I believe my USB stick is starting to go bad, so I want to reinstall onto a new USB stick. My question is, what do I need to “backup” in order to come back up with minimal loss of configurations.
Currently I have 3 Rockons installed, a few scheduled scrubs/snapshots, NFS shares, Samba shares, AFP Shares, and a handful of Users created.
Also, I have two BTRFS pools. And I obviously don’t want to loose those
Is it as simple as taking a config backup, then popping in a new USB key, and restoring the config? Any gotchas or things to look out for?
On a side note, I saw another post here about a possible replatform onto OpenSUSE. Will there be a method to migrate over to that from CentOS? Would it be a similar process (take a config backup, pop in new USB, restore config). Or would we need to start from scratch?
OK there’s a lot of questions in quite a few words there, I’ll try a quick first pass so we can go from there as there are others who also have experience with this. And on the plus side, as long as you have the recommended separation between system disk and data disks, ie you have not created any additional shares on your system disk, you can try this procedure a number of time as the data pools are already known to your existing USB stick install and you can repeatedly import them to other installs as you try out this migration. The import mechanism simply scans the pool via a given device and dumps the arrangement of shares, clones, and snapshots it finds (all just subvols in various locations) to it’s otherwise un-populated database. In fact on every boot this database is checked against the connected pools and only updated if a prior imported pool has any changes.
First off the Reinstalling Rockstor howto is a good first read, especially if you are re-purposing a prior use device for you new system disk (in the howto it’s a prior Rockstor install but that’s not relevant here as your’s is suspect now).
The essence of your task (given the caveat’s detailed later on below this numbered section) is:
To take a config backup and download that file to a client system: it’s a zipped json file so once unzipped is human readable so before doing anything you can look to see what exactly is in that file to reassure yourself mostly of what is not in that file.
Details of the current config back capabilities are to be found in: Configuration Backup and Restore
Note that this is far from a complete/comprehensive system and I’m due to revisit this myself but as always time is a limiting factor.
Before you do the new install, on a shiny new and hopefully high speed USB key or the like (or there be dragons), make absolutely certain that your data disks are physically disconnected (Not connected). And always do the disk connection / disconnection with the machine powered down. That is a must as human/software errors are inevitable. Obviously a backup of all that you have is also highly desirable but that is not always possible given the volumes involved, but anyway we can all judge that risk for ourselves.
Once you have what is essentially a blank / re purposed system disk, and only this disk (var the installer medium), attached to your target computer system you can do the fresh install and then select your update channel of choice and apply all the updates, as the iso is quite old now there are a tone of them and they can take an age to install. Make sure they are all in place (the system CPU will have calmed down after a period of high activity during their install) and there will be no yum processes running (see ‘top’ output if needed), before you then reboot this system into it’s new shiny (also old still, sorry working on that) kernel and all the new CentOS updates that have happened in the mean time. Note also that during Rockstor version updates the Web-UI disappears for a bit (a few minutes sometimes) while it restarts it’s own services.
Now you have your freshly installed and fully updated install (stable channel is much better now on the Rockstor code side) you are ready to use that system to import your Pool / Pools.
Shutdown and once the system is fully powered off re-attach your data disks; make sure you don’t miss any of them or you risk causing problems down the line by actively introducing a degraded state. If this happens btrfs mounts ro by default anyway but still! Stable shows red flashing warning of such things these days by the way.
Power up the shiny new system and once it’s settled down (CPU activity) go for the Pool import. See the Import BTRFS Pool. If all is well this should restore your prior Pool, Shares, Clones, and snapshots by simply reading what looks familiar (prior Rockstor creations) from the pool and asserting it in the otherwise empty database of this new install.
Attempt the config restore. Noting that it’s an incomplete system currently so be prepared for failures / holes in it’s operation, improvements are planned. You are most likely going to have to make up the short fall here via manual intervention hence the recommendation in 1) above.
Out of interest what leads you to this belief? I know in the stable channel code there are indicators for this on the pool details page. Plus all variants have the scrub reports which can also indicate fs errors, corrected or otherwise, plus theirs the S.M.A.R.T reports, self tests.
Rock-ons are a problem with re-installs / pools moving from one system to another: like what you are considering, given you are likely to completely replace your system disk.
Rockstor currently has no method for inheriting the Rock-ons root. But you can create a fresh Rock-ons root once you have your new system and then re-install the same selection of Rock-ons you had previously. And as long as you set them up to use descreet shares, as is recommended, they all the Rock-ons should then pick up from where they left off as they will have the same config and data shares available to them as they did previously. Only they will all be running from a freshly setup Rock-on root. You can even leave the prior one in place, which would even pickup again where you to boot again on your prior (flaky) USB system disk.
So yes Rock-ons are a caveat and you are best advised to setup a fresh Rock-ons root share to go with your fresh install. Room for improvement I know but at least all config and data for each of the Rock-ons should be maintained across the re-install.
Just import each in turn given all gotchas above and below.
