@bwc Well done on the investigation.
Re:
Agreed, but if they are all under specked, ie SATA1 being used on SATA3 for instance. But assuming they arn’t near max length it’s still unlikely to be this bad. Which leads us to the following:
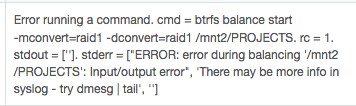
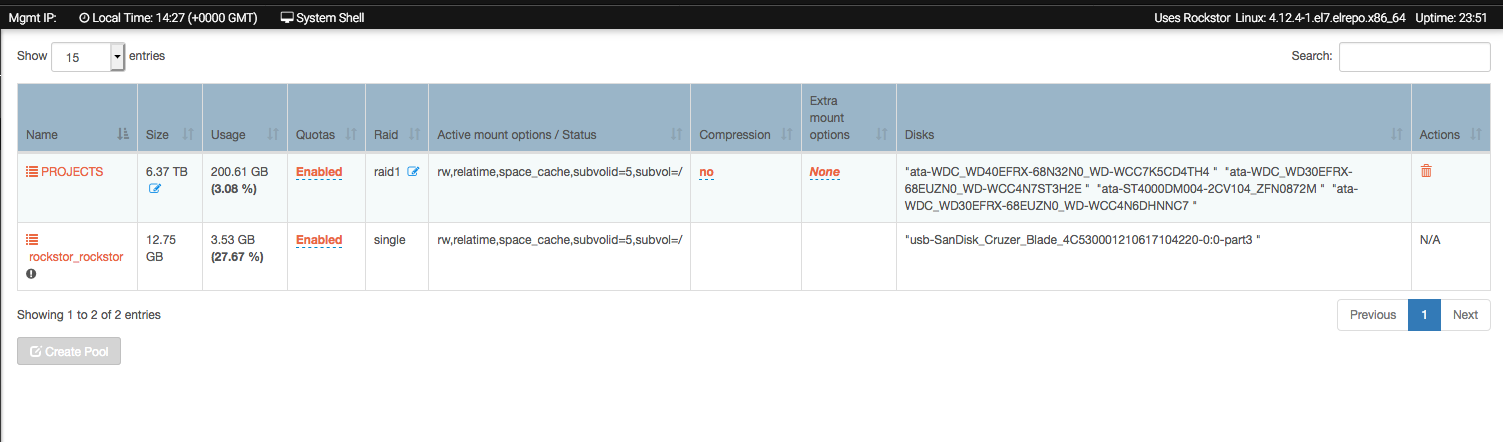
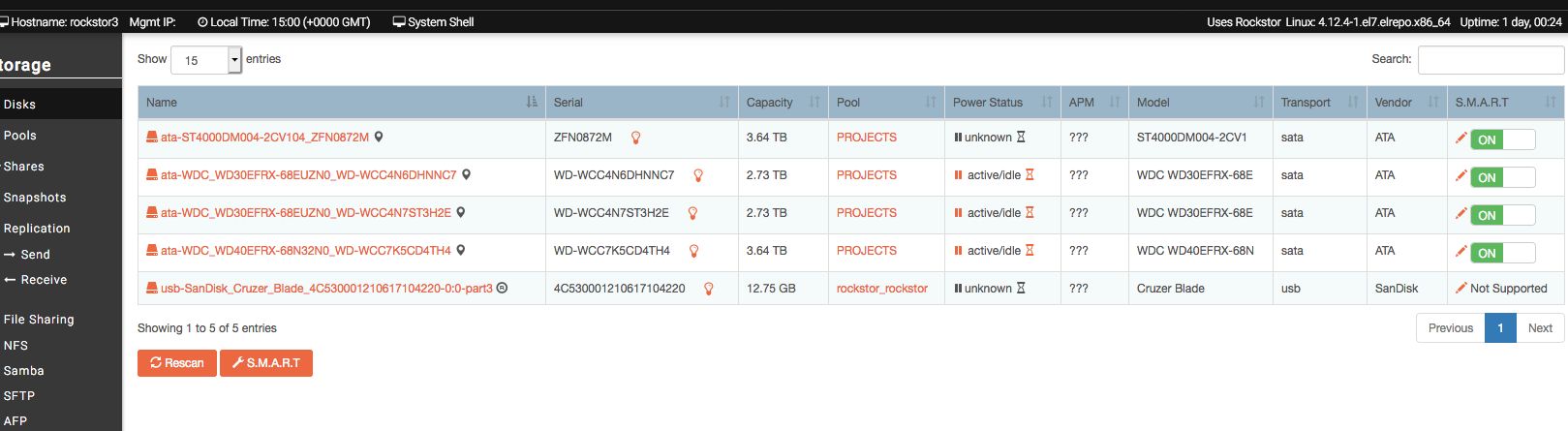
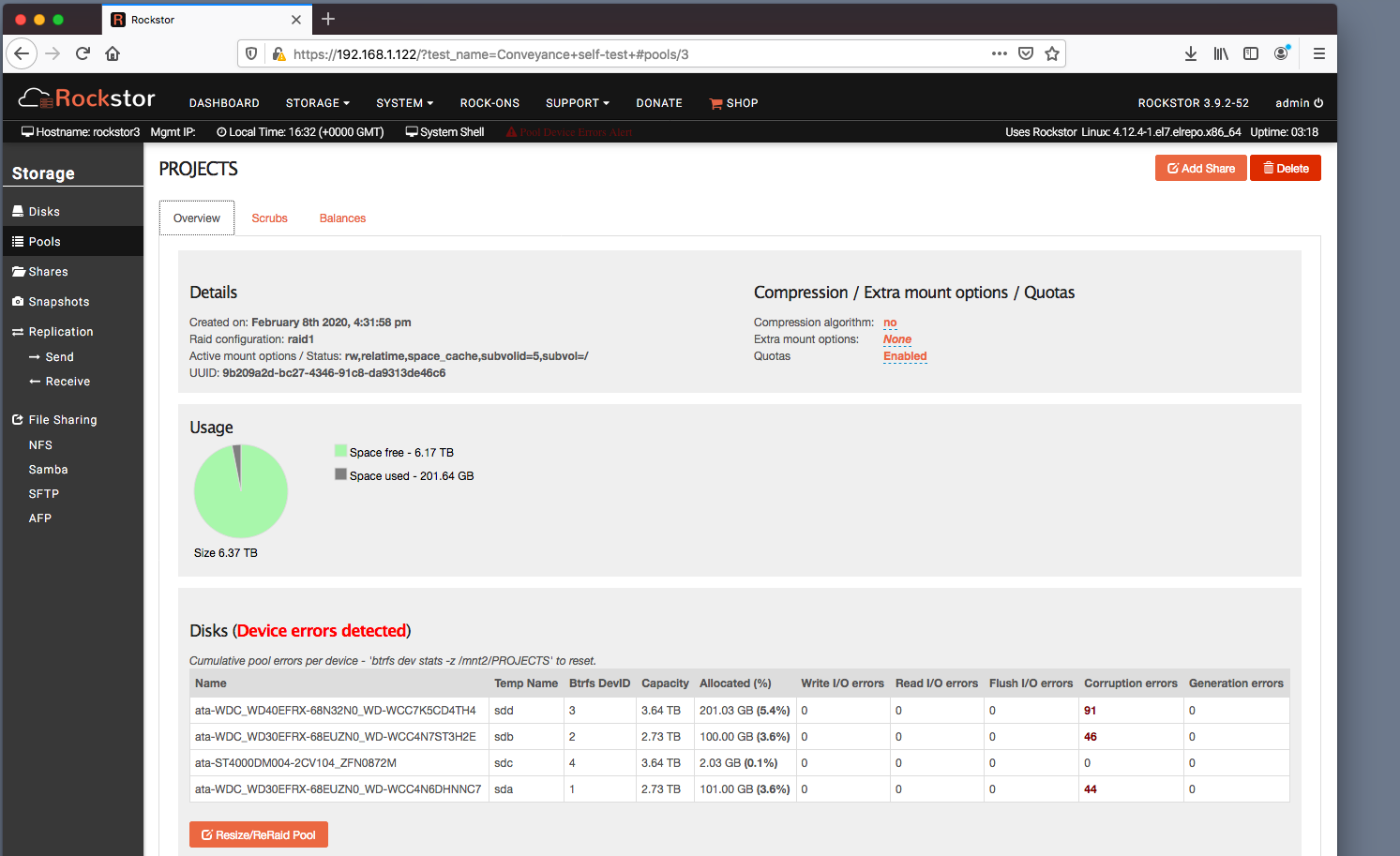
