Changing hard drive by GUI seems not to be working. This is necessary to resell the rockstor solution to customers.
Detailed step by step instructions to reproduce the problem
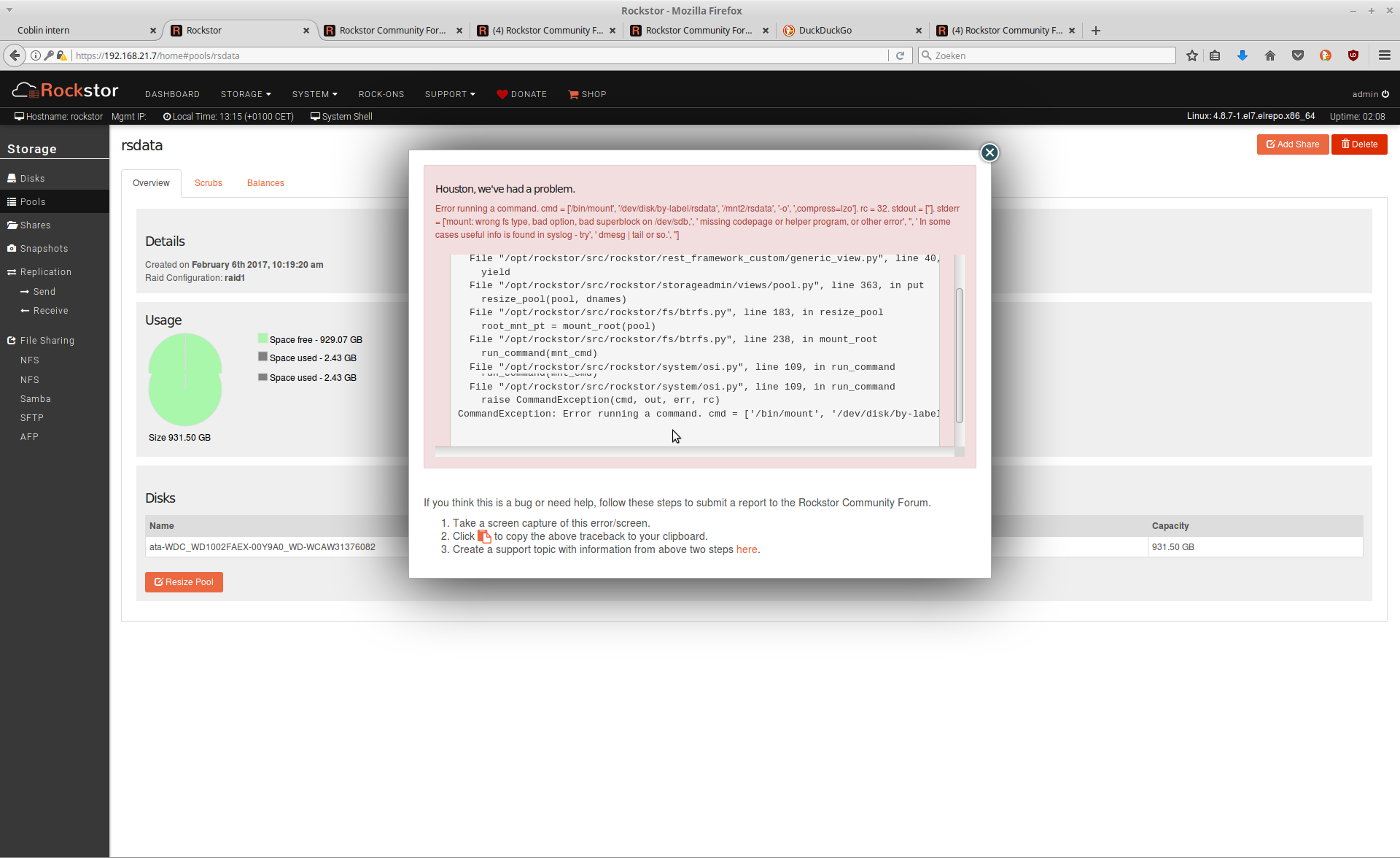
As a test I detached one of the two disks in my raid 1 array, rebooted and deleted de deattached disk form. Then I shut down the system, added a new disk and booted up, whiped the new disk in storage → disks. By adding the new disk to the existing RAID 1 pool I got the error as shown below. I also tried to reattach the disk unformatted, but it didn’t got better.
