ but we can address that once we are there. But it should, going forward, at least be a little more intelligent re disk removal and size.
The preservation of detached disks, read prior attached disks, is by design but can bite us back occasionally. And that newer code changes a bunch of stuff about how we track such removals and ended up removing a whole bunch of inefficiencies we had build up over time.
Thanks again for the report and lets pick this up again post 3.9.2-49 release. Assuming you are running a rockstor rpm based install in this case that is.
I did use the btrfs replace command on the CLI. The UI gave me some error that said it wouldn’t do it. I’m fine waiting until the next release, the error/issue is cosmetic as far as I can tell. I reset the stats on the pool which cleared the disk error and since that detached disk was removed from btrfs it cleared. I’ve had times where this btrfs not enough size bites me but I thought there was enough space. It’s 4 x 4TB drives (i have two pools of this configuration with RAID10).
I toyed with using pgadmin and editing the database but I’d much rather wait since I risk having to reinstall especially if I don’t want to mess up quotas.
Yes on using latest stable.
Glad to hear you appear to agree on this being cosmetic. I wish I followed the advice of rescan, swap drive, rescan, replace. I’ll see if we have an opportunity to call that out better in the docs unless it’s there and I missed it. Would it be prudent to ask for a scan prior to disk operations (perhaps a question to the user defaulting to yes?)
Off-topic alert: Did you look at stratis in RHEL8 as an option? This may be worth a look before going to SLES and the updated BTRFS as it is the FS Red Hat decided to go ground up with after bailing on BTRFS.
Stratis is not a Filesystem but a set of management tools to help with easier management of LVM (I think) and mdraid and it uses XFS as it’s actual file system: and XFS does not have data check summing, but it has recently, in filesystem time, picked up (by default) metadata check summing. So just a rework / wrapper around existing technologies really. Which is more than welcome as we have had all these disparate technologies / layers around for ages and had to work them together ‘by hand’ for far too long now. But Rockstor is focused very much on btrfs from the ground up and as such we have a single upstream project that does both disk and file system management. Also Stratis is very early days, although granted it stands on the shoulders of far more established technologies, I’m at least of the opinion that once we get our openSUSE move sorted we should be in a better position to benefit from the now maturing nature of btrfs.
Thanks for the pointer and yes Stratis looks like a fantastic project but it is not for Rockstor given it’s use of XFS and the consequent limitations their in. I like the idea of a single ‘entity’ to do both disk and file management and so far there is only ZFS and btrfs to fit that bill, with btrfs being the new comer but preserving the block pointer re-write capability that was originally planned for ZFS but has since been abandoned.
Also, I think we have enough on our plate as is .
Yes RedHat only ever had btrfs as a technology preview so it was never actually supported. It was never much of an investment for them and once they no longer had a staff member who worked on btrfs it made sense for them to not see it through to support. However openSUSE / SUSE are very much invested in btrfs, at least for their root filesystem so we should be in better shape once we inherit their massively backported kernels (Leap variants) and plain up modern Tumbleweed kernels. As such it’s no surprise that the btrfs developers themselves, a few employed by SUSE, are considering using the tumbleweed kernels for their CI system: