The Green drives park their heads way too often without active power management from the OS, which means on Linux they rapidly exceed their lifetime-rated head park cycles. Green drives have a reputation for being short-lived, this is one possible cause.
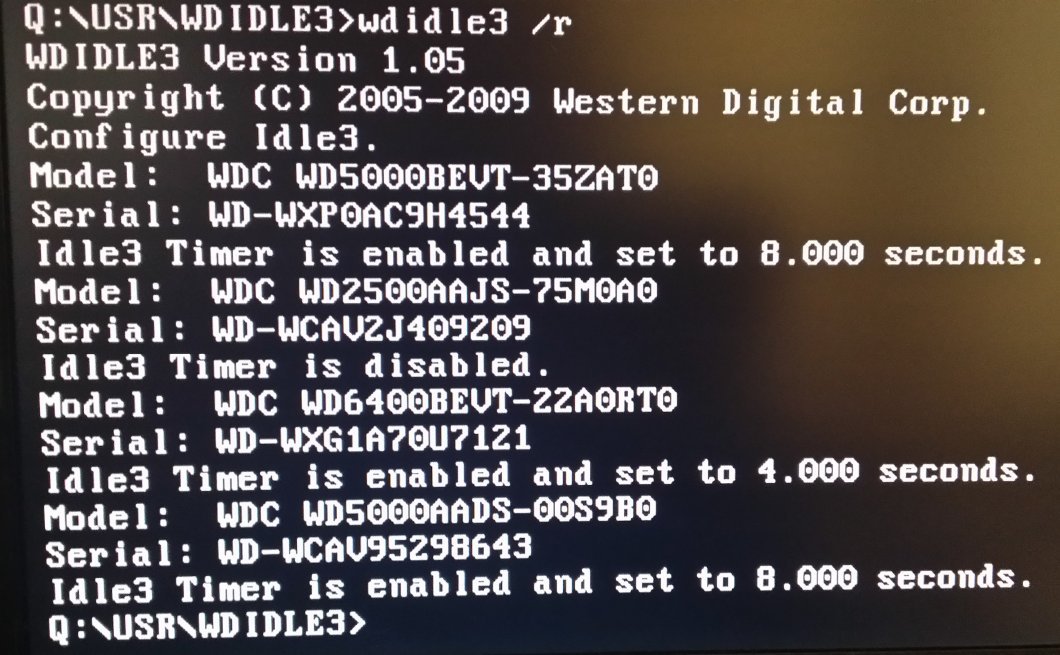
This problem is rumored to occur with a few Red drives as well. There’s a program called idle3-tools that can change the drive firmware to allow more time for the drive to idle before parking the heads. It should be included with Rockstor.
@tcmbackwards Are you using this tool on Rockstor currently? Please do share your results and experience over time. Perhaps others will also provide more testing and feedback.
@tcmbackwards@suman Thanks for the url, yeah the biggest problem with such ‘green’ drives is that the raid might detect the drive as failed. Which is a much bigger problem then the counter increase. Although I have seen drives with more then 10,000 hits and still working fine, Personally I think it is not a good thing to use any such green drives in a raid set. Another option is using a RAID controller card as most of them give you the option to set the polling interval for drives so you can still use your green drives. Please note that the program is still experimental, I would not recommend to use it if you have any warranty left on your drives. I don’t think that Rockstor yet should implement such tools, just my 2 cent.
@TheRavenKing You’re correct about the raid failure, though that shouldn’t be a problem for btrfs. The problem comes from the drive hitting a bad sector and trying really hard to reallocate some of the spare sector pool to complete the IO. This can take many seconds, and a typical RAID card can give up waiting and mark the drive as failed prematurely. Such bad sectors aren’t a disaster, in fact every disk has some of its sectors mapped to that spare pool to cover up manufacturing defects, within tolerance. If you hear your disk make a loud clunk during a regular operation, it probably hit one of those sectors and had to jump to the end of the disk. Red disks cut this operation short, they figure that it’s better to replace a drive that’s showing hitherto unknown bad sectors so they just drop the operation and report the failed IO to the OS.
Btrfs doesn’t care about such errors because it has no notion of failing an entire device (yet). The replace operation was created to handle the situation manually but btrfs won’t automatically drop the disk if it stops responding for a while. This can make the system slow and flaky but if you can plug in a spare disk and run the replace your data will be fine.
The head parking bug, however, has the potential to crash the head and kill the whole disk.
@suman I installed gcc and compiled idle3tools on the rockstor system and it worked fine. I’ve seen prebuilt deb packages around the internet but I don’t know about rpms.
@tcmbackwards I had a look on some of my BLUE and BLACK drives 2.5" and same issue, so it seems not only the GREEN are involved, one of my BLUE 640GB drive had even a 4 sec setting Looks like people having a NAS with only 2.5" drives should really check their drives it seems all wd colours are involved.
@TheRavenKing I’ve never heard of blue and black drives doing this. What do your SMART load cycle counts say? Most drives are rated for 200-500K cycles.
 Looks like people having a NAS with only 2.5" drives should really check their drives it seems all wd colours are involved.
Looks like people having a NAS with only 2.5" drives should really check their drives it seems all wd colours are involved.