On top (in the pink area)
Error running a command. cmd = [‘/bin/mount’, ‘/dev/disk/by-label/rsdata’, ‘/mnt2/rsdata’, ‘-o’, ‘,
compress=lzo’]. rc = 32. stdout = [‘’]. stderr = [‘mount: wrong fs type, bad option, bad superblock on /dev/sdb,
‘, ’ missing codepage or helper program, or other error’, ‘’, ’ In some cases useful info is found in syslog - try’,
’ dmesg | tail or so.', ‘’]
Detail
Traceback (most recent call last):
File “/opt/rockstor/src/rockstor/rest_framework_custom/generic_view.py”, line 40, in _handle_exception
yield
File “/opt/rockstor/src/rockstor/storageadmin/views/pool.py”, line 363, in put
resize_pool(pool, dnames)
File “/opt/rockstor/src/rockstor/fs/btrfs.py”, line 183, in resize_pool
root_mnt_pt = mount_root(pool)
File “/opt/rockstor/src/rockstor/fs/btrfs.py”, line 238, in mount_root
run_command(mnt_cmd)
File “/opt/rockstor/src/rockstor/system/osi.py”, line 109, in run_command
raise CommandException(cmd, out, err, rc)
CommandException: Error running a command. cmd = [‘/bin/mount’, ‘/dev/disk/by-label/rsdata’, ‘/mnt2/rsdata’, ‘-o’, ‘,compress=lzo’]. rc = 32. stdout = [‘’]. stderr = [‘mount: wrong fs type, bad option, bad superblock on /dev/sdb,’, ’ missing codepage or helper program, or other error’, ‘’, ’ In some cases useful info is found in syslog - try’, ’ dmesg | tail or so.', ‘’]
@sourcefinder Welcome to the Rockstor community forum. And thanks for reporting your findings.
I think what’s going on here is a misunderstanding of btrfs’s capabilities / functional defaults and of course Rockstor’s developing UI capability.
Assuming this was live unplugged.
Simply physical detaching a drive will render a pool, on first boot or mount there after only, rw degraded mountable but a regular mount, the default for btrfs and consequently Rockstor, is not possible. Ie the pool was not mountable on this first reboot. One has to manually specify a degraded mount. At this point, as a one shot deal, one can mount rw degraded (but only once) where it is then possible to replace a missing drive (as you have rw) with another drive. Essentially what you were attempting to achieve: if I have read your intentions correctly.
This was most likely due to the pool being in this degrade mount option only state. Ie forcing the requirement for a manual intervention of the one shot rw degraded mount where one can then replace a missing drive with another, or effect any other required repairs, such as raid level shifting.
Your pool is likely still in this “I’m not mounting until manually instructed to mount in degraded (possibly rw) mode” state. It’s a current design decisions of the btrfs developers; and not one without some contention:
This came up again, as it often does, in a more recent thread in the linux-btrfs mailing list: https://mail-archive.com/linux-btrfs@vger.kernel.org/msg60977.html
This scenario is one Rockstor doesn’t yet provide a UI for.
But we do have a pending issue to address this via the UI:
I have linked back to this thread in that issue to add weight to it’s requirement.
The only Rockstor ‘UI way’ for removing a drive from an array is currently catered for via the resize pool option where one can remove a drive from the pool. Then a shutdown, detach the device, boot up (assuming no hot plug capability here and catering for btrfs’s current lack of a ‘bad disk’ concept), and then on subsequent reboots one can ‘resize’ the pool by adding a drive. In your example a raid level shift would have been required first in order to cater for the 2 disks minimum of a healthy raid1. Assuming the given order, or else you could first add the additional drive of course.