The above referenced Rockons caveat.
Don’t attach or leave attached a prior Rockstor system disk. The Web-UI and possibly some lower levels, will get confused by 2 similarly labelled pools (most likely rockstor_rockstor).
Any data stored on the failing system disk: if any just move it to it’s own shares (subvols) of your data pool. Always best to keep system and data concerns separated anyway.
In a prior post you also mentioned using the Rockstor initiated full disk LUKS encryption. In which case you need to be assured you have the required passphrase for the associated devices (the passphrase is most likely the same for them all, which is usual in this circumstance). And if you use the recommended method for opening the LUKS containers on boot then the relevant key files will be in your /root which is on the system disk, chicken and egg that one but anyway that’s where they will be and are named obviously enough (from memory anyway). Also relevant to full disk LUKS: you will have setup the required container unlocking mechanism for all concerned devices prior to their import, ie select for each container the unlock mechanism and also reboot to ensure they are all then unlocked prior to proceeding with the pool import. See the LUKS Full Disk Encryption for guidance here.
Generally it’s good to update the existing system first but in your case that is of course risky given the flaky USB stick; as that way you get the latest config export code, but if you are on latest of either channel I think you have the latest of that code anyway. But stable channel has a few import and mount improvements.
Only via the config-save, re-install, pool import, config restore method. But we are a ways off from having any rpm releases just as yet as we have to re-roll our iso and the associated rpm creation back-ends: but we are very close to an initial source build option though, and I’m due shortly to write an official wiki entry on where we are at on this one and the remaining known caveats: once the required associated pr’s are in (I have one in final testing in house) and have been merged (another is submitted and currently pending review by project lead @suman ).
Hope that helps and remember that if it goes wrong, there is always the option to return to the existing system disk and take more notes prior to having another go. The pool file systems are really just mounted on startup and unmounted on shutdown, but only if they have been previously imported or created on the Rockstor install in question. If you are nervous about this whole procedure then I suggest you build within a VM a couple of throw away systems and populate one with a setup akin to your ‘real’ one and then transfer it’s data disks to the other system ie what you are facing here on real hardware.
Out of interest what leads you to this belief? I know in the stable channel code there are indicators for this on the pool details page. Plus all variants have the scrub reports which can also indicate fs errors, corrected or otherwise, plus theirs the S.M.A.R.T reports, self tests.
No, you do not have this code in Rockstore. That is in the generic disk interface, and not even in the device driver, and may even be in the specific disk, as you suggest indicated in the S.M.A.R.T. fields. But the device will be read repeatedly, until the reading is correct You can notice this by the device gradually degrading and going on a sporadic very long transfer time. CRC is used in Flash memory to balance performance and quality. Degradation will happen, and the USB memory should be replaced. It is fully possible to code a device driver that makes use of “bad” USB sticks: sense transfer time and make some special files for spots that are slow - just swap “block”. But the new media is not like old magnetic media that you could “refresh”. That is not possible on flash - it is bad, but using only the good parts can double expected life.
@knut Welcome to the Rockstor community, and thanks for your attempted correction.
First off it is considered good form to use quote marks (or the like) along with attribution when quoting. We don’t need full on academic format here but the forum Web-UI provides a nice facility where if you first highlight a piece of text you want to quote, it will directly there after produce a contextually placed “quote” popup which if clicked produced such as I have reproduced below. It makes things easier for those following through on the sources of such things to gain context. Ironic in you attribution altercation.
To clarify for others popping in on this thread, your first paragraph is a direct quote from @kupan787 :
and your second is a direct quote from me responding:
I’d like to point out that I see this as a rather aggressive and confrontational tone for what is normally a friendly/approachable place: this forum. I, as forum moderator, have worked towards trying to maintain this quality within the form and I like to think that those efforts are welcome.
To your point, I think what we have here is a simple mis-understanding of what I was referencing. You will note that I stated:
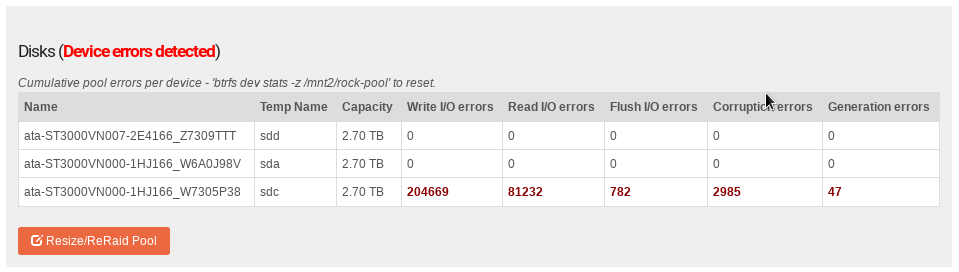
Pertinent elements in this are “I know …”, because I wrote it; and “… indicators …” which in this context references the “… pool details page.” and in pictorial form is as follows:
There have been improvements since then such as the “Temp Name” column addition but most of it remains as is from that code commit which was released in a Stable Channel update as version 3.9.2-35.