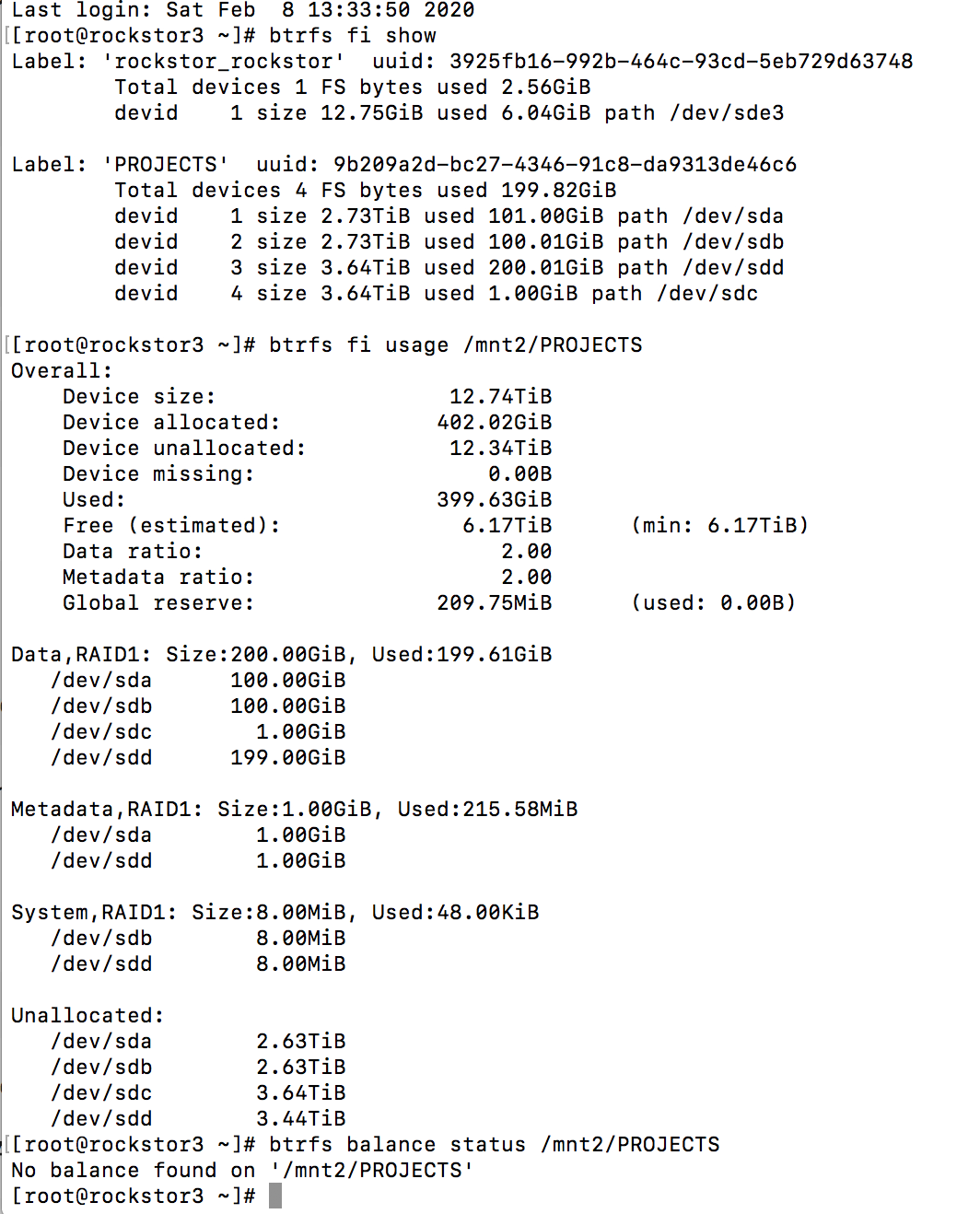
I suspect you have bad RAM. Stop all file system operations and investigate your RAM. The new drive may not be showing any effects as it hasn’t had the opportunity to ammas any data on it due to the failed (io error early on) initial balance. This now looks to be system wide. This is lack of data is evident in the lowest table in the pool details page. The new drive has only 1 GB of allocation. That’s a single allocation event as btrfs chunks are usually 1GB, although there may be 2 one fo
We have a section on testing memory in our Pre-Install Best Practice (PBP) named Memory Test (memtest86+) where the former is linked to in our Quick start doc section.
Otherwise it could be your PSU (Power Supply Unit) which may be flaking out when under load, but I’d go for the memory test first.