So I agree, we have a way to go here, but this scenario can be accomplished via command line intervention: obviously not an ‘appliance way’ to go but it is our current UI state.
Pretty much all other raid systems will default to mounting rw degraded in a similar scenario but although we could add this as a Rockstor specific mount option I think the consensus among the Rockstor core developers is that we would only really want to do this once we have a btrfs ‘expert / core developer’ on the team. Otherwise we are best to go with the established defaults from upstream and build our UI capabilities out from there. That is until we gain additional ‘in house’ resources or btrfs devs have a ‘change of heart’. I do know that multi disk functionality is to be one of btrfs’s lead developers focus at facebook (Chris Mason) this year so maybe we will see some significant ‘easing’ of this scenario as time moves on.
Essentially you are now in command line only land and a ‘btrfs fi show’ should indicate that the pool is aware of it’s missing member. The removal of the detached device named “detached-random-uuid” serves only to remove Rockstor’s knowledge of that drive. This is my current understanding anyway, although I do plan in time to lend a hand with improving pool management / health reporting as I get done with various disk management improvements ie issue #1547 and LUKS support IN #550
Hope that helps, at least with some context anyway.
In the first place: Thanks very much for your information. I had to read it a few times to get in into my head, but at this moment it’s beginning to come clear. I shut the system down every time I unplugged or plugged a drive.
Your answer is clear; the GUI doesn’t support the possibility of bringing a pool down to degraded state; it also doesn’t recognize when a pool should be degraded.
The UI way you proposed isn’t working; The Resize pool option doesn’t let you add a drive when an existing drive is managed. Changing the RAID level to RAID 0 (only option), didn’t work well; also at this point Rockstor gave me an error, saying that the broken disk had to be repaired first.
In the end whe followed the rockstor documentation on RAID 1 recovery, in that sense we degraded the pool in the shell, whiped and added the new drive in the GUI and deleted the old drive in the shell (btrfs device delete 2 /mnt2/pool-name). So most things kan happen in the GUI already.
Perfect that you guys are working on a solution; It would give rockstor a perfect position compared with, for example, FreeNAS.
@sourcefinder Thanks for the update and I’m please that you managed to get things sorted. Definitely a weak area but we will get there.
Not sure what happened with my proposed ‘UI way’ but assuming you tried it in the degraded mode where the UI is essentially at a loss (to be improved).
Not sure what you mean by ‘… when an existing drive is managed.’ I suspect what may have happened is poor interplay between btrfs modifications on the command line and Rockstor’s representation of them. There is always the option to disconnect all data drives when the machine is off, boot up, remove all drive / pool info, shutdown. Reconnect the data drives then boot up and make sure disk page is refreshed and import the pool as btrfs then reports it. Kind of over-kill but good to know.
The UI can definitely add a drive via pool resize function and can also change raid levels on the fly (although it may well take some time for this operation to complete); the raid options are limited by the number of drives in a pool of course. Again assuming no ‘out of kilter’ scenario. It’s a shame that your experience has been less than smooth but your report is good as it helps to re-emphasis what we need to concentrate on. I will definitely be looking more at this area going forward but must first make good on my promises to accomplish what I’m currently working on.
I currently suspect we have a kind of ‘dual personality’ in our pool import, pool current state logic and that is what I’m hoping to look at initially when I later see if I can help in that area. I’m not as yet as up on this side of Rockstor as I would like to be so time will tell.
I am quite confident that we are making good headway and although Rockstor’s development appears to happen in ‘fits and starts’ we are definitely moving in the right direction and at a more or less constant pace; some things just take longer that others. I have used FreeNAS in the past for a good few years and they do a great job with it, but with btrfs we face new challenges given it’s raid level flexibility (ie changing raid levels on the fly etc) and as such we just need to keep plugging away and make Rockstor all that we can.
Thanks for your considered responses here and I look forward to addressing the issues you raise as and when I can, a sentiment I’m sure all the other Rockstor developers share.