Yes we also have our S.M.A.R.T info indicators within the Web-UI. These were added a while back by @suman but I and others have improved them from their original appearance a little over 3 years ago I think it was. See our S.M.A.R.T howto doc which correctly attributes their ‘source’ as from the Smartmontools utility.
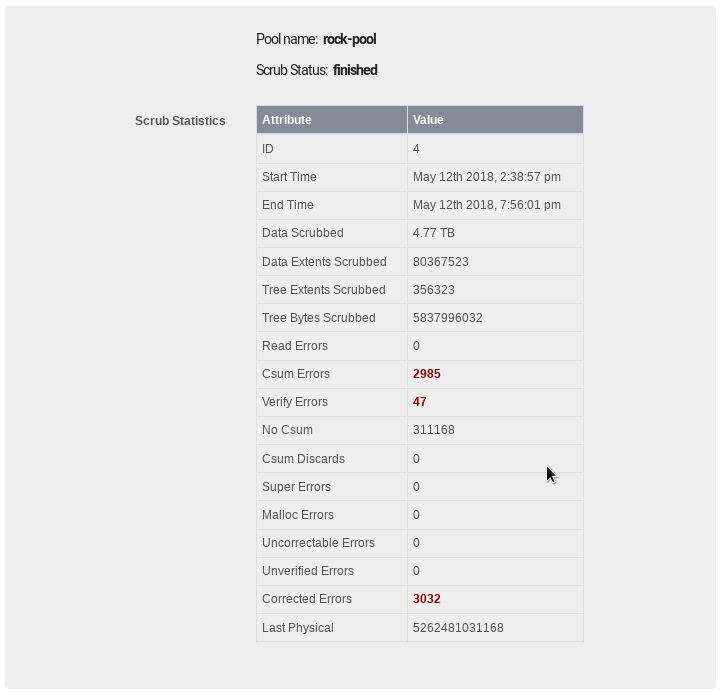
And my reference to the scrub reports “… which can also indicate fs errors, corrected or otherwise …” is pictorially referenced thus:
which in turn built upon some backend / database code, by @suman, that I found hidden away without a Web-UI component; so I added one, as referenced.
These scrub stats originate, like the pool dev stats, from the btrfs fs level, ie see:
where we attribution within code to the origin of the scrub statistics for example.
Some of these stats are from it’s own check summing behaviour on both data and metadata. And with the redundant btrfs raid levels it is also able to correct some of these errors, as in my example above. Devices, as you intimate, are not perfect and will often try internally many times prior to returning what they deem to be what they were asked for; but likewise they will still also occasionally fail to achieve this goal and return something corrupt. The full check summing type filesystems such as btrfs and zfs can detect these failures and on occasions correct them where the drive failed to. Hence these stats / Web-UI indicators being potentially useful to assess a devices health: and thus the question of mine you copied.
But as you correctly indicate some of these errors, ie the write_io_errs / read_io_errs emerge from lower levels such as the kernel block layer or VFS, or indeed lower again such as the firmware of the specific drive. Incidentally facebook was famously able to establish an HDD firmware bug in some of their devices by their use of btrfs and it’s build in check summing. Neither the drives themselves, nor the block layer, reported these errors.
So essentially I referenced ‘indicate’ as opposed to ‘origin’ (media, drive, fs etc) sense logic, which in the case of both the referenced scrub detail, and pool details page, can originate at the btrfs level: without hardware, firmware, driver, block layer, scsi code, or vfs complaining; i.e. just an observed / detection corruption due to fs level check summing (such as in the facebook example).
Rockstor is essentially one big indicator / actuator in a sense, or rather many smaller ones tied together via python, django, and javascript (in the browser). All smoke and mirrors for stuff on the linux OS command line.
Hope that helps to identify at least where I am coming from and the code to which I referred, and I appreciate your input on the lower levels of hardware and yes it is messy and sometime pretty flaky by design (cheap USB sticks). I have electronics (digital and analogy) and material science knowledge and training which I like to think helps with at least an appreciation of the fields we find ourselves in on this form. I’m not personally, for example, a fan of the SMR drives as I think it’s taking things a little too far and will end up confusing purchasers as to their viability in some setting.
So thanks again for your input and lets try and appreciate that we are all here trying to make a better future and have technologies such as btrfs made more accessible. And for that we also need to take care with our presentation to maximise our potential knowledge base. Rockstor code, which is under the GNU licence (bar the open source js libraries), stands on the shoulders of GNU giants such as our linux disto bases: currently CentOS and moving to openSUSE, which in turn employ the linux kernel.
Apologies if my ‘presentation’ appeared inappropriate to you.
It is most relevant what you write, it is some of the “leftover” from the “Mode Sense” command that you can send to some devices. These will then dump field that you can use to diagnose failures, like you describe. The problem is also that there is no “standard” for these. So documentation is all over.