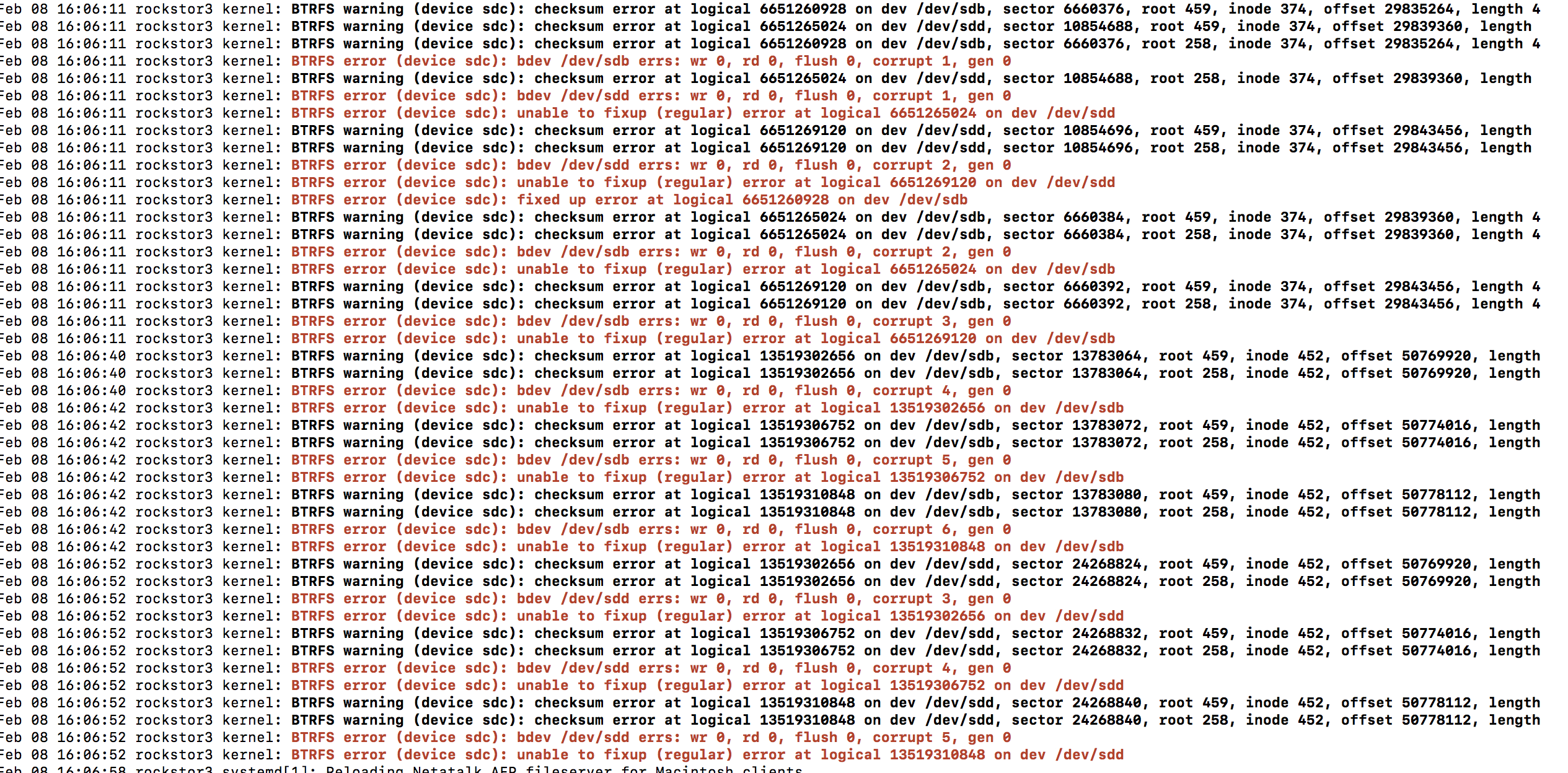
Again don’t do anything until you’ve tested your memory. You haven’t indicated a suspicion of these drives being suspect and all errors are corruption errors, ie ‘in transit’ stuff; this is what was written is not what is being read back. That can very well be caused by memory as the files have to be in memory before they are transition to disk and their checksum, to be used to test their integrity later on is calculated from the memory version. Bad memory bad everything else.
Possibly, but I’m voting on memory. And if that checks out then go for PSU, but that’s quite a bit harder to check as it may only go flaky under load and ideally you would need some fairly fancy gear to assess that, e.g. oscilloscopes etc to test for power supply noise / variation of voltage etc under the fault conditions, which may be when all drives are pulling max power and the CPU is doing the same working out all the checksums.
Incidentally your Pool may well be toast at this point, it rarely gets this bad unless their is a memory issue and the fact that some of your files are corrupt already further suggests memory also as btrfs tends to return correct data or nothing. So given what you have seen I’m guessing the memory issue will be quite pronounced. Hopefully you have more than one stick and so can drop one stick and test again if you do get errors.
Quite an interesting / pronounced problem you have there so do keep up informed. Incidentally it could also be (but far less likely) CPU cache memory. I have a story about that particular type of hardware failure from my early days of discovering linux that I can share another time.
Keep us posted and see how a memory check goes. Sometimes it can take over 24 hours of continous testing to ‘provoke’ a memory error. And given it exercise the CPU make sure your cooling is in order, i.e. you CPU fan is not clogged up with dust for example.
Hope you find the cause as this is a bad one.